
{kind=link}
At Databricks, we use reinforcement studying (RL) to develop reasoning fashions for issues that our prospects face in addition to for our merchandise, such because the Databricks Assistant and AI/BI Genie. These duties embrace producing code, analyzing information, integrating organizational data, domain-specific analysis, and data extraction (IE) from paperwork. Duties like coding or data extraction typically have verifiable rewards — correctness could be checked instantly (e.g., passing exams, matching labels). This enables for reinforcement studying with no discovered reward mannequin, often known as RLVR (reinforcement studying with verifiable rewards). In different domains, a customized reward mannequin could also be required — which Databricks additionally helps. On this submit, we concentrate on the RLVR setting.
As an instance of the facility of RLVR, we utilized our coaching stack to a well-liked educational benchmark in information science known as BIRD. This benchmark research the duty of reworking a pure language question to a SQL code that runs on a database. This is a vital drawback for Databricks customers, enabling non-SQL specialists to speak to their information. Additionally it is a difficult activity the place even the very best proprietary LLMs don’t work nicely out of the field. Whereas BIRD neither totally captures the real-world complexity of this activity nor the full-breadth of actual merchandise like Databricks AI/BI Genie (Determine 1), its recognition permits us to measure the efficacy of RLVR for information science on a nicely understood benchmark.
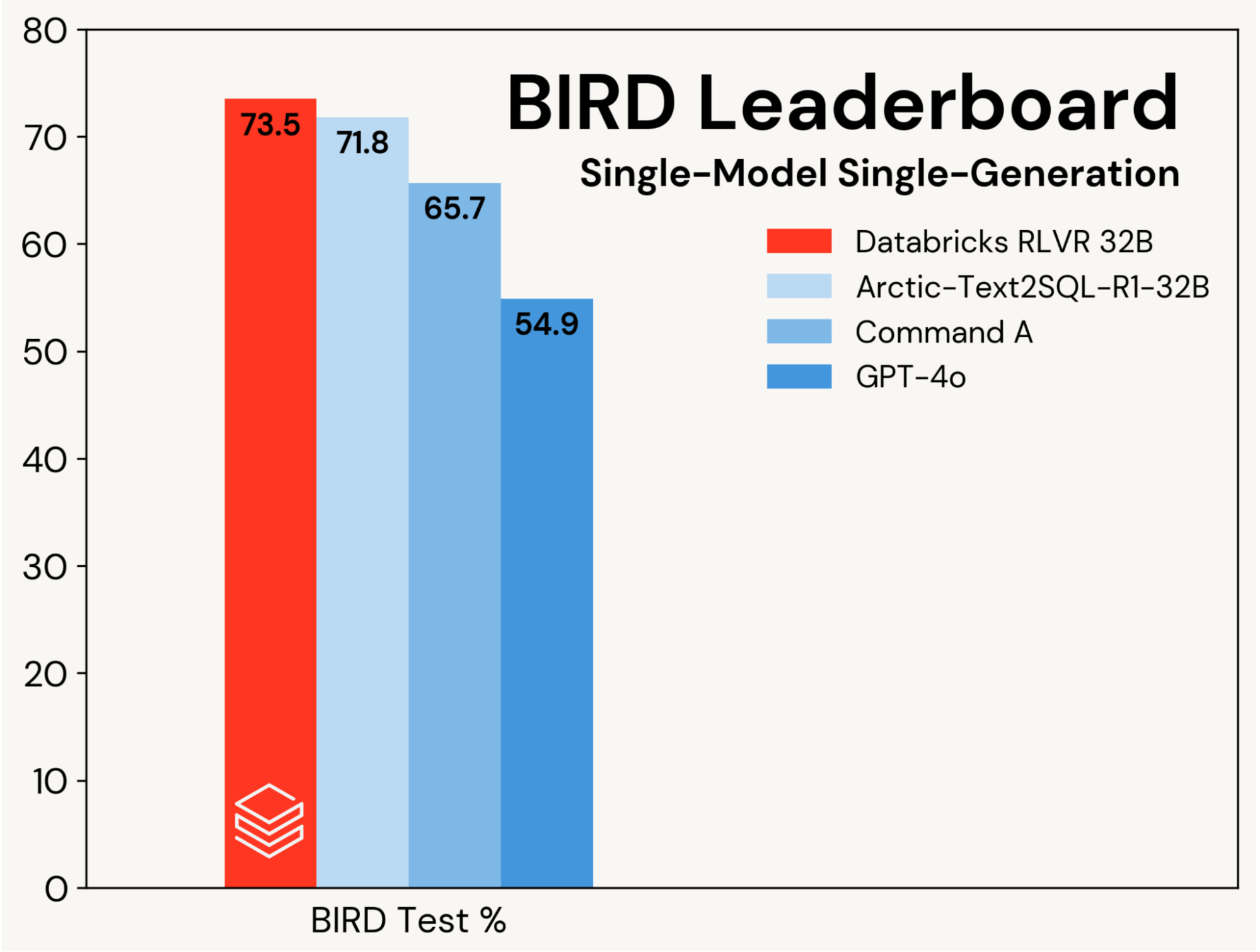
We concentrate on enhancing a base SQL coding mannequin utilizing RLVR, isolating these positive aspects from enhancements pushed by agentic designs. Progress is measured on the single-model, single‑technology observe of the BIRD leaderboard (i.e., no self‑consistency), which evaluates on a personal take a look at set.
We set a brand new state-of-the-art take a look at accuracy of 73.5% on this benchmark. We did so utilizing our normal RLVR stack and coaching solely on the BIRD coaching set. The earlier greatest rating on this observe was 71.8%[1], achieved by augmenting the BIRD coaching set with further information and utilizing a proprietary LLM (GPT-4o). Our rating is considerably higher than each the unique base mannequin and proprietary LLMs (see Determine 2). This end result showcases the simplicity and generality of RLVR: we reached this rating with off-the-shelf information and the usual RL elements we’re rolling out in Agent Bricks, and we did so on our first submission to BIRD. RLVR is a strong baseline that AI builders ought to take into account at any time when sufficient coaching information is out there.
We constructed our submission based mostly on the BIRD dev set. We discovered that Qwen 2.5 32B Coder Instruct was the very best place to begin. We fine-tuned this mannequin utilizing each Databricks TAO – an offline RL technique, and our RLVR stack. This strategy alongside cautious immediate and mannequin choice was ample to get us to the highest of the BIRD Benchmark. This result’s a public demonstration of the identical methods we’re utilizing to enhance standard Databricks merchandise like AI/BI Genie and Assistant and to assist our prospects construct brokers utilizing Agent Bricks.
Our outcomes spotlight the facility of RLVR and the efficacy of our coaching stack. Databricks prospects have additionally reported nice outcomes utilizing our stack of their reasoning domains. We predict this recipe is highly effective, composable, and extensively relevant to a variety of duties. If you’d prefer to preview RLVR on Databricks, contact us right here.
1See Desk 1 in https://arxiv.org/pdf/2505.20315
Authors: Alnur Ali, Ashutosh Baheti, Jonathan Chang, Ta-Chung Chi, Brandon Cui, Andrew Drozdov, Jonathan Frankle, Abhay Gupta, Pallavi Koppol, Sean Kulinski, Jonathan Li, Dipendra Kumar Misra, Jose Javier Gonzalez Ortiz, Krista Opsahl-Ong