
{kind=link}
Amazon SageMaker Unified Studio serves as a collaborative workspace the place knowledge engineers and scientists can work collectively on end-to-end knowledge and machine studying (ML) workflows. SageMaker Unified Studio focuses on orchestrating advanced knowledge workflows throughout a number of AWS companies by means of its integration with Amazon Managed Workflows for Apache Airflow (Amazon MWAA). Challenge house owners can create shared environments the place workforce members collectively develop and deploy workflows, whereas sustaining oversight of pipeline execution. This unified method makes certain knowledge pipelines run constantly and effectively, with clear visibility into the complete course of, making it seamless for groups to collaborate on subtle knowledge and ML tasks.
This submit explores tips on how to construct and handle a complete extract, remodel, and cargo (ETL) pipeline utilizing SageMaker Unified Studio workflows by means of a code-based method. We display tips on how to use a single, built-in interface to deal with all elements of knowledge processing, from preparation to orchestration, through the use of AWS companies together with Amazon EMR, AWS Glue, Amazon Redshift, and Amazon MWAA. This resolution streamlines the info pipeline by means of a single UI.
Instance use case: Buyer habits evaluation for an ecommerce platform
Let’s contemplate a real-world state of affairs: An e-commerce firm desires to investigate buyer transactions knowledge to create a buyer abstract report. They’ve knowledge coming from a number of sources:
- Buyer profile knowledge saved in CSV recordsdata
- Transaction historical past in JSON format
- Web site clickstream knowledge in semi-structured log recordsdata
The corporate desires to do the next:
- Extract knowledge from these sources
- Clear and remodel the info
- Carry out high quality checks
- Load the processed knowledge into an information warehouse
- Schedule this pipeline to run each day
Answer overview
The next diagram illustrates the structure that you simply implement on this submit.
The workflow consists of the next steps:
- Set up an information repository by creating an Amazon Easy Storage Service (Amazon S3) bucket with an organized folder construction for buyer knowledge, transaction historical past, and clickstream logs, and configure entry insurance policies for seamless integration with SageMaker Unified Studio.
- Extract knowledge from the S3 bucket utilizing AWS Glue jobs.
- Use AWS Glue and Amazon EMR Serverless to wash and remodel the info.
- Implement knowledge high quality validation utilizing AWS Glue Information High quality.
- Load the processed knowledge into Amazon Redshift Serverless.
- Create and handle the workflow surroundings utilizing SageMaker Unified Studio with Identification Middle–primarily based domains.
Observe: Amazon SageMaker Unified Studio helps two area configuration fashions: IAM Identification Middle (IdC)–primarily based domains and IAM position–primarily based domains. Whereas IAM-based domains allow role-driven entry administration and visible workflows, this submit particularly focuses on Identification Middle–primarily based domains, the place customers authenticate through IdC and tasks entry knowledge and assets utilizing challenge roles and identity-based authorization.
Stipulations
Earlier than starting, guarantee you’ve the next assets:
Configure Amazon SageMaker Unified Studio area
This resolution requires SageMaker Unified Studio area within the us-east-1 AWS Area. Though SageMaker Unified Studio is out there in a number of Areas, this submit makes use of us-east-1 for consistency. For a whole record of supported Areas, check with Areas the place Amazon SageMaker Unified Studio is supported.
Full the next steps to configure your area:
- Check in to the AWS Administration Console, navigate to Amazon SageMaker, and open the Domains part from the left navigation pane.
- On the SageMaker console, select Create area, then select Fast setup.
- If the message “No VPC has been particularly arrange to be used with Amazon SageMaker Unified Studio” seems, choose Create VPC. The method redirects to an AWS CloudFormation stack. Depart all settings at their default values and choose Create stack.
- Below Fast setup settings, for Title, enter a site title (for instance, etl-ecommerce-blog-demo). Assessment the chosen configurations.
- Select Proceed to proceed.
- On the Create IAM Identification Middle person web page, create an SSO person (account with IAM Identification Middle) or choose an current SSO person to log in to the Amazon SageMaker Unified Studio. The SSO chosen right here is used because the administrator within the Amazon SageMaker Unified Studio.
- Select Create area.
For detailed directions, see Create a SageMaker area and Onboarding knowledge in Amazon SageMaker Unified Studio.
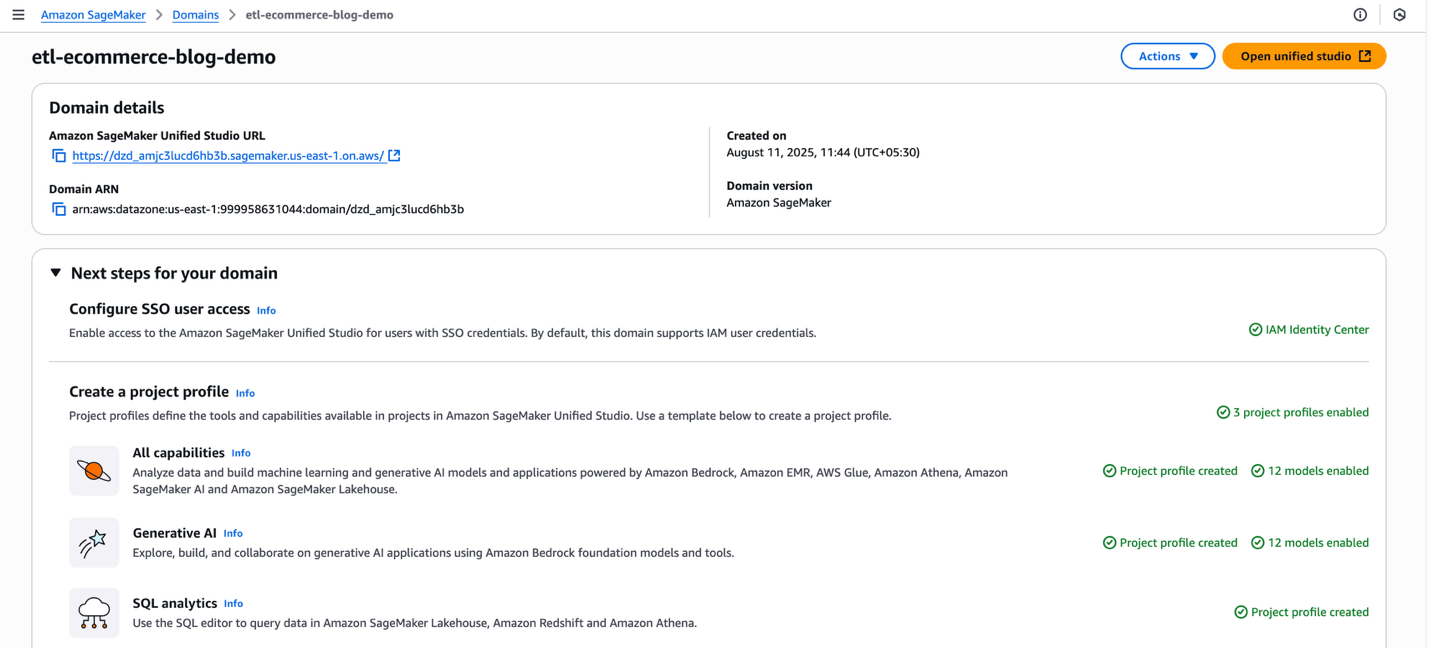
After you’ve created a site, popup will seem with the message: “Your area has been created! Now you can log in to Amazon SageMaker Unified Studio”. You possibly can shut the popup for now.
Create a challenge
On this part, we create a challenge to function a collaborative workspace for groups to work on enterprise use circumstances. Full the next steps:
- Select Open Unified Studio and sign up along with your SSO credentials utilizing the Check in with SSO possibility.
- Select Create challenge.
- Title the challenge (for instance,
ETL-Pipeline-Demo) and create it utilizing the All capabilities challenge profile. - Select Proceed.
- Hold the default values for the configuration parameters and select Proceed.
- Select Create challenge.
Challenge creation may take a couple of minutes. After the challenge is created, the surroundings shall be configured for knowledge entry and processing.
Combine S3 bucket with SageMaker Unified Studio
To allow exterior knowledge processing inside SageMaker Unified Studio, configure integration with an S3 bucket. This part walks by means of the steps to arrange the S3 bucket, configure permissions, and combine it with the challenge.
Create and configure S3 bucket
Full the next steps to create your bucket:
- In a brand new browser tab, open the AWS Administration Console and seek for S3.
- On the Amazon S3 console, select Create Bucket .
- Create a bucket named
ecommerce-raw-layer-bucket-demo-. For detailed directions, see create a general-purpose Amazon S3 bucket for storage.-us-east-1 - Create the next folder construction within the bucket. For detailed directions, see Making a folder:
uncooked/clients/uncooked/transactions/uncooked/clickstream/processed/analytics/
Add pattern knowledge
On this part, we add pattern ecommerce knowledge that represents a typical enterprise state of affairs the place buyer habits, transaction historical past, and web site interactions must be analyzed collectively.
The uncooked/clients/clients.csv file comprises buyer profile data, together with registration particulars. This structured knowledge shall be processed first to ascertain the client dimension for our analytics.
The uncooked/transactions/transactions.json file comprises buy transactions with nested product arrays. This semi-structured knowledge shall be flattened and joined with buyer knowledge to investigate buying patterns and buyer lifetime worth.
The uncooked/clickstream/clickstream.csv file captures person web site interactions and habits patterns. This time-series knowledge shall be processed to know buyer journey and conversion funnel analytics.
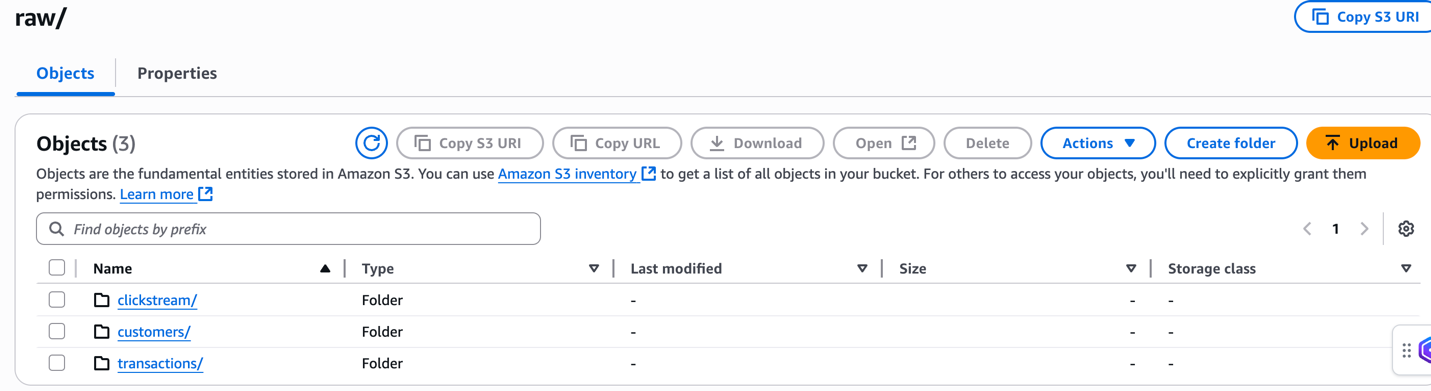
For detailed directions on importing recordsdata to Amazon S3, check with the Importing objects.
Configure CORS coverage
To permit entry from the SageMaker Unified Studio area portal, replace the Cross-Origin Useful resource Sharing (CORS) configuration of the bucket:
- On the bucket’s Permissions tab, select Edit below Cross-origin useful resource sharing (CORS).

- Enter the next CORS coverage and exchange
domainUrlwith the SageMaker Unified Studio area URL (for instance,https://). The URL may be discovered on the high of the area particulars web page on the SageMaker Unified Studio console..sagemaker.us-east-1.on.aws
For detailed data, see Including Amazon S3 knowledge and achieve entry utilizing the challenge position.
Grant Amazon S3 entry to SageMaker challenge position
To allow SageMaker Unified Studio to entry the exterior Amazon S3 location, the corresponding AWS Identification and Entry Administration (IAM) challenge position have to be up to date with the required permissions. Full the next steps:
- On the IAM console, select Roles within the navigation pane.
- Seek for the challenge position utilizing the final phase of the challenge position Amazon Useful resource Title (ARN). This data is situated on the Challenge overview web page in SageMaker Unified Studio (for instance,
datazone_usr_role_1a2b3c45de6789_abcd1efghij2kl).
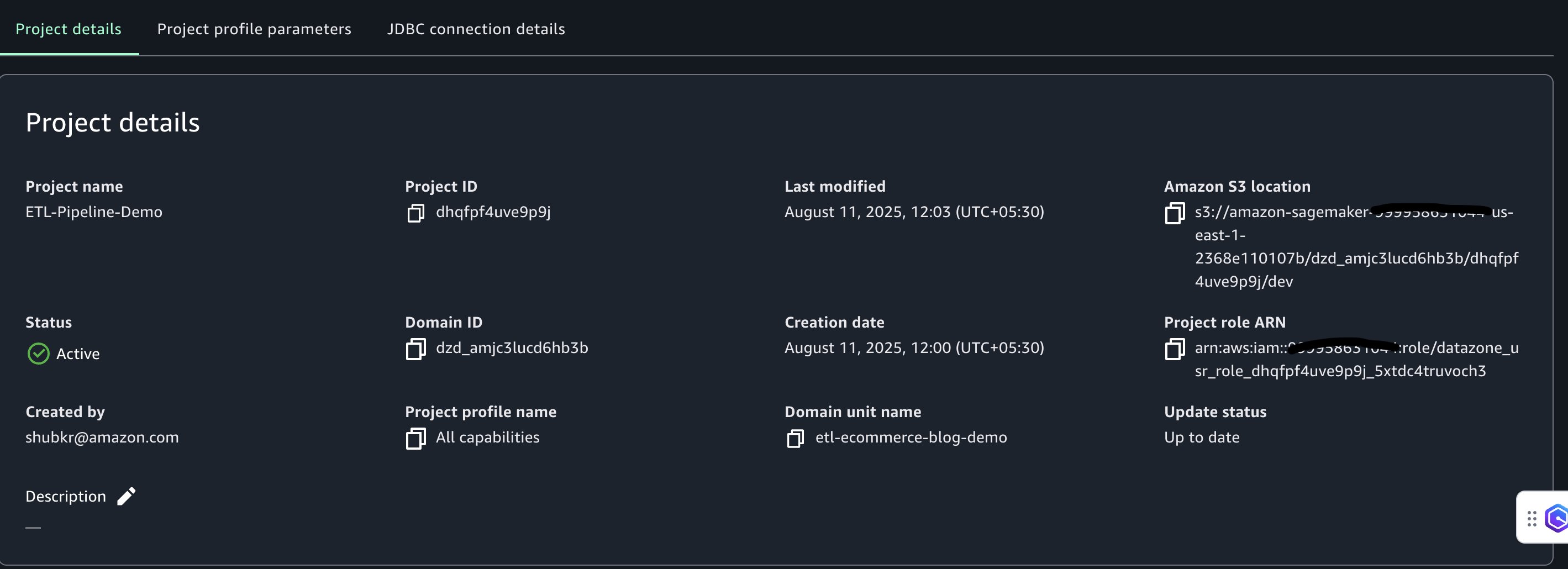
- Select the challenge position to open the position particulars web page.
- On the Permissions tab, select Add permissions, then select Create inline coverage.
- Use the JSON editor to create a coverage that grants the challenge position entry to the Amazon S3 location
- Within the JSON coverage under, exchange the placeholder values along with your precise surroundings particulars:
- Substitute
ecommerce-raw-layer) - Substitute
us-east-1) - Substitute
- Substitute
- Paste the up to date JSON coverage into the JSON editor.
- Select Subsequent.
- Enter a reputation for the coverage (for instance,
etl-rawlayer-access), then select Create coverage. - Select Add permissions once more, then select Create inline coverage.
- Within the JSON editor, create a second coverage to handle S3 Entry Grants:Substitute
ecommerce-raw-layer) and paste this JSON coverage. - Select Subsequent.
- Enter a reputation for the coverage (for instance,
s3-access-grants-policy), then select Create coverage.
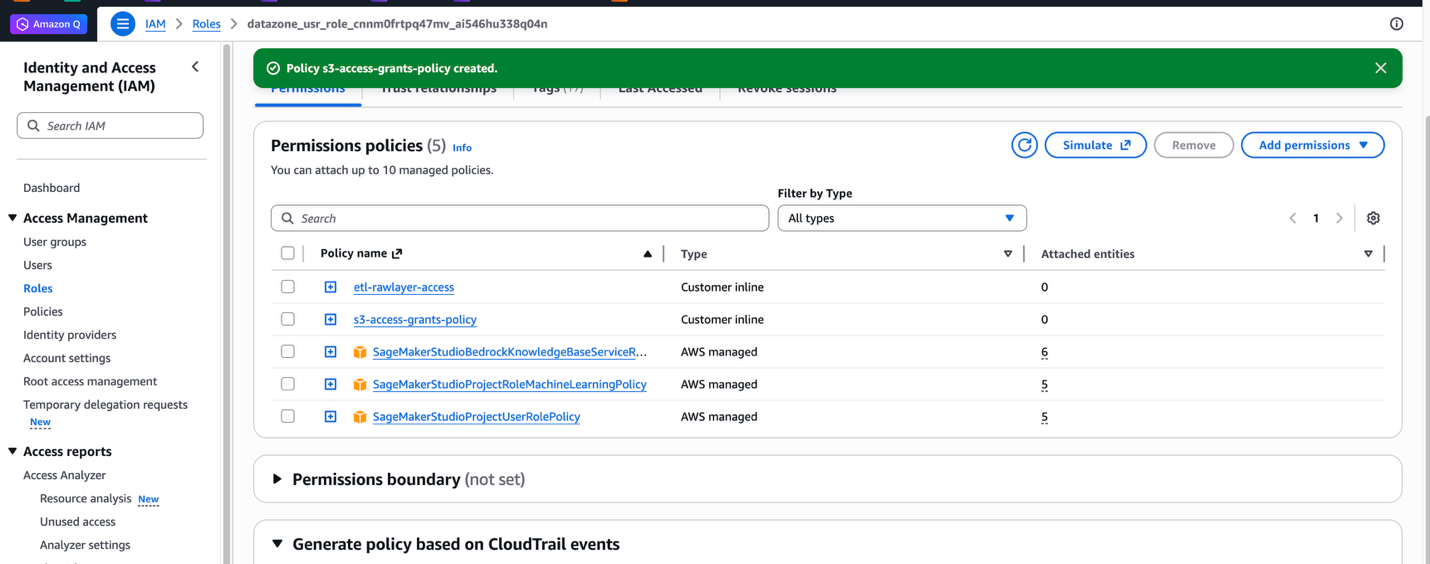
For detailed details about S3 Entry Grants, see Including Amazon S3 knowledge.
Add S3 bucket to challenge
After you add insurance policies to the challenge position for entry to the Amazon S3 assets, full the next steps to combine the S3 bucket with the SageMaker Unified Studio challenge:
- In SageMaker Unified Studio, open the challenge you created below Your tasks.
- Select Information within the navigation pane.
- Choose Add after which Add S3 location.
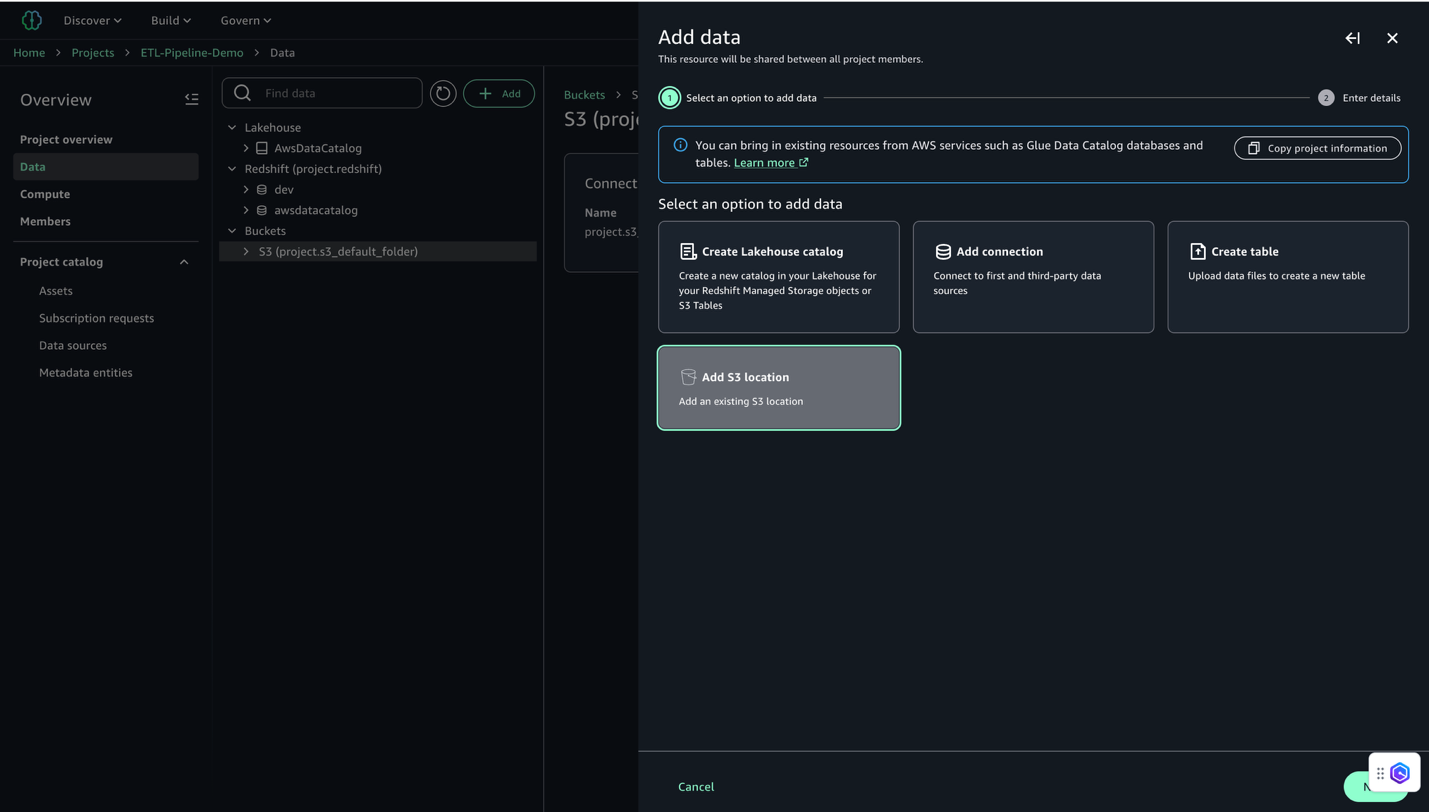
- Configure the S3 location:
- For Title, enter a descriptive title (for instance,
E-commerce_Raw_Data). - For S3 URI, enter your bucket URI (for instance,
s3://ecommerce-raw-layer-bucket-demo-).-us-east-1/ - For AWS Area, enter your Area (for this instance,
us-east-1). - Depart Entry position ARN clean.
- Click on Add S3 Location
- For Title, enter a descriptive title (for instance,
- Await the mixing to finish.
- Confirm the S3 location seems in your challenge’s knowledge catalog (on the Challenge overview web page, on the Information tab, find the Buckets pane to view the buckets and folders).
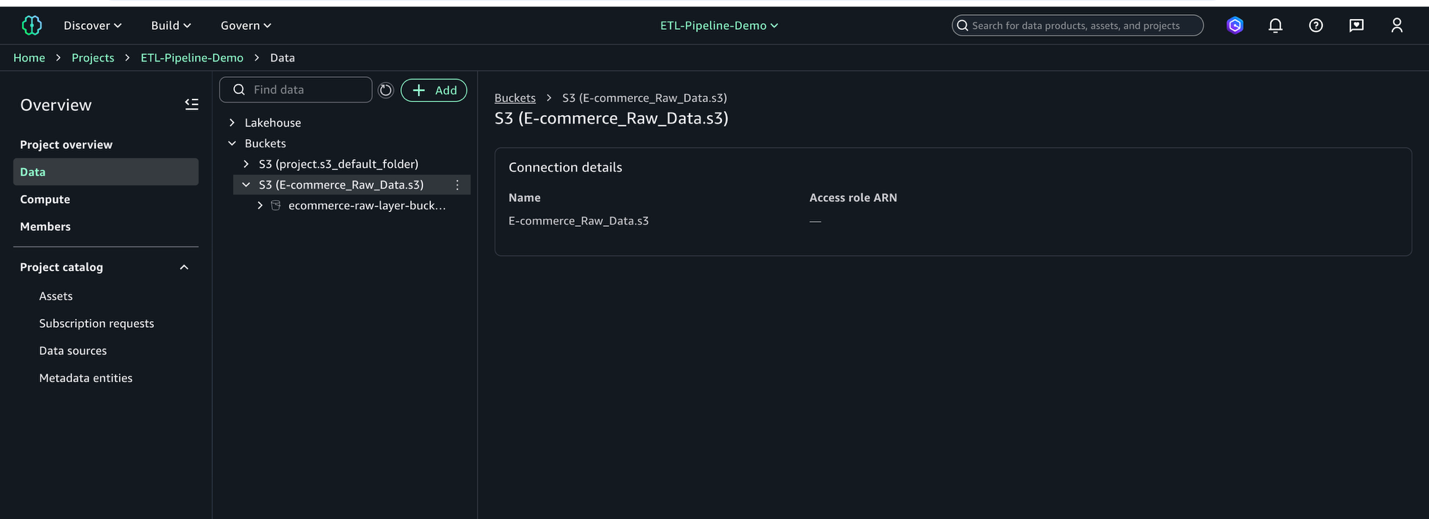
This course of connects your S3 bucket to SageMaker Unified Studio, making your knowledge prepared for evaluation.
Create pocket book for job scripts
Earlier than you may create the info processing jobs, you should arrange a pocket book to develop the scripts that can generate and course of your knowledge. Full the next steps:
- In SageMaker Unified Studio, on the highest menu, below Construct, select JupyterLab.
- Select Configure Area and select the occasion sort ml.t3.xlarge. This makes certain your JupyterLab occasion has no less than 4 vCPUs and 4 GiB of reminiscence.
- Select Configure and Begin Area or Save and Restart to launch your surroundings.
- Wait a number of moments for the occasion to be prepared.
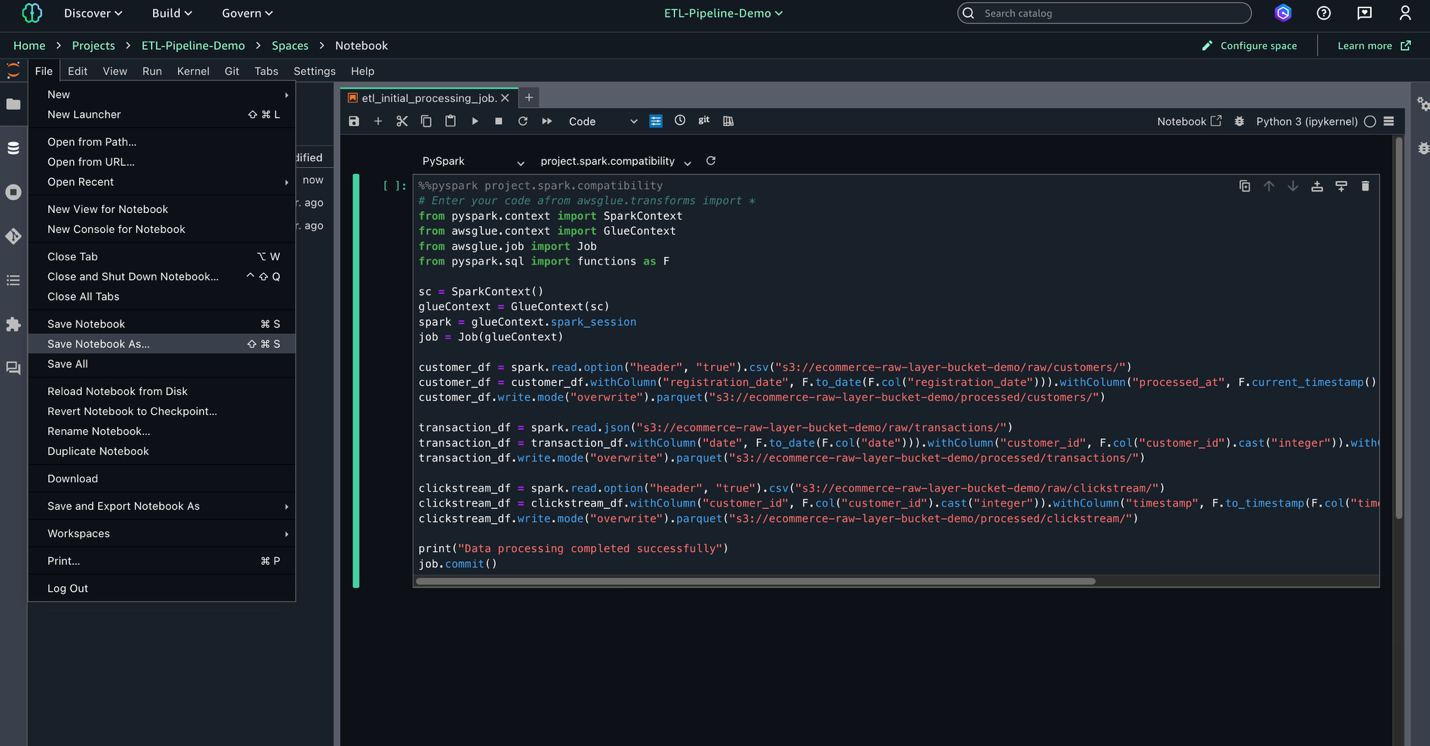
- Select File, New, and Pocket book to create a brand new pocket book.
- Set Kernel as Python 3, Connection sort as PySpark, and Compute as
Challenge.spark.compatibility.
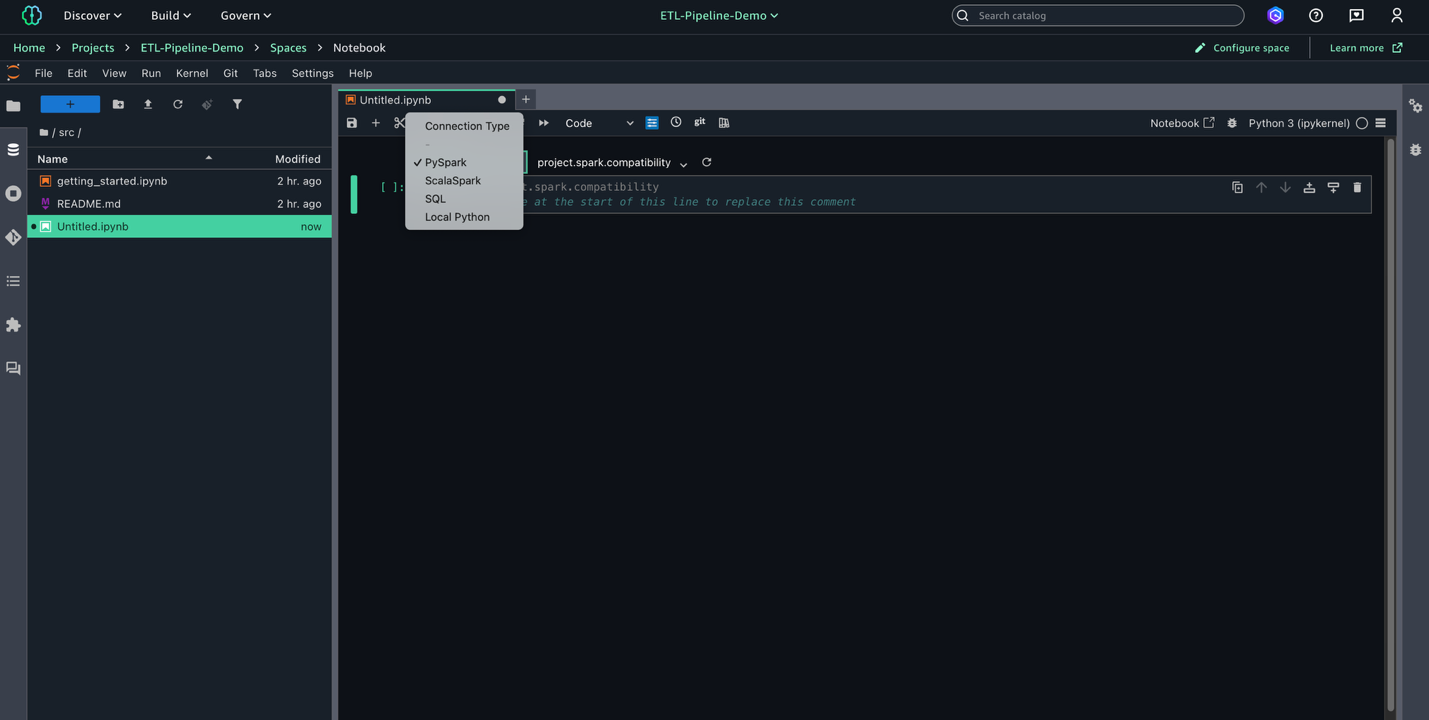
- Within the pocket book, enter the next script to make use of later in your AWS Glue job. This script processes uncooked knowledge from three sources within the S3 knowledge lake, standardizes dates, and converts knowledge varieties earlier than saving the cleaned knowledge in Parquet format for optimum storage and querying.
- Substitute
This script processes buyer, transaction, and clickstream knowledge from the uncooked layer in Amazon S3 and saves it as Parquet recordsdata within the processed layer.
- Select File, Save Pocket book As, and save the file as
shared/etl_initial_processing_job.ipynb.
Create pocket book for AWS Glue Information High quality
After you create the preliminary knowledge processing script, the following step is to arrange a pocket book to carry out knowledge high quality checks utilizing AWS Glue. These checks assist validate the integrity and completeness of your knowledge earlier than additional processing. Full the next steps:
- Select File, New, and Pocket book to create a brand new pocket book.
- Set Kernel as Python 3, Connection sort as PySpark, and Compute as
Challenge.spark.compatibility.
- On this new pocket book, add the info high quality test script utilizing the AWS Glue
EvaluateDataQualitytechnique. Substitute - Select File, Save Pocket book As, and save the file as
shared/etl_data_quality_job.ipynb.
Create and take a look at AWS Glue jobs
Jobs in SageMaker Unified Studio allow scalable, versatile ETL pipelines utilizing AWS Glue. This part walks by means of creating and testing knowledge processing jobs for environment friendly and ruled knowledge transformation.
Create preliminary knowledge processing job
This job performs the primary processing job within the ETL pipeline, reworking uncooked buyer, transaction, and clickstream knowledge and writing the cleaned output to Amazon S3 in Parquet format. Full the next steps to create the job:
- In SageMaker Unified Studio, go to your challenge.
- On the highest menu, select Construct, and below Information Evaluation & Integration, select Information processing jobs.

- Select Create job from notebooks.
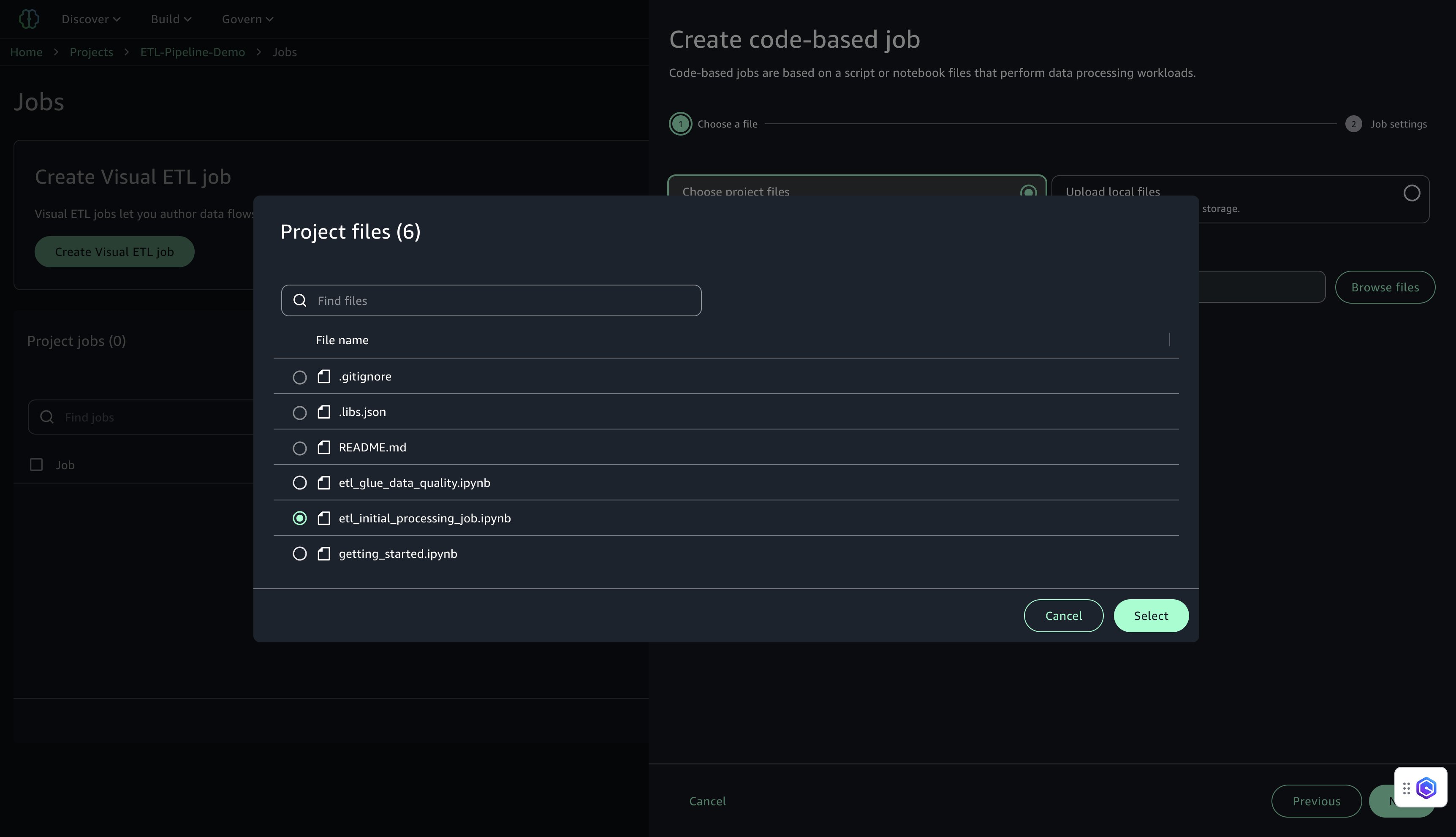
- Below Select challenge recordsdata, select Browse recordsdata.
- Find and choose
etl_initial_processing_job.ipynb(the pocket book saved earlier in JupyterLab), then select Choose and Subsequent.
- Configure the job settings:
- For Title, enter a reputation (for instance,
job-1). - For Description, enter an outline (for instance,
Preliminary ETL job for buyer knowledge processing). - For IAM Position, select the challenge position (default).
- For Sort, select Spark.
- For AWS Glue model, use model 5.0.
- For Language, select Python.
- For Employee sort, use G.1X.
- For Variety of Cases, set to 10.
- For Variety of retries, set to 0.
- For Job timeout, set to 480.
- For Compute connection, select
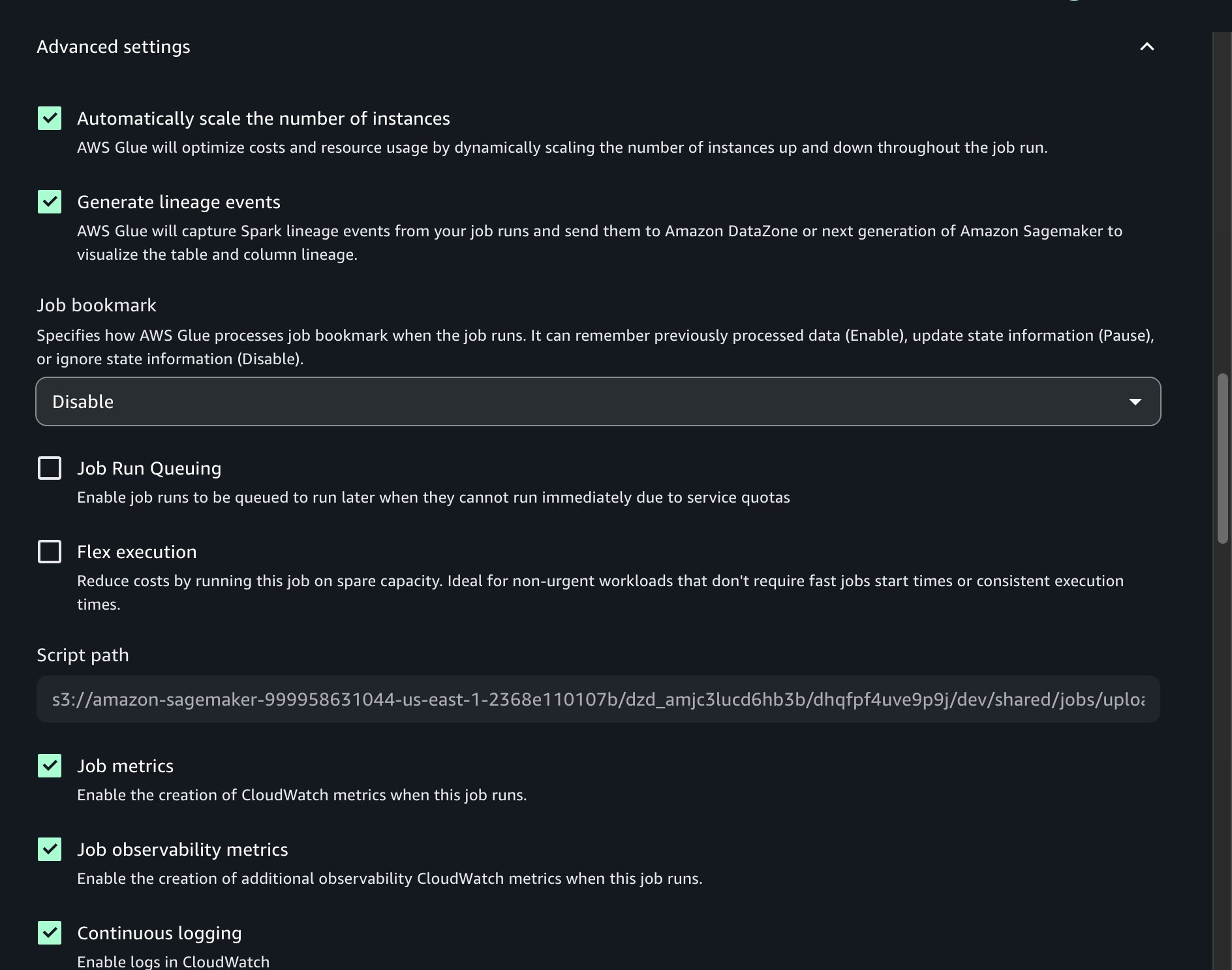
challenge.spark.compatibility. - Below Superior settings, activate Steady logging.
- For Title, enter a reputation (for instance,
- Depart the remaining settings as default, then select Submit.
After the job is created, a affirmation message will seem indicating that job-1 was created efficiently.
Create AWS Glue Information High quality job
This job runs knowledge high quality checks on the reworked datasets utilizing AWS Glue Information High quality. Rulesets validate completeness and uniqueness for key fields. Full the next steps to create the job:
- In SageMaker Unified Studio, go to your challenge.
- On the highest menu, select Construct, and below Information Evaluation & Integration, select Information processing jobs.
- Select Create job, Code-based job, and Create job from recordsdata.
- Below Select challenge recordsdata, select Browse recordsdata.
- Find and choose
etl_glue_data_quality.ipynb, then select Choose and Subsequent. - Configure the job settings:
- For Title, enter a reputation (for instance,
job-2). - For Description, enter an outline (for instance,
Information high quality checks utilizing AWS Glue Information High quality). - For IAM Position, select the challenge position.
- For Sort, select Spark.
- For AWS Glue model, use model 5.0.
- For Language, select Python.
- For Employee sort, use G.1X.
- For Variety of Cases, set to 10.
- For Variety of retries, set to 0.
- For Job timeout, set to 480.
- For Compute connection, select
challenge.spark.compatibility. - Below Superior settings, activate Steady logging.
- Depart the remaining settings as default, then select Submit.
After the job is created, a affirmation message will seem indicating that job-2 was created efficiently.
Take a look at AWS Glue jobs
Take a look at each jobs to ensure they execute efficiently:
- In SageMaker Unified Studio, go to your challenge.
- On the highest menu, select Construct, and below Information Evaluation & Integration, select Information processing jobs.
- Choose
job-1and select Run job. - Monitor the job execution and confirm it completes efficiently.
- Equally, choose
job-2and select Run job. - Monitor the job execution and confirm it completes efficiently.
Add EMR Serverless compute
Within the ETL pipeline, we use EMR Serverless to carry out compute-intensive transformations and aggregations on giant datasets. It mechanically scales assets primarily based on workload, providing excessive efficiency with simplified operations. By integrating EMR Serverless with SageMaker Unified Studio, you may simplify the method of working Spark jobs interactively utilizing Jupyter notebooks in a serverless surroundings.
This part walks by means of the steps to configure EMR Serverless compute inside SageMaker Studio and use it for executing distributed knowledge processing jobs.
Configure EMR Serverless in SageMaker Unified Studio
To make use of EMR Serverless for processing within the challenge, comply with these steps:
- Within the navigation pane on Challenge Overview, select Compute.
- On the Information processing tab, select Add compute and Create new compute assets.
- Choose EMR Serverless and select Subsequent.
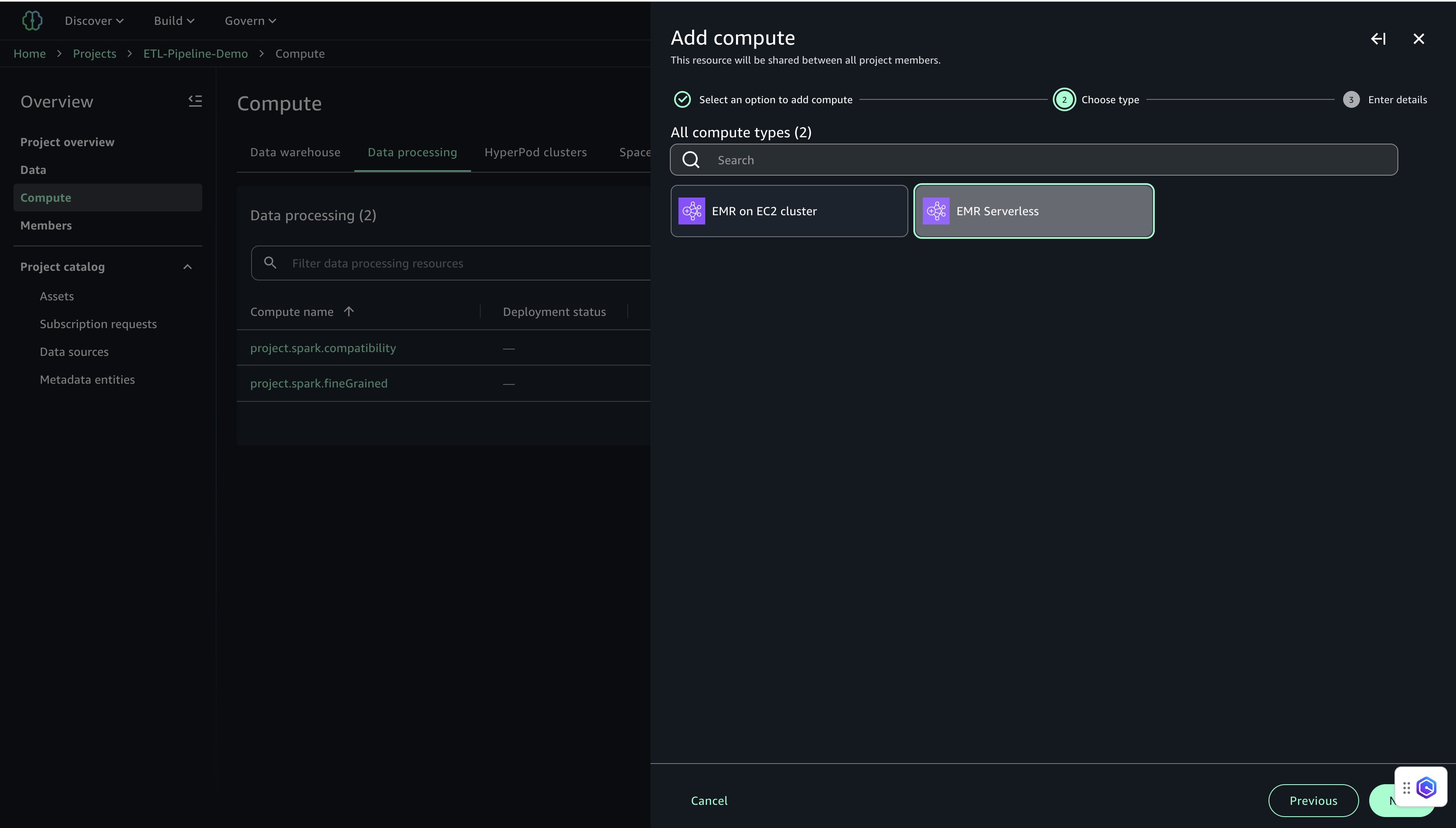
- Configure EMR Serverless settings:
- For Compute title, enter a reputation (for instance,
etl-emr-serverless). - For Description, enter an outline (for instance,
EMR Serverless for superior knowledge processing). - For Launch label, select emr-7.8.0.
- For Permission mode, select Compatibility.
- Select Add Compute to finish the setup.
After it’s configured, the EMR Serverless compute shall be listed with the deployment standing Lively.
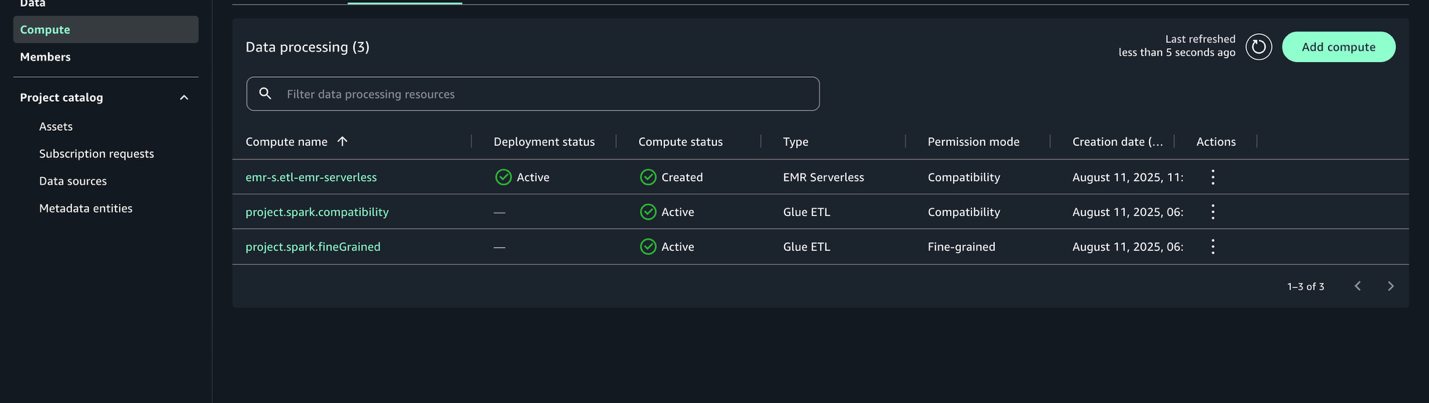
Create and run pocket book with EMR Serverless
After you create the EMR Serverless compute, you may run PySpark-based knowledge transformation jobs utilizing a Jupyter pocket book to carry out large-scale knowledge transformations. This job reads cleaned buyer, transaction, and clickstream datasets from Amazon S3, performs aggregations and scoring, and writes the ultimate analytics outputs again to Amazon S3 in each Parquet and CSV codecs.Full the next steps to create a pocket book for EMR Serverless processing:
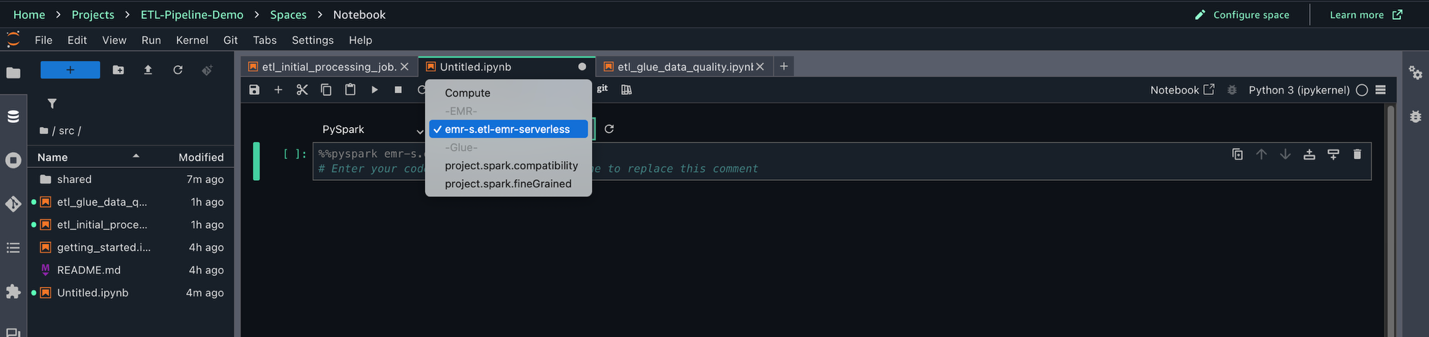
- On the highest menu, below Construct, select JupyterLab.
- Select File, New, and Pocket book.
- Set Kernel as Python 3, Connection sort as PySpark, and Compute as
emr-s.etl-emr-serverless.
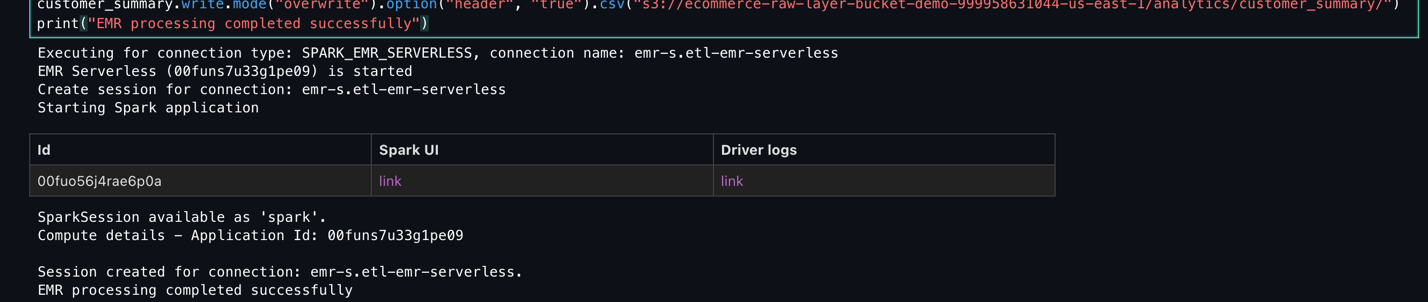
- Enter the next PySpark script to run your knowledge transformation job on EMR Serverless. Present the title of your S3 bucket:
- Select File, Save Pocket book As, and save the file as
shared/emr_data_transformation_job.ipynb. - Select Run Cell to run the script.
- Monitor the Script execution and confirm it completes efficiently.
- Monitor the Spark job execution and guarantee it completes with out errors.
Add Redshift Serverless compute
With Redshift Serverless, customers can run and scale knowledge warehouse workloads with out managing infrastructure. It’s preferrred for analytics use circumstances the place knowledge must be queried from Amazon S3 or built-in right into a centralized warehouse. On this step, you add Redshift Serverless to the challenge for loading and querying processed buyer analytics knowledge generated in earlier phases of the pipeline. For extra details about Redshift Serverless, see Amazon Redshift Serverless.
Arrange Redshift Serverless compute in SageMaker Unified Studio
Full the next steps to arrange Redshift Serverless compute:
- In SageMaker Unified Studio, select the Compute tab inside your challenge workspace (
ETL-Pipeline-Demo). - On the SQL analytics tab, select Add compute, then select Create new compute assets to start configuring your compute surroundings.
- Choose Amazon Redshift Serverless.
- Configure the next:
- For Compute title, enter a reputation (for instance,
ecommerce_data_warehouse). - For Description, enter an outline (for instance,
Redshift Serverless for knowledge warehouse). - For Workgroup title, enter a reputation (for instance,
redshift-serverless-workgroup). - For Most capability, set to 512 RPUs.
- For Database title, enter
dev.
- For Compute title, enter a reputation (for instance,
- Select Add Compute to create the Redshift Serverless useful resource.
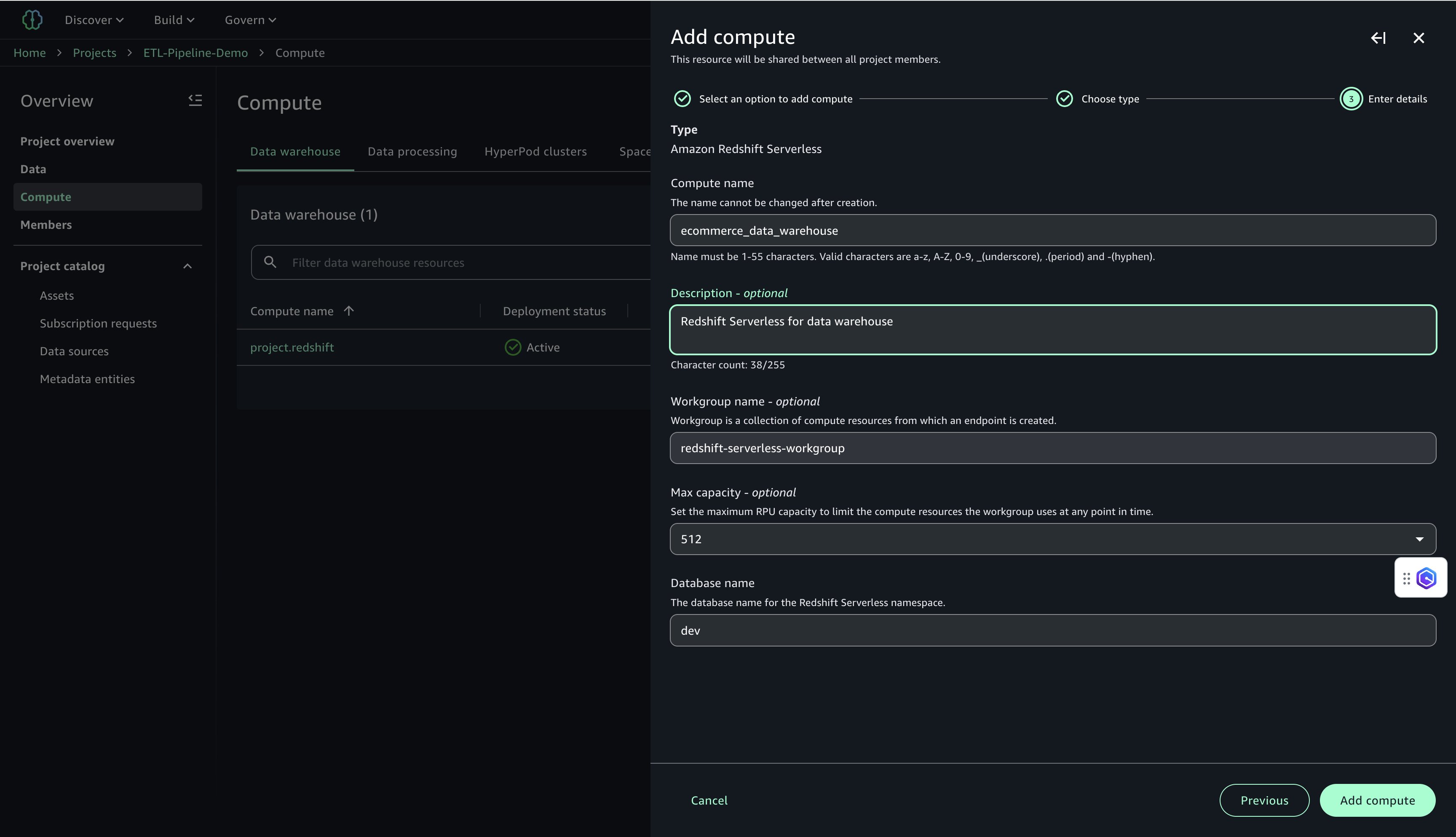
After the compute is created, you may take a look at the Amazon Redshift connection.
- On the Information warehouse tab, affirm that
redshift.ecommerce_data_warehouseis listed.
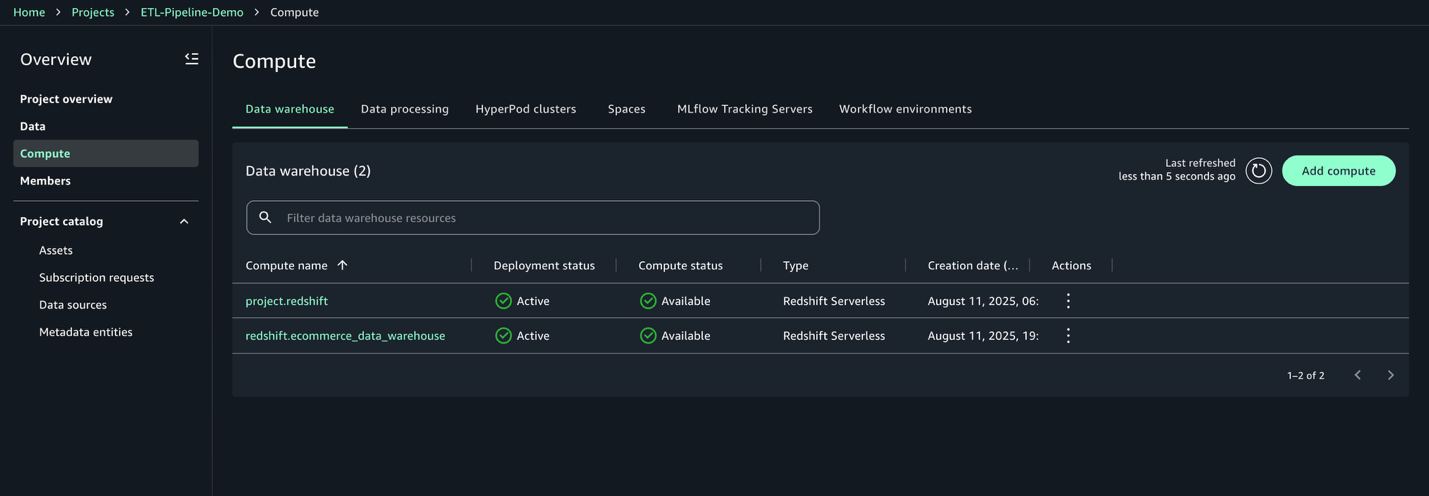
- Select the compute:
redshift.ecommerce_data_warehouse. - On the Permissions tab, copy the IAM position ARN. You employ this for the Redshift COPY command within the subsequent step.

Create and execute querybook to load knowledge into Amazon Redshift
On this step, you create a SQL script to load the processed buyer abstract knowledge from Amazon S3 right into a Redshift desk. This permits centralized analytics for buyer segmentation, lifetime worth calculations, and advertising and marketing campaigns. Full the next steps:
- On the Construct menu, below Information Evaluation & Integration, select Question editor.
- Enter the next SQL into the querybook to create the
customer_summarydesk within the public schema: - Select Add SQL so as to add a brand new SQL script.
- Enter the next SQL into the querybook
Observe: We truncate the
customer_summarydesk to take away current data and guarantee a clear, duplicate-free reload of the newest aggregated knowledge from S3 earlier than working the COPY command. - Select Add SQL so as to add a brand new SQL script.
- Enter the next SQL to load the info into Redshift Serverless out of your S3 bucket. Present the title of your S3 bucket and IAM position ARN for Amazon Redshift:
- Within the Question Editor, configure the next:
- Connection:
redshift.ecommerce_data_warehouse - Database:
dev - Schema:
public
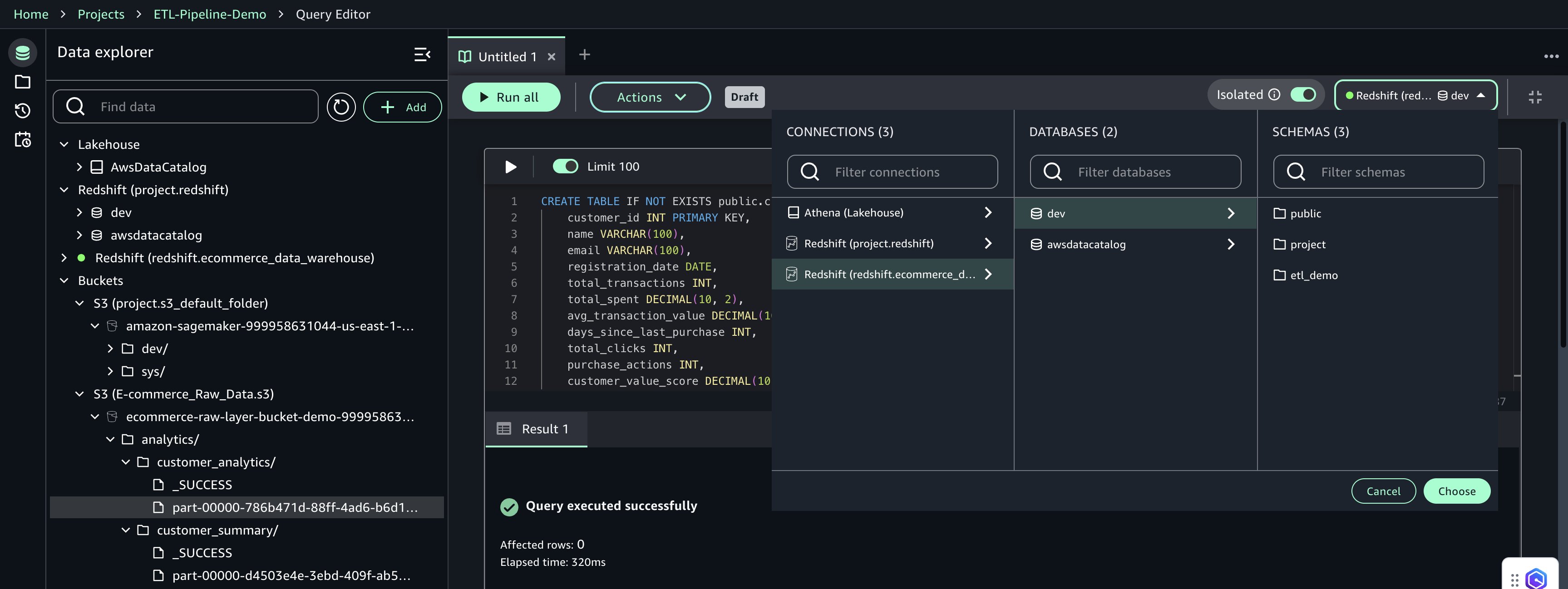
- Connection:
- Select Select to use the connection settings.
- Select Run Cell for every cell to create the
customer_summarydesk within the public schema after which load knowledge from Amazon S3. - Select Actions, Save, title the querybook
final_data_product, and select Save modifications.
This completes the creation and execution of the Redshift knowledge product utilizing the querybook.
Create and handle the workflow surroundings
This part describes tips on how to create a shared workflow surroundings and outline a code-based workflow that automates a buyer knowledge pipeline utilizing Apache Airflow inside SageMaker Unified Studio. Shared environments facilitate collaboration amongst challenge members and centralized workflow administration.
Create the workflow surroundings
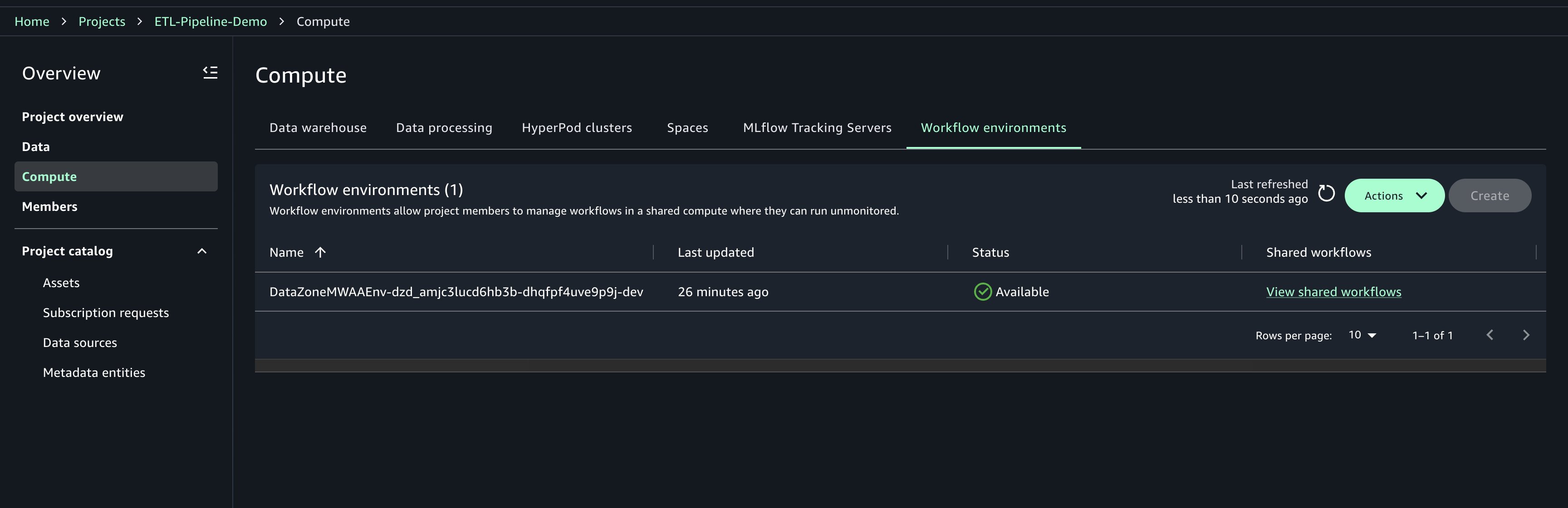
Workflow environments have to be created by challenge house owners. After they’re created, members of the challenge can sync and use the workflows. Solely challenge house owners can replace or delete workflow environments. Full the next steps to create the workflow surroundings:
- Select Compute in your challenge.
- On the Workflow environments tab, select Create.
- Assessment the configuration parameters and select Create workflow surroundings.
- Await the surroundings to be totally provisioned earlier than continuing It can take round 20 minutes to provision.
Create the code-based workflow
When the workflow surroundings is prepared, outline a code-based ETL pipeline utilizing Airflow. This pipeline automates each day processing duties throughout companies like AWS Glue, EMR Serverless, and Redshift Serverless.
- On the Construct menu, below Orchestration, select Workflows.
- Select Create new workflow, then select Create workflow in code editor.
- Configure Area and select the occasion sort ml.t3.xlarge. This ensures your JupyterLab occasion has no less than 4 vCPUs and 4 GiB of reminiscence.
- Select Configure and Restart Area to launch your surroundings.

The next script defines a each day scheduled ETL workflow that automates a number of actions:
- Preliminary knowledge transformation utilizing AWS Glue
- Information high quality validation utilizing AWS Glue (EvaluateDataQuality)
- Superior knowledge processing with EMR Serverless utilizing a Jupyter pocket book
- Loading reworked outcomes into Redshift Serverless from a querybook
- Substitute the default DAG template with the next definition, guaranteeing that job names and enter paths match the precise names utilized in your challenge:
- Select File, Save python file, title the file
shared/workflows/dags/customer_etl_pipeline.py, and select Save.
Deploy and run the workflow
Full the next steps to run the workflow:
- On the Construct menu, select Workflows.
- Select the workflow
customer_etl_pipelineand select Run.
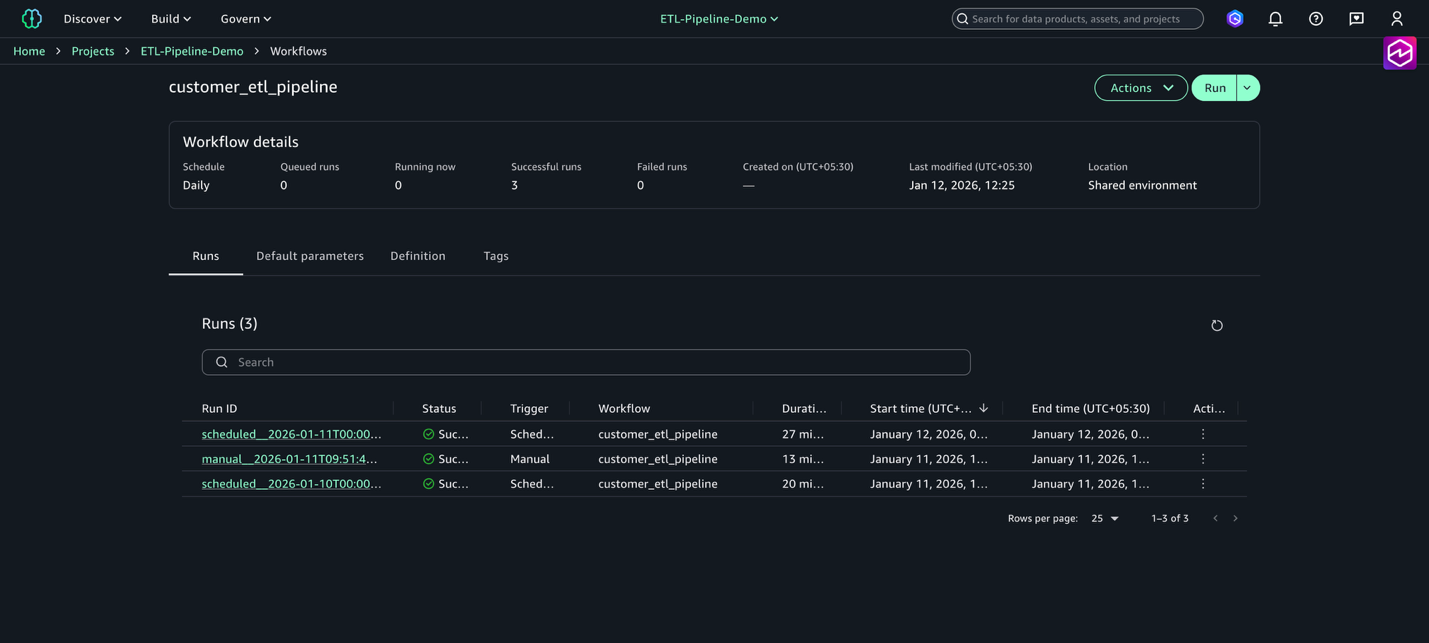
Working a workflow places duties collectively to orchestrate Amazon SageMaker Unified Studio artifacts. You possibly can view a number of runs for a workflow by navigating to the Workflows web page and selecting the title of a workflow from the workflows record desk.
To share your workflows with different challenge members in a workflow surroundings, check with Share a code workflow with different challenge members in an Amazon SageMaker Unified Studio workflow surroundings.
Monitor and troubleshoot the workflow
After your Airflow workflows are deployed in SageMaker Unified Studio, monitoring turns into important for sustaining dependable ETL operations. The built-in Amazon MWAA surroundings supplies complete observability into your knowledge pipelines by means of the acquainted Airflow internet interface, enhanced with AWS monitoring capabilities. The Amazon MWAA integration with SageMaker Unified Studio affords real-time DAG execution monitoring, detailed job logs, and efficiency metrics that will help you shortly determine and resolve pipeline points. Full the next steps to watch the workflow:
- On the Construct menu, select Workflows.
- Select the workflow
customer_etl_pipeline. - Select View runs to see all executions.
- Select a selected run to view detailed job standing.
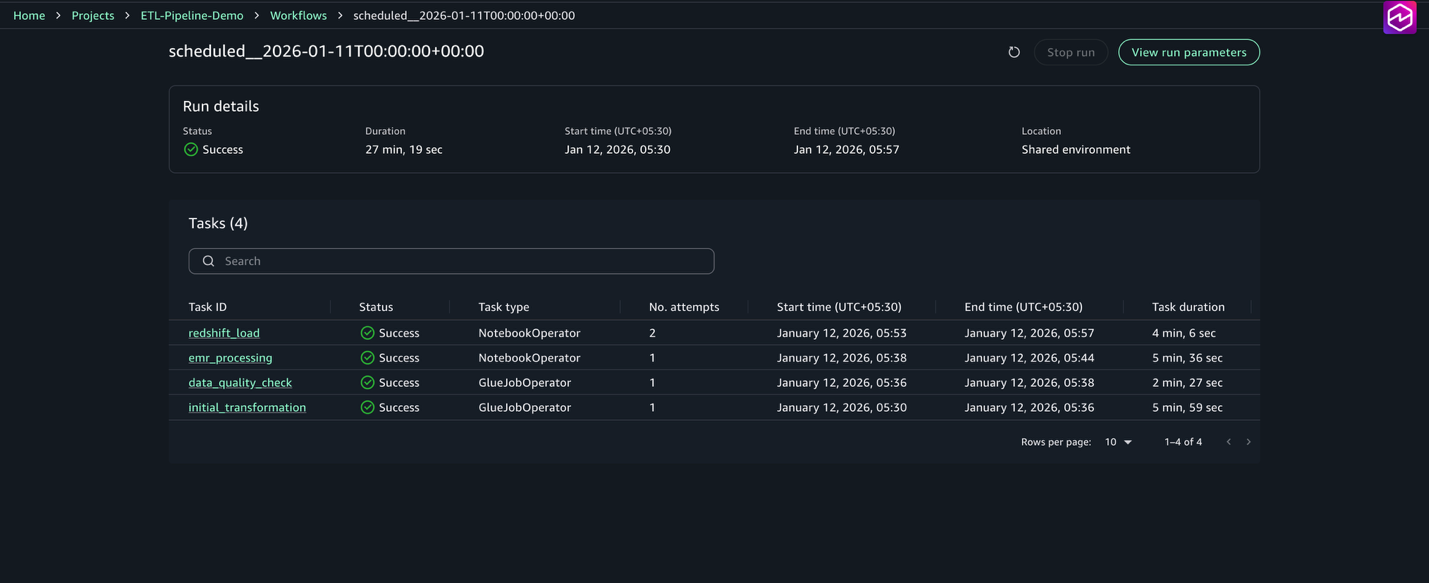
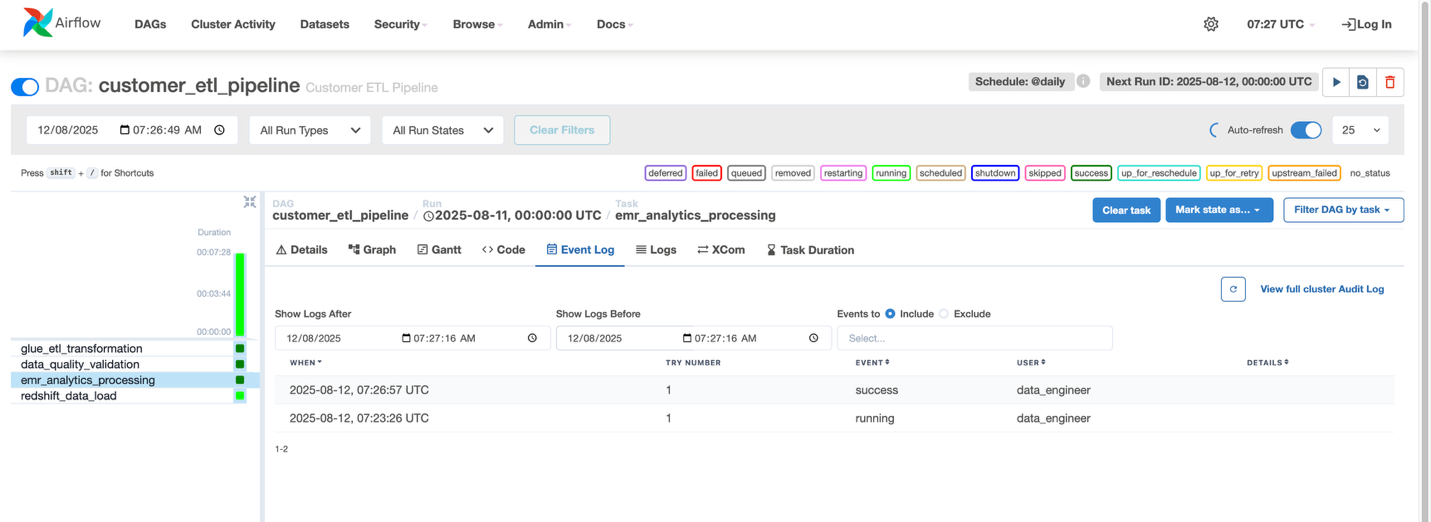
For every job, you may view the standing (Succeeded, Failed, Working), begin and finish instances, period, and logs and outputs. The workflow can be seen within the Airflow UI, accessible by means of the workflow surroundings, the place you may view the DAG graph, monitor job execution in actual time, entry detailed logs, and think about the standing.
- Go to Workflows and choose the workflow named customer_etl_pipeline.
- From the Actions menu, select Open in Airflow UI.
After the workflow completes efficiently, you may question the info product within the question editor.
- On the Construct menu, below Information Evaluation & Integration, select Question editor.
- Run
choose * from "dev"."public"."customer_summary"
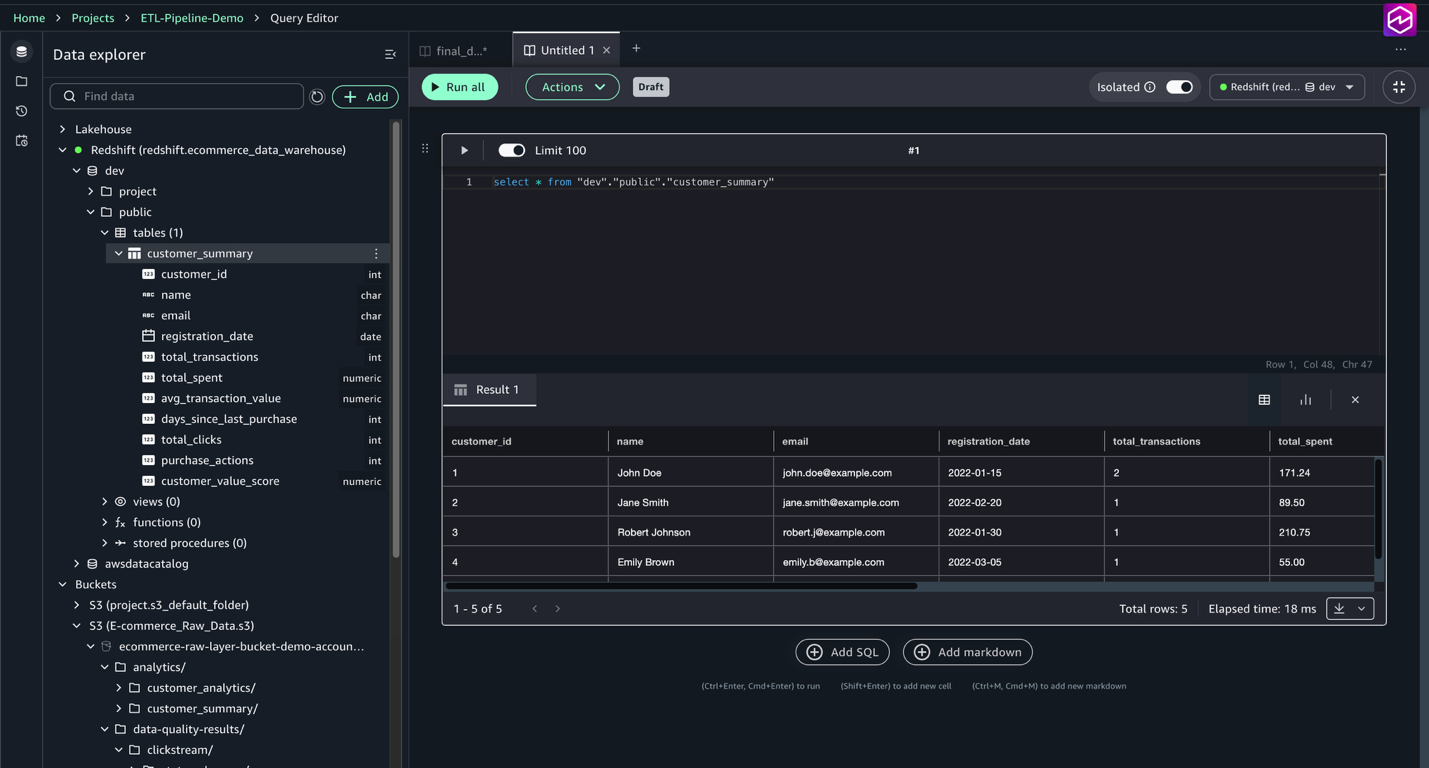
Observe the contents of the customer_summary desk, together with aggregated buyer metrics similar to whole transactions, whole spent, common transaction worth, clicks, and buyer worth scores. This enables verification that the ETL and knowledge high quality pipelines loaded and reworked the info accurately.
Clear up
To keep away from pointless fees, full the next steps:
- Delete a workflow surroundings.
- In the event you now not want it, delete the challenge.
- After you delete the challenge, delete the area.
Conclusion
This submit demonstrated tips on how to construct an end-to-end ETL pipeline utilizing SageMaker Unified Studio workflows. We explored the entire growth lifecycle, from organising elementary AWS infrastructure—together with Amazon S3 CORS configuration and IAM permissions—to implementing subtle knowledge processing workflows. The answer incorporates AWS Glue for preliminary knowledge transformation and high quality checks, EMR Serverless for superior processing, and Redshift Serverless for knowledge warehousing, all orchestrated by means of Airflow DAGs. This method affords a number of key advantages: a unified interface that consolidates vital instruments, Python-based workflow flexibility, seamless AWS service integration, collaborative growth by means of Git model management, cost-effective scaling by means of serverless computing, and complete monitoring instruments—all working collectively to create an environment friendly and maintainable knowledge pipeline resolution.
By utilizing SageMaker Unified Studio workflows, you may speed up your knowledge pipeline growth whereas sustaining enterprise-grade reliability and scalability. For extra details about SageMaker Unified Studio and its capabilities, check with the Amazon SageMaker Unified Studio documentation.
In regards to the authors