
{kind=link}
OpenAI’s newest mannequin, o3-mini, is revolutionizing coding duties with its superior reasoning, problem-solving, and code technology capabilities. It effectively handles advanced queries and integrates structured information, setting a brand new normal in AI functions. This text explores utilizing o3-mini and CrewAI to construct a Retrieval-Augmented Technology (RAG) analysis assistant agent that retrieves data from a number of PDFs and processes person queries intelligently. We’ll use CrewAI’s CrewDoclingSource, SerperDevTool, and OpenAI’s o3-mini to boost automation in analysis workflows.
Constructing the RAG Agent with o3-mini and CrewAI
With the overwhelming quantity of analysis being revealed, an automatic RAG-based assistant will help researchers rapidly discover related insights with out manually skimming by tons of of papers. The agent we’re going to construct will course of PDFs to extract key data and reply queries based mostly on the content material of the paperwork. If the required data isn’t discovered within the PDFs, it’s going to mechanically carry out an online search to supply related insights. This setup will be prolonged for extra superior duties, akin to summarizing a number of papers, detecting contradictory findings, or producing structured reviews.
On this hands-on information, we’ll construct a analysis agent that may undergo articles on DeepSeek-R1 and o3-mini, to reply queries we ask about these fashions. For constructing this analysis assistant agent, we’ll first undergo the stipulations and arrange the atmosphere. We’ll then import the required modules, set the API keys, and cargo the analysis paperwork. Then, we’ll go on to outline the AI mannequin and combine the net search instrument into it. Lastly, we’ll create he AI brokers, outline their duties, and assemble the crew. As soon as prepared, we’ll run the analysis assistant agent to seek out out if o3-mini is healthier and safer than DeepSeek-R1.
Stipulations
Earlier than diving into the implementation, let’s briefly go over what we have to get began. Having the proper setup ensures a clean growth course of and avoids pointless interruptions.
So, guarantee you might have:
- A working Python atmosphere (3.8 or above)
- API keys for OpenAI and Serper (Google Scholar API)
With these in place, we’re prepared to begin constructing!
Step 1: Set up Required Libraries
First, we have to set up the required libraries. These libraries present the inspiration for the doc processing, AI agent orchestration, and net search functionalities.
!pip set up crewai
!pip set up 'crewai[tools]'
!pip set up docling
These libraries play an important position in constructing an environment friendly AI-powered analysis assistant.
- CrewAI offers a sturdy framework for designing and managing AI brokers, permitting the definition of specialised roles and enabling environment friendly analysis automation. It additionally facilitates process delegation, guaranteeing clean collaboration between AI brokers.
- Moreover, CrewAI[tools] installs important instruments that improve AI brokers’ capabilities, enabling them to work together with APIs, carry out net searches, and course of information seamlessly.
- Docling makes a speciality of extracting structured information from analysis paperwork, making it excellent for processing PDFs, educational papers, and text-based recordsdata. On this mission, it’s used to extract key findings from arXiv analysis papers.
Step 2: Import Crucial Modules
import os
from crewai import LLM, Agent, Crew, Activity
from crewai_tools import SerperDevTool
from crewai.information.supply.crew_docling_source import CrewDoclingSource
On this,
- The os module securely manages environmental variables like API keys for clean integration.
- LLM powers the AI reasoning and response technology.
- The Agent defines specialised roles to deal with duties effectively.
- Crew manages a number of brokers, guaranteeing seamless collaboration.
- Activity assigns and tracks particular duties.
- SerperDevTool permits Google Scholar searches, bettering exterior reference retrieval.
- CrewDoclingSource integrates analysis paperwork, enabling structured information extraction and evaluation.
Step 3: Set API Keys
os.environ['OPENAI_API_KEY'] = 'your_openai_api_key'
os.environ['SERPER_API_KEY'] = 'your_serper_api_key'
Find out how to Get API Keys?
- OpenAI API Key: Enroll at OpenAI and get an API key.
- Serper API Key: Register at Serper.dev to acquire an API key.
These API keys permit entry to AI fashions and net search capabilities.
Step 4: Load Analysis Paperwork
On this step, we’ll load the analysis papers from arXiv, enabling our AI mannequin to extract insights from them. The chosen papers cowl key subjects:
- https://arxiv.org/pdf/2501.12948: Explores incentivizing reasoning capabilities in LLMs by reinforcement studying (DeepSeek-R1).
- https://arxiv.org/pdf/2501.18438: Compares the security of o3-mini and DeepSeek-R1.
- https://arxiv.org/pdf/2401.02954: Discusses scaling open-source language fashions with a long-term perspective.
content_source = CrewDoclingSource(
file_paths=[
"https://arxiv.org/pdf/2501.12948",
"https://arxiv.org/pdf/2501.18438",
"https://arxiv.org/pdf/2401.02954"
],
)
Step 5: Outline the AI Mannequin
Now we’ll outline the AI mannequin.
llm = LLM(mannequin="o3-mini", temperature=0)
- o3-mini: A robust AI mannequin for reasoning.
- temperature=0: Ensures deterministic outputs (similar reply for a similar question).
Step 6: Configure Net Search Device
To boost analysis capabilities, we combine an online search instrument that retrieves related educational papers when the required data shouldn’t be discovered within the supplied paperwork.
serper_tool = SerperDevTool(
search_url="https://google.serper.dev/scholar",
n_results=2 # Fetch high 2 outcomes
)
- search_url=”https://google.serper.dev/scholar”
This specifies the Google Scholar search API endpoint.It ensures that searches are carried out particularly in scholarly articles, analysis papers, and educational sources, relatively than normal net pages.
- n_results=2
This parameter limits the variety of search outcomes returned by the instrument, guaranteeing that solely essentially the most related data is retrieved. On this case, it’s set to fetch the highest two analysis papers from Google Scholar, prioritizing high-quality educational sources. By lowering the variety of outcomes, the assistant retains responses concise and environment friendly, avoiding pointless data overload whereas sustaining accuracy.
Step 7: Outline Embedding Mannequin for Doc Search
To effectively retrieve related data from paperwork, we use an embedding mannequin that converts textual content into numerical representations for similarity-based search.
embedder = {
"supplier": "openai",
"config": {
"mannequin": "text-embedding-ada-002",
"api_key": os.environ['OPENAI_API_KEY']
}
}
The embedder in CrewAI is used for changing textual content into numerical representations (embeddings), enabling environment friendly doc retrieval and semantic search. On this case, the embedding mannequin is supplied by OpenAI, particularly utilizing “text-embedding-ada-002”, a well-optimized mannequin for producing high-quality embeddings. The API key’s retrieved from the atmosphere variables to authenticate requests.
CrewAI helps a number of embedding suppliers, together with OpenAI and Gemini (Google’s AI fashions), permitting flexibility in selecting the very best mannequin based mostly on accuracy, efficiency, and price issues.
Step 8: Create the AI Brokers
Now we’ll create the 2 AI Brokers required for our researching process: the Doc Search Agent, and the Net Search Agent.
The Doc Search Agent is liable for retrieving solutions from the supplied analysis papers and paperwork. It acts as an knowledgeable in analyzing technical content material and extracting related insights. If the required data shouldn’t be discovered, it might probably delegate the question to the Net Search Agent for additional exploration. The allow_delegation=True setting permits this delegation course of.
doc_agent = Agent(
position="Doc Searcher",
aim="Discover solutions utilizing supplied paperwork. If unavailable, delegate to the Search Agent.",
backstory="You might be an knowledgeable in analyzing analysis papers and technical blogs to extract insights.",
verbose=True,
allow_delegation=True, # Permits delegation to the search agent
llm=llm,
)
The Net Search Agent, however, is designed to seek for lacking data on-line utilizing Google Scholar. It steps in solely when the Doc Search Agent fails to seek out a solution within the out there paperwork. In contrast to the Doc Search Agent, it can’t delegate duties additional (allow_delegation=False). It makes use of Serper (Google Scholar API) as a instrument to fetch related educational papers and guarantee correct responses.
search_agent = Agent(
position="Net Searcher",
aim="Seek for the lacking data on-line utilizing Google Scholar.",
backstory="When the analysis assistant can't discover a solution, you step in to fetch related information from the net.",
verbose=True,
allow_delegation=False,
instruments=[serper_tool],
llm=llm,
)
Step 9: Outline the Duties for the Brokers
Now we’ll create the 2 duties for the brokers.
The primary process entails answering a given query utilizing out there analysis papers and paperwork.
task1 = Activity(
description="Reply the next query utilizing the out there paperwork: {query}. "
"If the reply shouldn't be discovered, delegate the duty to the Net Search Agent.",
expected_output="A well-researched reply from the supplied paperwork.",
agent=doc_agent,
)
The subsequent process comes into play when the document-based search doesn’t yield a solution.
Activity 2: Carry out Net Search if Wanted
task2 = Activity(
description="If the document-based agent fails to seek out the reply, carry out an online search utilizing Google Scholar.",
expected_output="An internet-searched reply with related citations.",
agent=search_agent,
)
Step 10: Assemble the Crew
The Crew in CrewAI manages brokers to finish duties effectively by coordinating the Doc Search Agent and Net Search Agent. It first searches inside the uploaded paperwork and delegates to net search if wanted.
- knowledge_sources=[content_source] offers related paperwork,
- embedder=embedder permits semantic search, and
- verbose=True logs actions for higher monitoring, guaranteeing a clean workflow.
crew = Crew(
brokers=[doc_agent, search_agent],
duties=[task1, task2],
verbose=True,
knowledge_sources=[content_source],
embedder=embedder
)
Step 11: Run the Analysis Assistant
The preliminary question is directed to the doc to examine if the researcher agent can present a response. The query being requested is “O3-MINI vs DEEPSEEK-R1: Which one is safer?”
Instance Question 1:
query = "O3-MINI VS DEEPSEEK-R1: WHICH ONE IS SAFER?"
end result = crew.kickoff(inputs={"query": query})
print("Closing Reply:n", end result)
Response:
Right here, we will see that the ultimate reply is generated by the Doc Searcher, because it efficiently positioned the required data inside the supplied paperwork.
Instance Question 2:
Right here, the query “Which one is healthier, O3 Mini or DeepSeek R1?” shouldn’t be out there within the doc. The system will examine if the Doc Search Agent can discover a solution; if not, it’s going to delegate the duty to the Net Search Agent
query = "Which one is healthier O3 Mini or DeepSeek R1?"
end result = crew.kickoff(inputs={"query": query})
print("Closing Reply:n", end result)
Response:
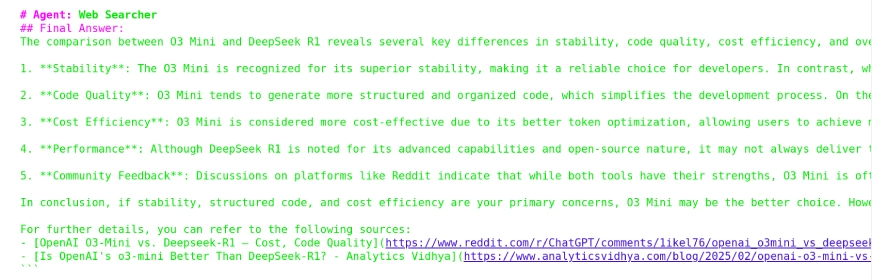
From the output, we observe that the response was generated utilizing the Net Searcher Agent for the reason that required data was not discovered by the Doc Researcher Agent. Moreover, it consists of the sources from which the reply was lastly retrieved.
Conclusion
On this mission, we efficiently constructed an AI-powered analysis assistant that effectively retrieves and analyzes data from analysis papers and the net. By utilizing CrewAI for agent coordination, Docling for doc processing, and Serper for scholarly search, we created a system able to answering advanced queries with structured insights.
The assistant first searches inside paperwork and seamlessly delegates to net search if wanted, guaranteeing correct responses. This strategy enhances analysis effectivity by automating data retrieval and evaluation. Moreover, by integrating the o3-mini analysis assistant with CrewAI’s CrewDoclingSource and SerperDevTool, we additional enhanced the system’s doc evaluation capabilities. With additional customization, this framework will be expanded to assist extra information sources, superior reasoning, and improved analysis workflows.
You may discover superb initiatives that includes OpenAI o3-mini in our free course – Getting Began with o3-mini!
Regularly Requested Questions
A. CrewAI is a framework that means that you can create and handle AI brokers with particular roles and duties. It permits collaboration between a number of AI brokers to automate advanced workflows.
A. CrewAI makes use of a structured strategy the place every agent has an outlined position and may delegate duties if wanted. A Crew object orchestrates these brokers to finish duties effectively.
A. CrewDoclingSource is a doc processing instrument in CrewAI that extracts structured information from analysis papers, PDFs, and text-based paperwork.
A. Serper API is a instrument that permits AI functions to carry out Google Search queries, together with searches on Google Scholar for educational papers.
A. Serper API presents each free and paid plans, with limitations on the variety of search requests within the free tier.
A. In contrast to normal Google Search, Serper API offers structured entry to go looking outcomes, permitting AI brokers to extract related analysis papers effectively.
A. Sure, it helps widespread analysis doc codecs, together with PDFs and text-based recordsdata.
Hello, I’m Janvi, a passionate information science fanatic presently working at Analytics Vidhya. My journey into the world of knowledge started with a deep curiosity about how we will extract significant insights from advanced datasets.