
{kind=link}
If you happen to’ve been interested by working with providers like Claude Code, however balk on the thought of hitching your IDE to a black-box cloud service and shelling out for tokens, we’re steps nearer to an answer. However we’re not fairly there but.
With every new era of giant language fashions, we’re seeing smaller and extra environment friendly LLMs for a lot of use instances—sufficiently small you could run them by yourself {hardware}. Most not too long ago, we’ve seen a slew of latest fashions designed for duties like code evaluation and code era. The not too long ago launched Qwen3.5 mannequin set is one instance.
What’s it like to make use of these fashions for native improvement? I sat down with a couple of of the extra svelte Qwen3.5 fashions, LM Studio (a neighborhood internet hosting utility for inference fashions), and Visible Studio Code to seek out out.
Organising Qwen3.5 on my desktop
To check out Qwen3.5 for improvement, I used my desktop system, an AMD Ryzen 5 3600 6-core processor operating at 3.6 Ghz, with 32GB of RAM and an RTX 5060 GPU with 8GB of VRAM. I’ve run inference work on this technique earlier than utilizing each LM Studio and ComfyUI, so I knew it was no slouch. I additionally knew from earlier expertise that LM Studio may be configured to serve fashions domestically.
For the fashions, I selected a couple of completely different iterations of the Qwen3.5 collection. Qwen3.5 is available in many variations offered by group contributors, all in a variety of sizes. I wasn’t about to attempt the 397-billion parameter model, as an example: there’s no approach I may crowbar a 241GB mannequin into my {hardware}. As a substitute, I went with these Qwen3.5 variants:
qwen3.5-9b@q5_1: A 9.5-billion parameter model, which weighs in at a mere 6.5GB, and makes use of 5-bit quantization.qwen3.5-9b-claude-4.6-opus-reasoning-distilled: A group variant of the 9.5-billion parameter mannequin—this one “enhanced with reasoning information distilled from Qwen3.5-27B” and utilizing 4-bit quantization.qwen3.5-4b: A 3rd variant, with 4 billion parameters and 6-bit quantization.
In every case, I used to be curious in regards to the tradeoffs between the mannequin’s parameter measurement and its quantization. Would smaller variations of the identical mannequin have comparable efficiency?
Operating the fashions on LM Studio didn’t mechanically enable me to make use of them in an IDE. The blocker right here was not LM Studio however VS Code, which doesn’t work out of the field with any LLM supplier apart from GitHub Copilot. Fortuitously, a third-party add-on known as Proceed enables you to hitch VS Code to any supplier, native or distant, that makes use of widespread APIs—and it helps LM Studio out of the field.
Proceed is a VS Code extension that connects to quite a lot of LLM suppliers. It comes with built-in connectivity choices for LM Studio.
Foundry
Organising the take a look at drive
My testbed undertaking was one thing I’m at the moment creating, a utility for Python that enables a Python package deal to be redistributed on techniques with out the Python runtime. It’s not an enormous undertaking— one file that’s underneath 500 traces of code—which made it a very good candidate for testing a improvement mannequin domestically.
The Proceed extension enables you to use hooked up information or references to an open undertaking to provide context for a immediate. I pointed to the undertaking file and used the next immediate for every mannequin:
The file at the moment open is a utility for Python that takes a Python package deal and makes it right into a standalone redistributable artifact on Microsoft Home windows by bundling a duplicate of the Python interpreter. Look at the code and make constructive ideas for the way it might be made extra modular and simpler to combine right into a CI/CD workflow.
Once you load a mannequin into reminiscence, you possibly can twiddle a mind-boggling array of knobs to manage how predictions are served with it. The 2 knobs which have the most important affect are context size and GPU offload:
- Context size is what number of tokens the mannequin can work with in a single immediate; the extra tokens, the extra concerned the dialog.
- GPU offload is what number of layers of the mannequin are run on the GPU to hurry it up; the extra layers, the sooner the inference.
Turning up both of those consumes reminiscence—system and GPU reminiscence, each—so there are onerous ceilings to how excessive they will go. GPU offload has the most important affect on efficiency, so I set that to the utmost for every mannequin, then set the context size as excessive as I may for that mannequin whereas nonetheless leaving some GPU reminiscence.
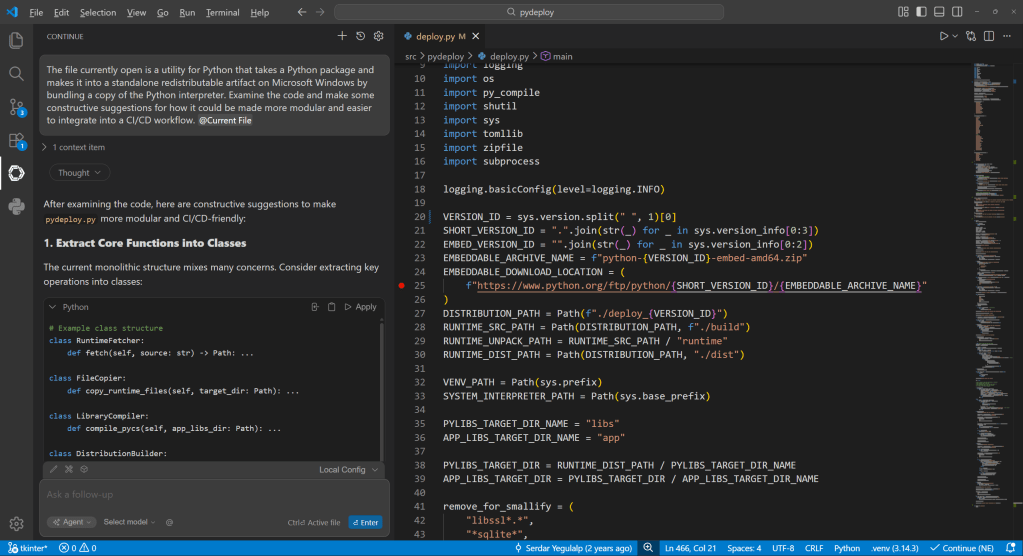
Serving predictions domestically with LM Studio, by means of the Proceed plugin for VS Code. The Proceed interface doesn’t present lots of the low-level particulars in regards to the dialog you could see in LM Studio immediately (e.g., token utilization), however does enable embedding context from the present undertaking or any file.
Foundry
Configuring the three fashions
qwen3.5-9b@q5_1 was the biggest of the three fashions I examined, at 6.33GB. I set it to make use of 8,192 tokens and 28 layers, for 7.94GB complete GPU reminiscence use. This proved to be approach too sluggish to make use of effectively, so I racked again the token depend sufficient to make use of all 32 layers. Predictions got here way more snappily after that.
qwen3.5-9b-claude-4.6-opus-reasoning-distilled weighed in at 4.97GB, which allowed for a far greater token size (16,000 tokens) and all 32 layers. Out of the gate, it delivered a lot sooner inference and tokenization of the enter, which means I didn’t have to attend lengthy for the primary reply or for the entire response.
qwen3.5-4b, the littlest brother, is barely 3.15GB, which means I may use a good bigger token window if I selected to, however I stored it at 16,000 for now, and in addition used all 32 layers. Its time-to-first reply was additionally quick, though general pace of inference was about the identical because the earlier mannequin.
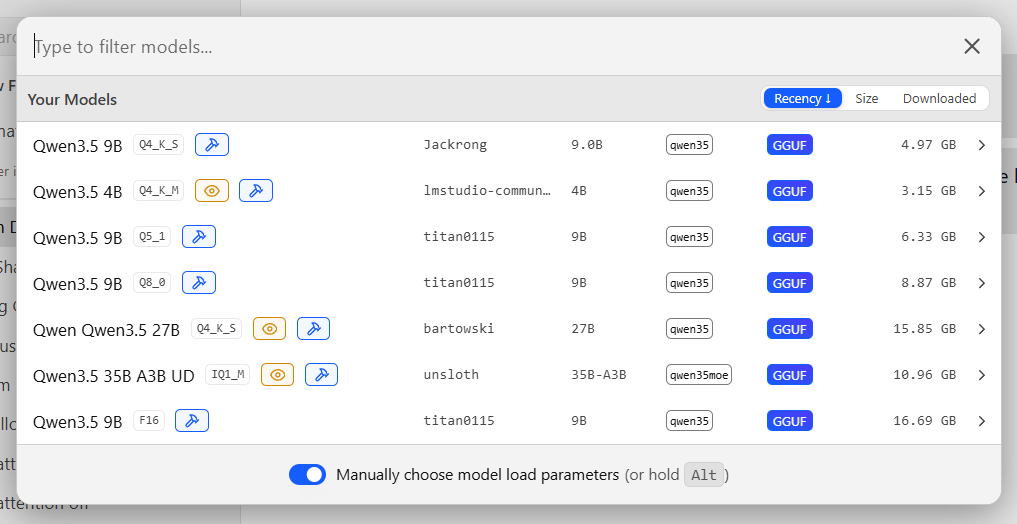
Quite a lot of Qwen3.5 fashions with completely different sizes and quantizations. Some are far too huge to run comfortably on commodity {hardware}; others can run on even a modest PC.
Foundry
The great, the dangerous, and the busted
With every mannequin, my question produced a slew of constructive ideas: “Refactor the primary entry level to make use of step features,” or “Add assist for atmosphere variables.” Most have been accompanied by pattern snippets—generally full segments of code, generally transient conceptual designs. As with all LLM’s output, the outcomes various loads between runs—even on the identical mannequin with as lots of the parameters configured as attainable to provide comparable output.
The most important variations between the outputs have been primarily in how a lot element the mannequin offered for its response, however even that various lower than I anticipated. Even the the smallest of the fashions nonetheless offered respectable recommendation, though I discovered the midsized mannequin (the “distilled” 9B mannequin) struck a very good steadiness between compactness and energy. Nonetheless, having a lot of token house didn’t assure outcomes. Even with appreciable context, some conversations stopped lifeless within the center for no obvious motive.
The place issues broke down throughout the board, although, is once I tried to let the fashions put their recommendation into direct motion. Fashions may be supplied with contextual instruments, akin to altering code along with your permission, or wanting issues up on the internet. Sadly, most something referring to working with the code immediately crashed out onerous, or solely labored after a number of makes an attempt.
As an example, once I tried to let the “distilled” 9B mannequin add advisable kind hints to my undertaking, it failed fully. On the primary try, it crashed in the course of the operation. On the second attempt, it obtained caught in an inside loop, then backed out of it and determined so as to add solely crucial kind hints. This it was in a position to do, but it surely mangled a number of indents within the course of, making a cascading failure for the remainder of the job. And on yet one more try, the agent tried to simply erase all the undertaking file.
Conclusions
Essentially the most disappointing a part of this entire endeavor was the best way the fashions failed at truly making use of any of their advisable adjustments, or solely did so after repeated makes an attempt. I think the difficulty isn’t device use within the summary, however device use that requires a lot of context. Cloud-hosted fashions theoretically have entry to sufficient reminiscence to make use of their full context token window (262,144 for the fashions I evaluated). Nonetheless, from my expertise, even the cloud fashions can choke and die on their inputs.
Proper now, utilizing a compact native mannequin to get perception and suggestions a couple of codebase works finest when you’ve gotten sufficient GPU reminiscence for all the mannequin plus the wanted context size to your work. It’s additionally finest for acquiring high-level recommendation you intend to implement your self, moderately than superior device operations the place the mannequin makes an attempt to autonomously change the code. However I’ve additionally had that that have with the full-blown variations of those fashions.