
{kind=link}
Upgrading Apache Spark™ has by no means been straightforward. Each main model brings efficiency enhancements, bug fixes, and new options, however getting there’s painful. Most Spark customers know the drill. Workloads break, APIs change, and builders can spend weeks fixing jobs simply to catch up. This ends in new options, efficiency enhancements, and bug and safety fixes taking considerably longer to undertake.
At Databricks, we needed to take away this friction totally. The result’s Versionless Spark, a brand new manner of operating Spark that delivers steady upgrades, zero code modifications, and unmatched stability. Over the previous 18 months, since launching Serverless Notebooks and Jobs, Versionless Spark has mechanically upgraded greater than 2 billion Spark workloads throughout 25 Databricks Runtime releases, together with main Spark variations, with none person intervention.
On this weblog, we’ll share how we constructed versionless Spark, spotlight the outcomes we’ve seen, and present you the place to seek out extra particulars in our not too long ago revealed SIGMOD 2025 paper.
A brand new path ahead: Steady public API by way of versioned shopper
To make upgrades seamless and get Databricks customers time again, we wanted to have a secure, public Spark API in order that we may seamlessly replace the server. We achieved this with a secure, versioned shopper API, primarily based on Spark Join, that decouples the shopper from the Spark server, enabling Databricks to improve the server mechanically.
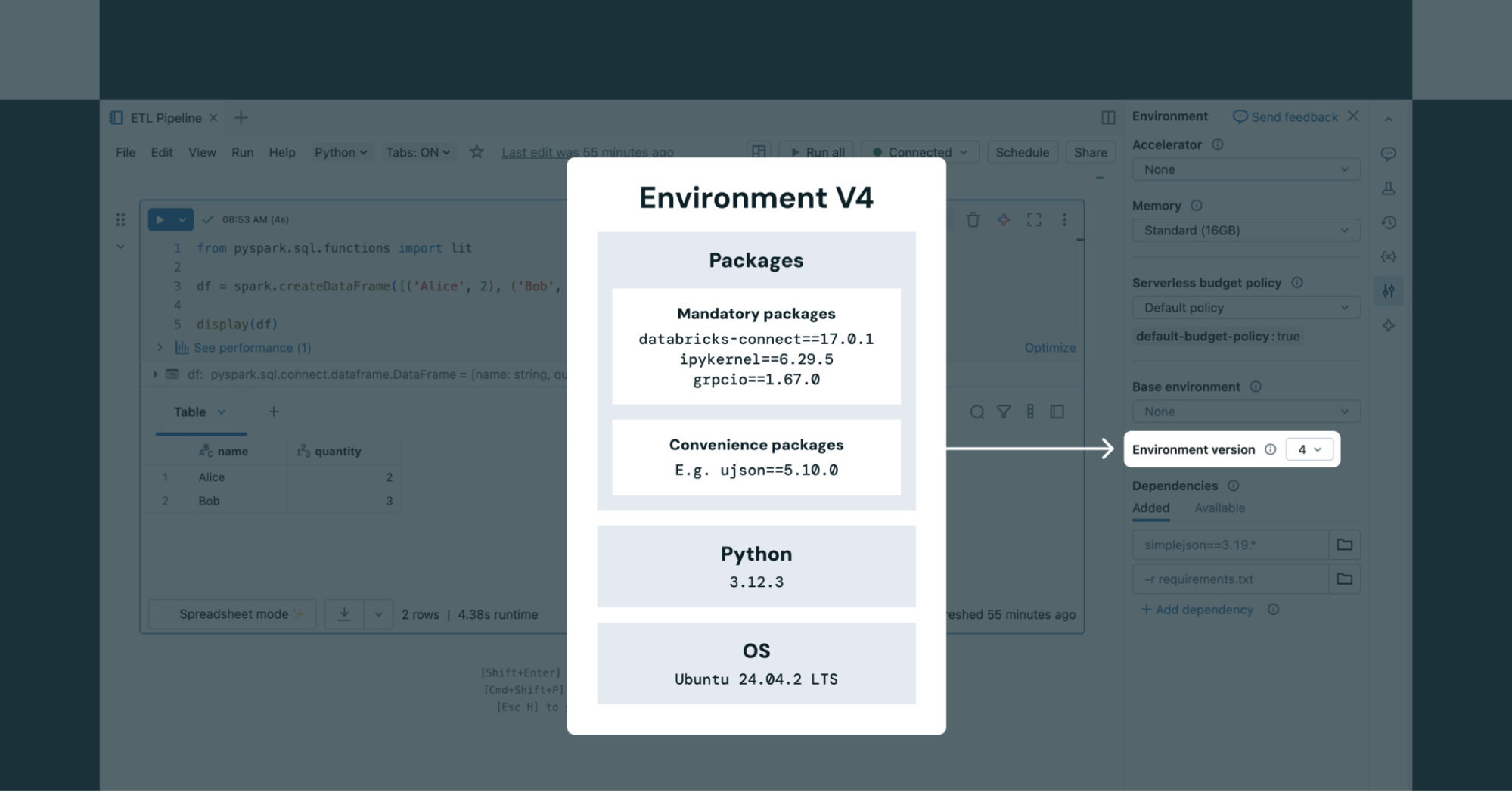
The Databricks atmosphere model serves as a base picture containing shopper packages similar to Spark Join, Python, and pip dependencies. Person code and extra packages run on prime of this atmosphere (e.g. Shopper app1) and communicates with our serverless Spark service. Databricks periodically releases new atmosphere variations, every with three years of help – just like DBR LTS. By default, new workloads use the most recent model, however customers can proceed operating on older, supported variations if they like.
When utilizing serverless Notebooks, customers can select from any supported atmosphere variations within the Setting panel of the pocket book (as proven in Determine 2). For serverless jobs, the atmosphere model is outlined by way of the Job API.
Computerized upgrades and AI-powered rollbacks
Offering our customers with frequent safety, reliability, and efficiency updates is important when operating automated workloads on Databricks. This should be finished mechanically and with out compromising stability, particularly for manufacturing pipelines. That is finished by way of our AI-powered Launch Stability System (RSS), which mixes an automatic workload’s distinctive fingerprint with run metadata, to detect regressed workloads on new server variations and mechanically revert subsequent runs to the earlier server model. The RSS incorporates a number of elements:
- Every workload has a workload fingerprint to establish repeated runs of the identical workload primarily based on a set of properties
- Historic runs retain metadata about earlier runs
- Pinning service retains monitor of workloads that behave in a different way on two totally different server variations
- ML fashions decide error classification, triage tickets, and detect anomalies inside the fleet
- Anomaly detection pipelines run throughout the fleet
- Launch well being experiences and alerts present real-time launch well being info to the Databricks engineering group

Computerized rollbacks be certain that workloads proceed operating efficiently after encountering regressions
When the RSS performs a rollback on an automatic job, the workload mechanically re-runs on its final recognized model, the place it beforehand succeeded. Let’s illustrate the RSS utilizing a real-world instance: A selected automated job ran on April ninth utilizing DBR model 16.1.2 and skilled an error. Historic runs indicated that the workload had succeeded for a number of consecutive days on 16.1.1. The ML mannequin discovered that the error was doubtless brought on by a bug. In consequence, a pinning entry was mechanically created within the pinning service. When the automated – on this case – retry of the workload began, it discovered the pinning service entry and the workload was re-run on 16.1.1 and succeeded. This resulted in an computerized triage course of whereby Databricks engineering received alerted, recognized the bug and issued a repair. Within the interim, subsequent runs of the workload stayed pinned on 16.1.1 till the bug repair was rolled out in 16.1.3 and the workload was finally launched to 16.1.3 (blue field) and continued to run efficiently.
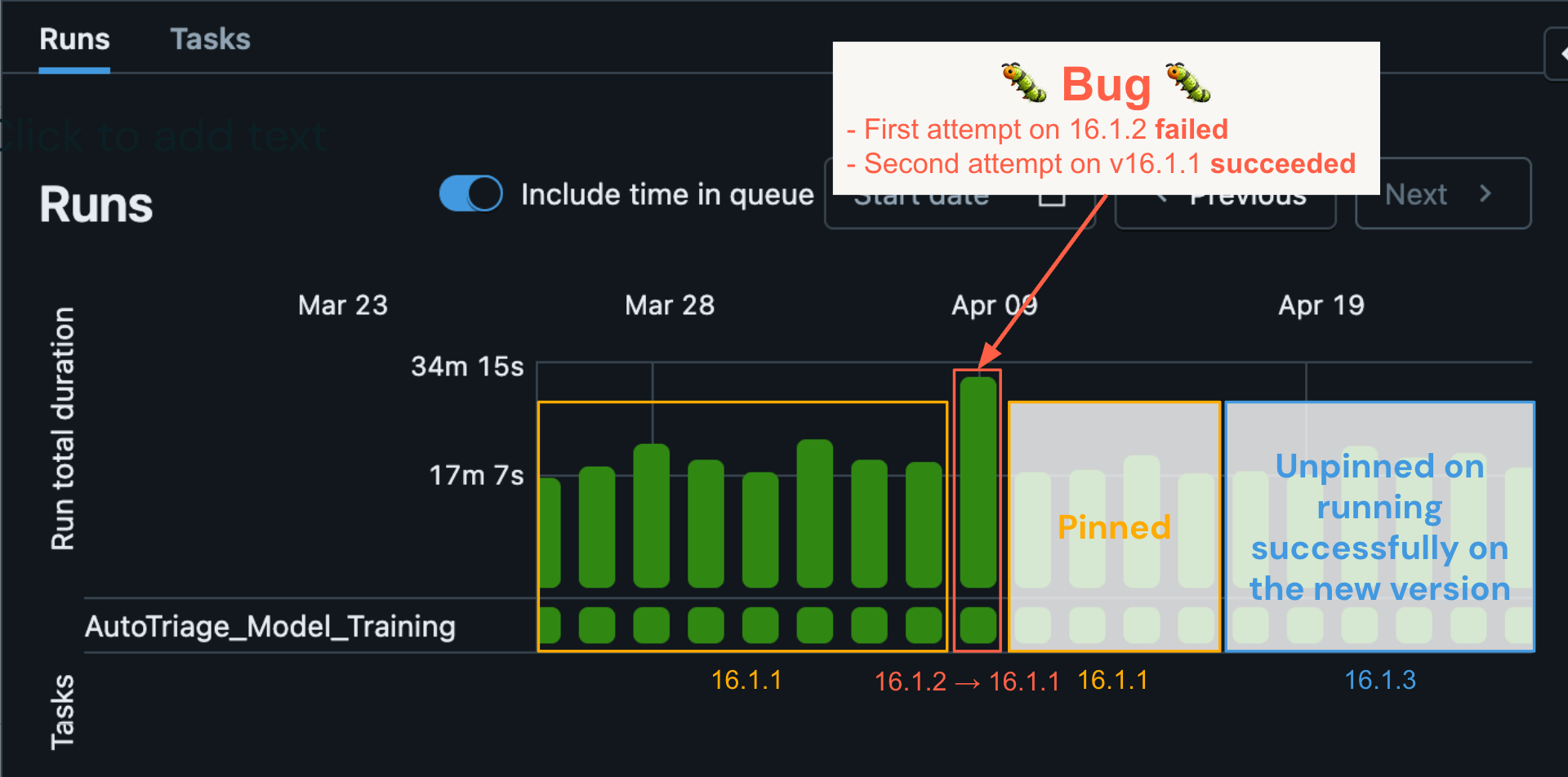
On this case, we have been capable of shortly detect and remediate a really delicate bug that solely affected a small variety of buyer workloads, with none impression to the client’s reliability. Examine that to the basic Spark improve mannequin, which depends on the person upgrading manually and often at a big delay. The person would carry out the improve, see their job begin to fail, after which could need to file a help ticket to resolve the difficulty. This may doubtless take for much longer to resolve – finally requiring extra buyer involvement and with worse reliability.
Conclusion
We now have used the Launch Stability System to improve greater than 2 billion jobs, from DBR 14 to DBR 17 – together with the transition to Spark 4 – whereas seamlessly delivering new options like collation, bloom filter be a part of optimization, and JDBC drivers. Of these, solely 0.000006% of jobs required an computerized rollback, and each rollback was remediated with a repair and efficiently upgraded to the most recent model inside a mean of 12 days. This achievement marks an {industry} first: upgrading billions of manufacturing Spark workloads mechanically, with zero code modifications from customers.
We now have made Spark upgrades utterly seamless by constructing a brand new structure that mixes atmosphere versioning, an auto-upgrading versionless server, and the Launch Stability System. This industry-first strategy has enabled Databricks to ship options and fixes to customers a lot sooner, with larger stability, permitting knowledge groups to focus extra on high-value enterprise outcomes somewhat than infrastructure upkeep.
We’re simply getting began on this journey and stay up for enhancing the UX additional.