
{kind=link}
Constructing a lightning-fast inference runtime is not nearly uncooked velocity—it is about fixing the correct issues for actual clients. At Databricks, our give attention to Information Intelligence means serving to clients flip their proprietary information into AI brokers that serve manufacturing workloads at huge scale. The inference engine sits on the coronary heart of this problem, orchestrating all the things from scheduling of requests to GPU kernel execution. Over the previous 12 months, we have constructed a customized inference engine that each out-performs open supply on our buyer workloads by 2x in some circumstances, but additionally fewer errors on widespread benchmarks.
With our give attention to information intelligence, constructing AI that may cause over your enterprise information, one of the crucial crucial workloads is serving fine-tuned fashions, that are both skilled by the shopper themselves or produced by Agent Bricks. Nevertheless, full parameter fine-tuned fashions don’t scale economically while you’re coping with fragmented requests throughout dozens of specialised use circumstances. Finetuning methods like Low Rank Adapters (LoRA) from (Hu et al, 2021) are fashionable approaches, as they’re reminiscence environment friendly to fine-tune, and may maintain prices manageable. Work from each our Mosaic AI Analysis group (Biderman et al, 2024) and the group (Schulman et al, 2025) have established that as a coaching method, PEFT has advantageous traits.
The problem we deal with right here, nonetheless, is the right way to make PEFT inference work at scale with out sacrificing efficiency or mannequin high quality.
Our World-Class Inference Runtime
Our Mannequin Serving product powers huge quantities of each real-time and batch information at Databricks, and we’ve discovered that delivering efficiency on buyer workloads means innovating past what is on the market in open-source. That’s why we’ve constructed a proprietary inference runtime and surrounding system that considerably outperforms the open supply alternate options by as much as 1.8x in some circumstances, even simply working base fashions.
Past the inference runtime itself, we have constructed a complete serving infrastructure that addresses the complete manufacturing stack: scalability, reliability, and fault tolerance. This concerned fixing complicated distributed methods challenges together with auto-scaling and cargo balancing, multi-region deployment, well being monitoring, clever request routing and queuing, distributed state administration, and enterprise-grade safety controls.
By means of this, our clients obtain not simply quick inference, however a production-ready system that handles real-world enterprise workloads with the reliability and scale they demand. Whereas we’ve made many inventions to attain this efficiency, from customized kernels to optimized runtimes, on this weblog we are going to give attention to simply a kind of instructions: quick serving of fine-tuned fashions with LoRA.
Listed below are the important thing ideas that guided our work:
- Assume framework-first, not kernel-first: The simplest optimizations emerge while you zoom out—understanding how scheduling, reminiscence, and quantization all work together throughout layers of the stack.
- Quantization should respect mannequin high quality: Leveraging FP8 can unlock huge speedups, however provided that paired with hybrid codecs and fused kernels that protect accuracy.
- Overlap is a throughput multiplier: Whether or not it’s overlapping kernels throughout streams or inside the identical stream utilizing SM throttling, maximizing GPU utilization is vital to maximizing throughput.
- CPU overheads are sometimes the silent bottleneck: Particularly for smaller fashions, inference efficiency is more and more gated by how briskly the CPU can put together and dispatch work to the GPU. It’s also necessary to reduce the idle GPU time between two decode steps by overlapping CPU execution with GPU execution.
Diving Deeper Into Quick Serving of Wonderful-Tuned Fashions
Amongst many parameter-efficient finetuning (PEFT) methods, LoRA has emerged as essentially the most extensively adopted PEFT technique as a result of its steadiness of high quality preservation and computational effectivity. Current analysis, together with the great “LoRA With out Remorse” examine by Schulman et al. and our personal examine “LoRA learns much less, forgets much less”, has validated key ideas for efficient LoRA utilization: apply LoRA to all layers (particularly MLP/MoE layers) and guarantee adequate adapter capability relative to dataset dimension. Nevertheless, reaching good compute effectivity at inference requires considerably extra than simply following these ideas. The theoretical FLOP benefits of LoRA do not routinely translate to real-world efficiency good points as a result of quite a few inference-time overheads.
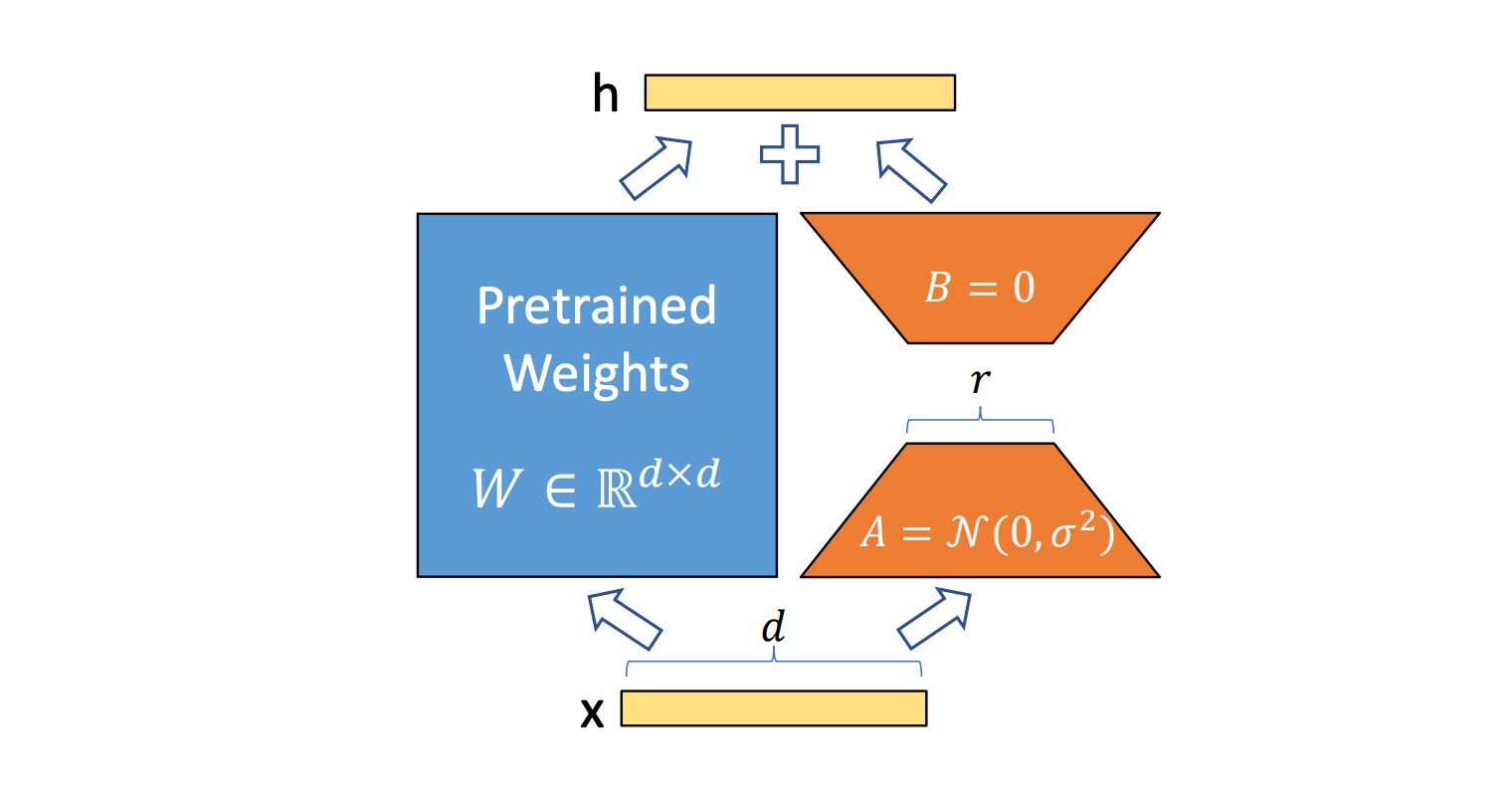
Furthermore, there’s a trade-off between the LoRA rank, which impacts the standard of the ultimate mannequin, and mannequin inference efficiency. Based mostly on our experiments, we discovered that for many clients, a better rank of 32 was essential to not degrade mannequin high quality throughout coaching. However this introduces strain on the inference system to optimize.
In manufacturing methods, servers should deal with a various variety of LoRA requests, which is a difficult drawback to optimize for efficiency. Current approaches have vital overheads when serving LoRA, generally slowing inference as much as 60% in life like eventualities.
Throughout inference, LoRA adapters are utilized as low-rank matrix multiplications for every of the person adapters and for every token in parallel with the bottom mannequin’s linear layers. These matrix multiplications sometimes contain smaller interior and outer dimensions than the scale noticed for fashions within the open supply group. As an illustration, widespread hidden dimensions for open supply fashions just like the Llama 3.1 8B mannequin are 8192 whereas the rank dimension will be as little as 8 for LoRA matrix multiplications. As such, the open supply group has not invested vital efforts in optimizing their kernels for these setups and in methods to maximise their {hardware} utilizations for these eventualities.
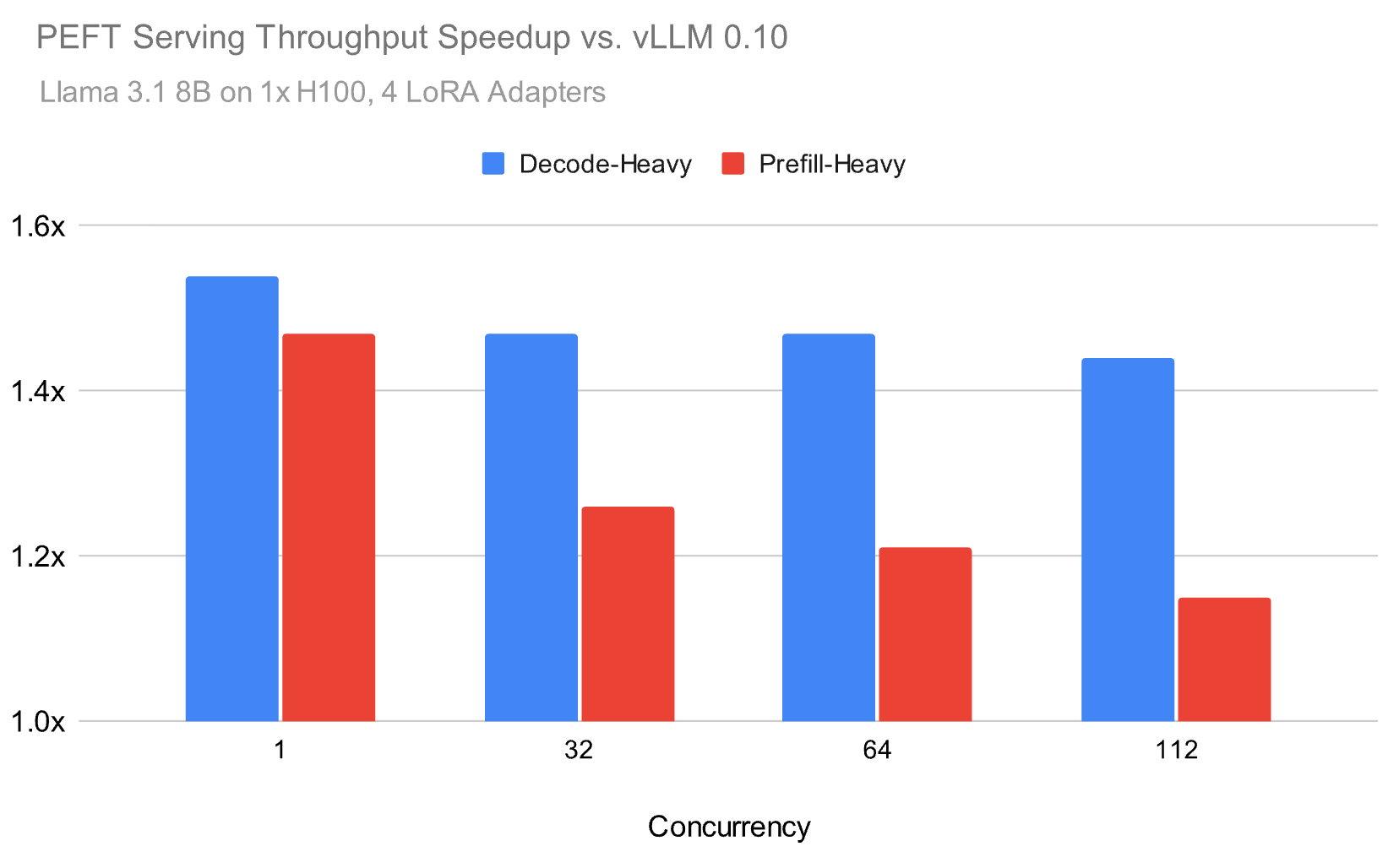
Over the previous 12 months, we developed our inference runtime to deal with these challenges, and as illustrated in Determine 1, we’re capable of obtain as much as 1.5x speed-up on serving LoRA in life like environments in comparison with the open supply. For instance, under we benchmark the Meta Llama 3.1 8B mannequin utilizing a Zipf distribution for the LoRA adapters with a mean of 4 adapters.
Our inference runtime achieves as much as 1.5x increased throughput than fashionable open supply alternate options for each prefill-heavy and decode-heavy workloads, with the efficiency hole narrowing however remaining substantial at increased hundreds. To be able to obtain these speed-ups, we centered on a number of parts that we describe on this weblog:
- High quality is simply as necessary as efficiency optimizations. We had been capable of maximize efficiency with customized Consideration and GEMM implementations, whereas preserving the mannequin high quality on key benchmarks.
- Partitioning GPU assets each throughout and inside multi-processors to higher deal with the small matrix multiplications in GEMM.
- Optimizing overlap of kernel executions to reduce bottlenecks within the system.
Quantization that Preserves Base Mannequin High quality
Quantization to reap the benefits of decrease precision {hardware} items is vital to efficiency, however can have an effect on high quality. Mannequin suppliers sometimes compress their fashions to fp8 throughout inference. Conversely, coaching is extra high quality delicate so fine-tuning of LoRA adapters is often carried out on fashions of their native precision (bf16). This discrepancy results in a problem for serving PEFT fashions, the place we should maximize the {hardware} assets whereas making certain that the standard of the bottom mannequin is preserved throughout inference to greatest mimic coaching settings.
To be able to retain high quality whereas optimizing efficiency, we developed some customized methods into our customized runtime. As seen within the desk under, our optimizations can retain the standard of the skilled adapters in comparison with serving in full precision. This is among the causes our runtime just isn’t solely sooner, but additionally has increased high quality on benchmarks in comparison with open supply runtimes.
|
PEFT Adapters Finetuned For Duties Listed Beneath PEFT Llama 3.1 8B instruct |
Full Precision (Acc. ± Std Dev.) % |
Databricks Inference Runtime |
vLLM 0.10 |
|
Humaneval |
74.02 ± 0.16 |
73.66 ± 0.39 |
71.88 ± 0.44 |
|
Math |
59.13 ± 0.14 |
59.13 ± 0.06 |
57.79 ± 0.36 |
Determine 4, With our customized adjustments, we’re capable of extra carefully retain the standard from a baseline the place the bottom mannequin is served in BF16. Word that each one measurements with vLLM 0.10 are made with their FP8 tensorwise weight, dynamic activation, and KV cache quantization enabled.
Rigorous High quality Validation
A key lesson from productionizing quantization is the necessity for rigorous high quality validation. At Databricks, we don’t simply benchmark fashions—we run detailed statistical comparisons between quantized and full-precision outputs to make sure that no perceptible degradation happens. Each optimization we deploy should meet this bar, whatever the efficiency acquire it supplies.
Quantization should even be handled as a framework-level concern, not an area optimization. By itself, quantization can introduce overheads or bottlenecks. However when coordinated with kernel fusion or in-kernel processing methods like warp specialization, these overheads will be hidden solely—yielding each high quality and efficiency. Within the part under, we dive into particular quantization methods that made this doable.
FP8 Weight Quantization
There are quite a few approaches to have the ability to quantize the weights of a mannequin, every with their very own set of tradeoffs. Some quantization methods are extra granular within the placement of their scale components whereas others are coarse-grained. These coarse-grained approaches lead to increased error however much less overhead throughout the quantization of the activation tensors.
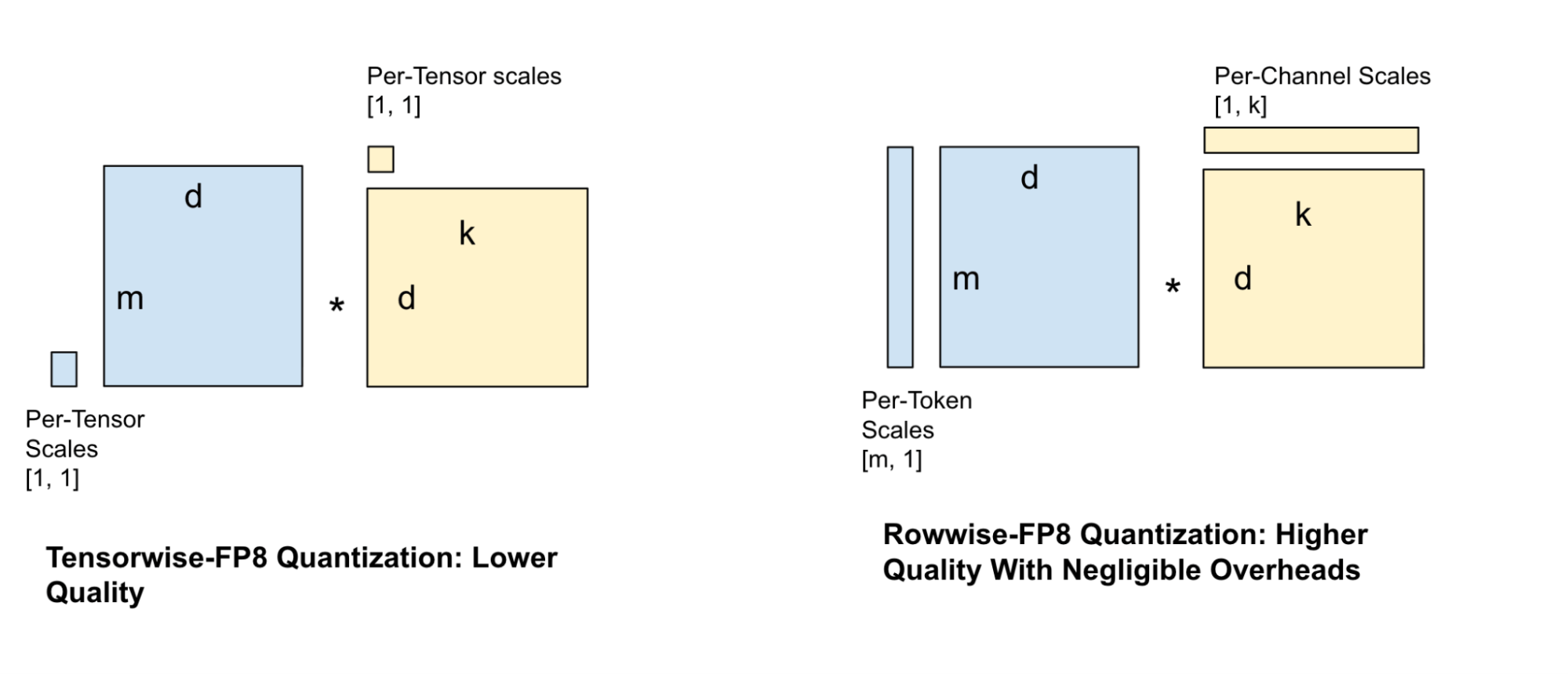
A preferred quantization method for serving fashions is tensor-wise FP8 quantization, the place one scale issue is assigned to your complete tensor. Nevertheless, this system is kind of lossy and ends in vital high quality discount, particularly for smaller fashions. This necessitates extra granular scale components, which led us to strive varied scale issue configurations for the weights and activations equivalent to per-channel and per-block scales. Balancing GEMM velocity towards high quality loss, we selected the rowwise scale issue configuration as proven in Determine 4.
To beat the efficiency overhead of calculating extra granular scale components for the activations, we carry out some crucial kernel fusions with previous bandwidth-bound operations to cover the overhead of the extra compute.
Hybrid Consideration
A core a part of Transformer-based inference is the Consideration operation, which may take as much as 50% of the full computation time for smaller fashions at lengthy context lengths. One widespread method to hurry decodes throughout inference is to cache the Key worth outputs from the prefill.
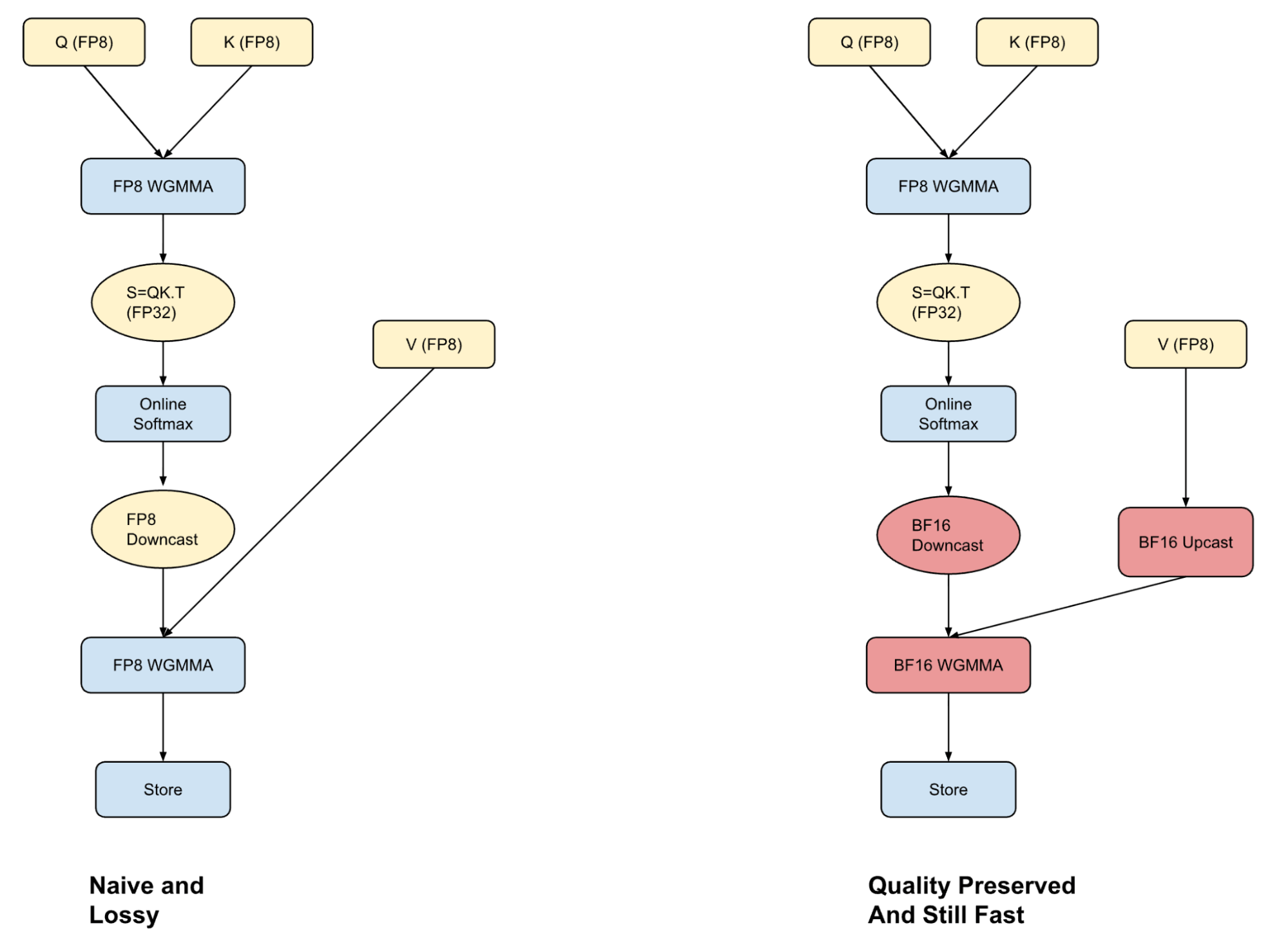
Storing KV caches in FP8 format can enhance throughput, however unlocking the complete profit requires an consideration kernel that may deal with FP8 inputs precisely and quick. Most frameworks both carry out consideration solely in FP8 (quick however lossy) or use BF16 (extra correct however slower as a result of upcasting). We’ve taken a center path with hybrid consideration—we mix the strengths of each codecs to attain a greater trade-off between efficiency and high quality.
We converged to this format after discovering that the quantization error within the FP8 consideration computation comes from downcasting the softmax computation to a decrease bit illustration. By performing the primary a part of the computation in FP8 and by exploiting warp specialization methods on Hopper GPUs, we will overlap the upcast of the V-vector with the Q-Ok computation. This then permits us to run the P-V computation in BF16 with none efficiency penalty. Whereas that is nonetheless slower than doing all computation in FP8, extra importantly the hybrid method doesn’t degrade the mannequin high quality.
Our work builds on comparable approaches steered in Academia, SageAttention and SageAttention2 by Zhang et al., in addition to in a weblog from CharacterAI.
Put up-RoPE Fused Quick Hadamard Transforms
Recall that the question and key for a given token are computed from its embedding x firstly of the eye module as:
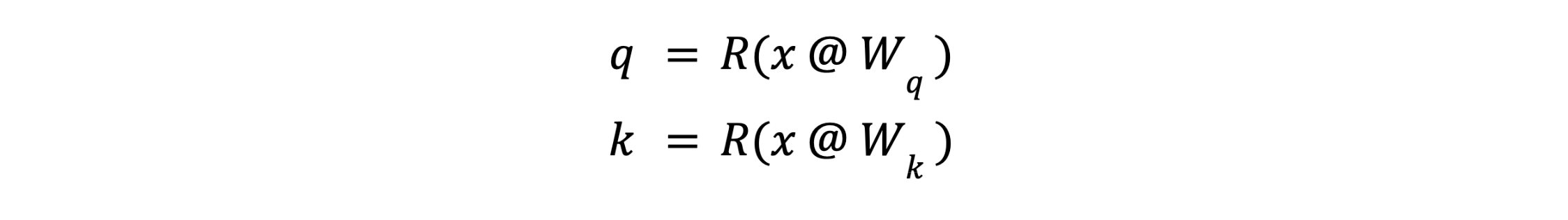
The place R() is the RoPE embedding operator. After RoPE, it isn’t essential to protect the precise values of q or ok–it’s only essential to protect the interior merchandise q.T @ ok for all queries q and keys ok. This lets us apply a linear rework U to q and ok:
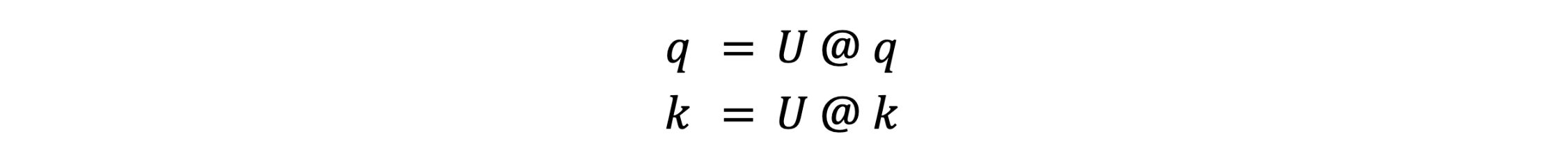
such that U.T @ U = I, the id matrix. This makes U cancel out throughout the consideration computation:
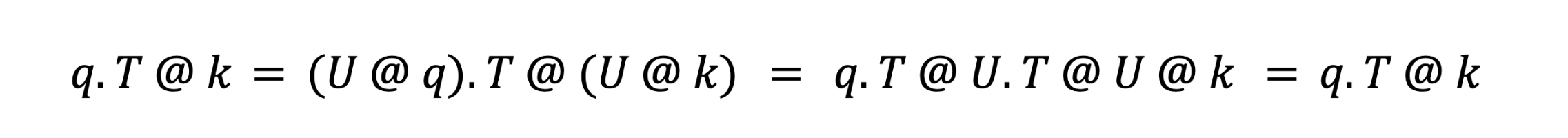
This lets us optimize the q and ok vectors for quantizability with out (mathematically) altering the eye computation. The precise rework we use is the Quick Hadamard Rework (FHT), which lets us unfold variance throughout D channels in O(log2(D)) operations. This spreading of variance eliminates outliers and permits smaller FP8 scales–you may consider this having the ability to “zoom in” for higher decision. This work builds on comparable approaches steered in Academia, FlashAttention3 by Dao et al,, and QuaRot by Ashkboos et al.
To keep away from overhead, we wrote a kernel that fuses RoPE, the FHT, quantization, and appending to the KV cache.
Overlapping Kernels To Decrease PEFT Overheads
Throughout inference with LoRA, the adapter rank represents one of many dimensions of the matrix multiplication. For the reason that rank sometimes will be small (e.g. 8 or 32), this results in matrix-multiplications with skewed dimensions, leading to further overhead throughout inference (Determine 1).
As such, impressed from the Nanoflow work by Zhu et al., now we have been exploring varied methods to cover this overhead by overlapping LoRA kernels with the bottom mannequin and between themselves.
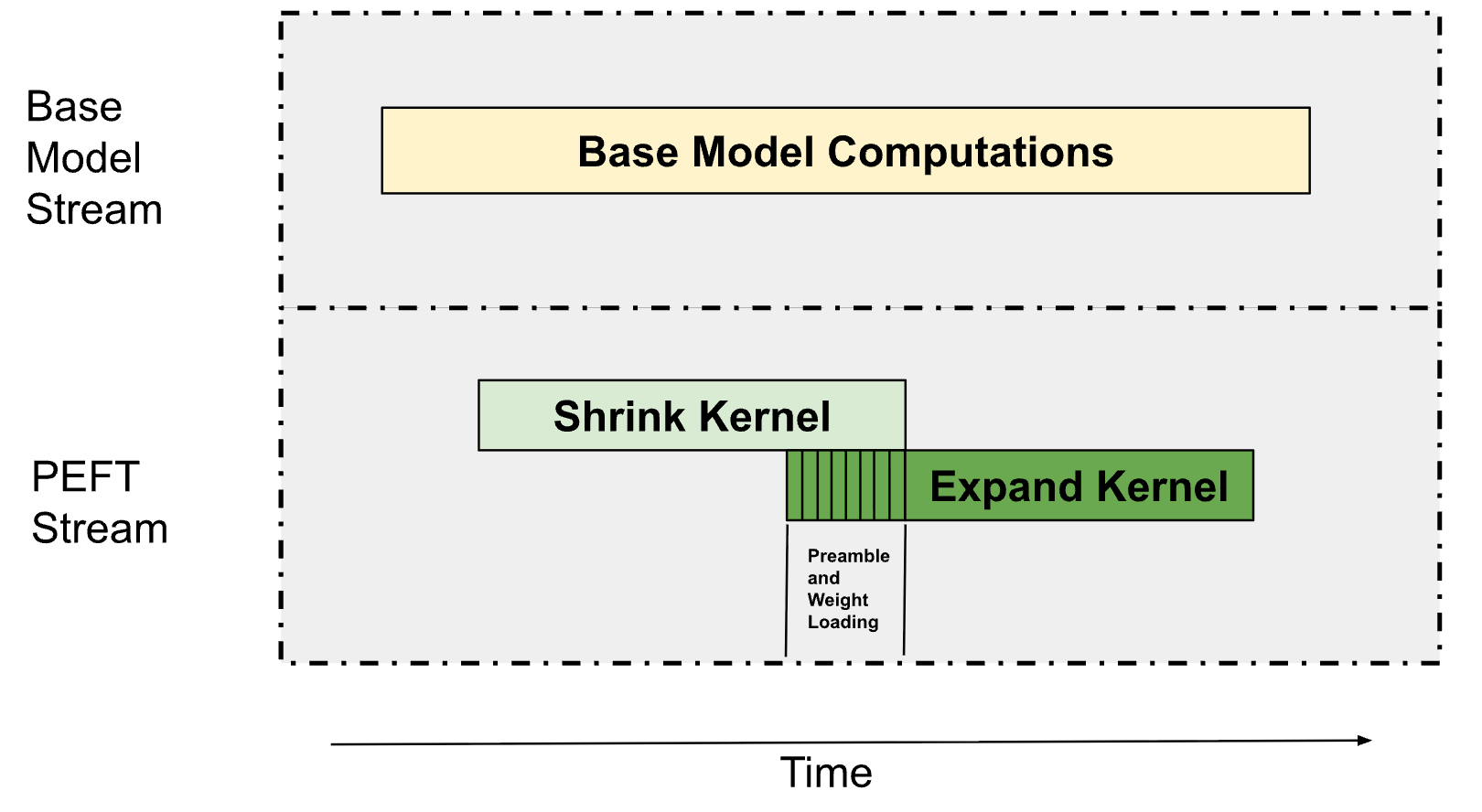
As described in Determine 1, LoRA inferencing consists of two predominant kernels, a down-projection kernel (outlined because the “Shrink” kernel) and an up-projection kernel (outlined because the “Develop” kernel). These are primarily Grouped GEMMs (the place every GEMM operates on a unique adapter) since we sometimes serve a number of LoRA adapters concurrently. This permits us to overlap these Grouped GEMMs with the bottom mannequin’s computations and the Shrink, Develop kernels between one another as described under in Determine 6.
Parallel Streams with Multiprocessor Partitioning
At a floor stage, it’s trivially doable to overlap kernel executions that rely on completely different information by launching them in separate streams. This method inherently depends on the compute work distributor to schedule the blocks of the completely different kernel executions. Nevertheless, this solely works when there’s adequate unused compute capability. For bigger workloads that may usually saturate the GPU, we’d like a extra refined method.
Going past this, we realized that we will partition the variety of Streaming Multiprocessors (SMs) required by bandwidth certain kernels with out considerably affecting their efficiency. In most eventualities, now we have discovered that bandwidth-bound kernels don’t want all of the doable SMs so as to have the ability to entry the complete reminiscence bandwidth on the GPU. As such, this enables us to limit the variety of SMs utilized by these kernels after which use the remaining multi-processors to carry out different computations.
For PEFT, we run two streams, one for the bottom mannequin and one for the PEFT path. The bottom mannequin receives as excessive as 75% of the SMs on the GPU and the remaining go to the PEFT path, With this partitioning, now we have discovered that the bottom mannequin path doesn’t decelerate considerably whereas the PEFT path is ready to run within the background permitting us to cover the overhead from PEFT usually.
Similar Stream with Dependent Launches
Whereas kernel executions that rely on completely different information will be simply overlapped throughout completely different streams, dependent kernel executions in the identical stream are more durable to overlap since every kernel should anticipate the earlier one to finish. To handle this, we use Programmatic Dependent Launch (PDL), which permits us to pre-fetch the weights for the subsequent kernel whereas the present one continues to be executing.
PDL is a complicated CUDA runtime function that allows launching a dependent kernel earlier than the first kernel in the identical stream has completed executing. That is illustrated in Determine 8 under.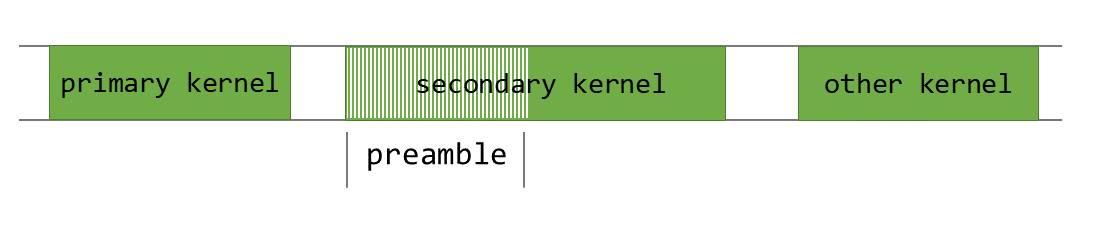
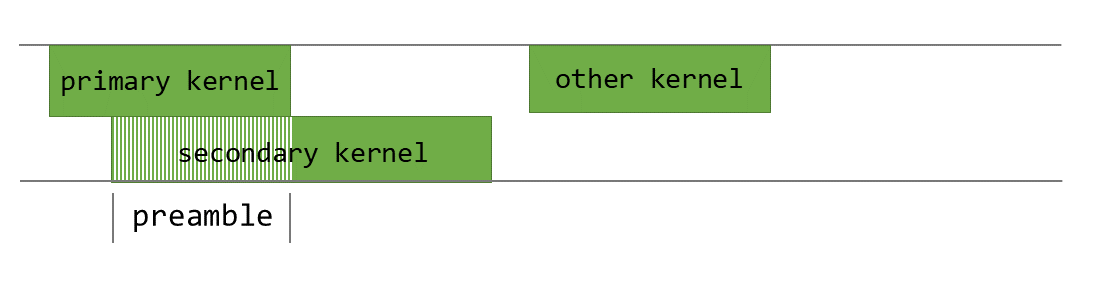
For our PEFT kernels, we use PDL to overlap the shrink and increase operations. Whereas the shrink kernel executes, we pre-fetch the weights wanted for the Develop kernel into shared reminiscence and the L2 cache. We throttle the shared reminiscence and the register assets of the Shrink kernel to make sure that there are sufficient assets for the Develop kernel to run. This permits the Develop kernel to start weight processing whereas the Shrink kernel continues to be finishing its computation. As soon as the Shrink kernel is full, the Develop kernel hundreds the activations and begins performing the matrix multiplication computations.
Conclusion
Permitting our clients to leverage their information to drive distinctive insights is a core a part of our technique right here at Databricks. A key a part of that is having the ability to efficiently serve LoRA requests within the inference runtime. The methods we’ve shared —from quantization codecs to kernel fusion, from SM-level scheduling to CPU-GPU overlap, all stem from this framework-first philosophy. Every optimization was validated towards rigorous high quality benchmarks to make sure we by no means traded accuracy for velocity.
As we glance forward, we’re excited to push additional with extra megakernel methods and smarter scheduling mechanisms.
To get began with LLM inference, check out Databricks Mannequin Serving on our platform.
Authors: Nihal Potdar, Megha Agarwal, Hanlin Tang, Asfandyar Qureshi, Qi Zheng, Daya Khudia