
{kind=link}
The newest set of open-source fashions from DeepSeek are right here.
Whereas the business anticipated the dominance of “closed” iterations like GPT-5.5, the arrival of DeepSeek-V4 has ticked the dominance within the favour of open-source AI. By combining a 1.6 trillion parameter MoE structure with an enormous 1 million token context window, DeepSeek-V4 has successfully commoditized high-reasoning intelligence.
This shift is altering the best way we take into consideration AI prices and capabilities. Let’s decode the newest variants of DeepSeek household.
What’s DeepSeek-V4?
DeepSeek-V4 is the newest iteration of the DeepSeek mannequin household, particularly designed to deal with long-context information. It could possibly proccess upto 1 million tokens effectively making it ideally suited for duties similar to superior reasoning, code era, and doc summarization. It makes use of progressive hybrid mechanisms like Manifold-Constrained Hyper-Connections (mHC), permitting it to course of over one million tokens effectively. This makes it a best choice for industries and builders seeking to combine AI into their workflows at scale.
Key Options of DeepSeek-V4
Listed below are the notable options of DeepSeek’s newest mannequin:
- Open-Supply (Apache 2.0): In contrast to “closed” fashions from OpenAI or Google, DeepSeek-V4 is totally open-source. This implies the weights and code can be found for anybody to obtain, modify, and run on their very own {hardware}.
- Large Value Financial savings: The API is priced at a fraction of its opponents, roughly 1/fifth the price of GPT-5.5.
- Two Mannequin Variants:
- DeepSeek-V4-Professional: A extremely highly effective model with 1.6 trillion parameters, designed for high-end computational duties.
- DeepSeek-V4-Flash: A extra environment friendly, cost-effective model that gives a lot of the advantages of the Professional model at a diminished worth.
| Mannequin | Complete Params | Energetic Params | Pre-trained Tokens | Context Size | Open Supply | API Service | WEB/APP Mode |
|---|---|---|---|---|---|---|---|
| deepseek-v4-pro | 1.6T | 49B | 33T | 1M | ✔️ | ✔️ | Skilled |
| deepseek-v4-flash | 284B | 13B | 32T | 1M | ✔️ | ✔️ | Prompt |
- Unmatched Agentic Functionality: Particularly optimized to behave as an “Autonomous Agent.” It doesn’t simply reply questions; it will probably navigate your whole challenge, use instruments, and full multi-step duties like a digital worker.
- World-Class Reasoning: In math and aggressive coding benchmarks, it matches or beats the world’s strongest non-public fashions, proving that open-source can compete on the “Frontier” degree.
- Shopper-{Hardware} Prepared: Because of excessive effectivity, the V4-Flash model can run on high-end shopper GPUs (like a twin RTX 5090 setup), bringing “GPT-class” efficiency to your native desk.
DeepSeek-V4: Technical Breakthroughs
DeepSeek-V4 doesn’t simply succeed by means of brute pressure. It introduces three particular architectural improvements that clear up the lengthy context drawback:
- Hybrid Consideration (CSA + HCA): By combining Compressed Sparse Consideration with Closely Compressed Consideration, the mannequin reduces VRAM overhead by 70% in comparison with customary FlashAttention-2, permitting 1M context lengths to run on consumer-grade enterprise {hardware}.
- The Muon Optimizer: A revolutionary second-order optimization method that permits the mannequin to succeed in “convergence” sooner throughout coaching, guaranteeing that the 1.6T parameters are literally utilized effectively fairly than remaining on the config sheet.
Right here is how these optimizations assist enhance the transformer structure of DeepSeek-V4 as in comparison with a normal transformer structure.
| Characteristic | Normal Transformer | DeepSeek-V4 (2026) |
| Consideration Scaling | Quadratic (O(n2)) | Sub-Linear/Hybrid |
| KV Cache Measurement | 100% (Baseline) | 12% of Baseline |
| Optimization | First-Order (AdamW) | Second-Order (Muon) |
| Prediction | Single-Token | Multi-Token (4-step) |
This structure primarily makes DeepSeek-V4 a “Reasoning Engine” fairly than only a textual content generator.
This effectivity not solely improved the standard of the mannequin responses but in addition made it reasonably priced!
Financial Disruption: The Worth Conflict
Probably the most fast impression of DeepSeek-V4 is its pricing technique. It has compelled a “race to the underside” that advantages builders and startups (us).
API Pricing Comparability (USD per 1M Tokens)
| Mannequin | Enter (Cache Miss) | Output | Value Effectivity vs. GPT-5.5 |
| DeepSeek-V4 Flash | $0.14 | $0.28 | ~36x Cheaper |
| GPT-5.5 (Base) | $5.00 | $30.00 | Reference |
DeepSeek’s Cache Hit pricing ($0.028) makes agentic workflows (the place the identical context is prompted repeatedly) practically free. This allows perpetual AI brokers that may “dwell” inside a codebase for cents per day.
ChatGPT and Claude customers are shedding their thoughts with this pricing! And that too a couple of hours after the discharge of GPT 5.5! That clearly sends a message.
And this benefit isn’t restricted to the pricing alone. The efficiency of the DeepSeek V4 clearly places it in a category of its personal.
DeepSeek-V4 vs. The Giants: Benchmarks
Whereas OpenAI and Anthropic have historically led in educational reasoning, DeepSeek-V4 has formally closed the hole in utilized engineering and agentic autonomy. It isn’t simply matching the competitors; it’s outperforming them in most eventualities.
1. The Engineering Edge: SWE-bench Verified
That is the gold customary for AI coding. It checks a mannequin’s skill to repair actual GitHub points end-to-end. DeepSeek-V4-Professional has set a brand new document, significantly in multi-file repository administration.
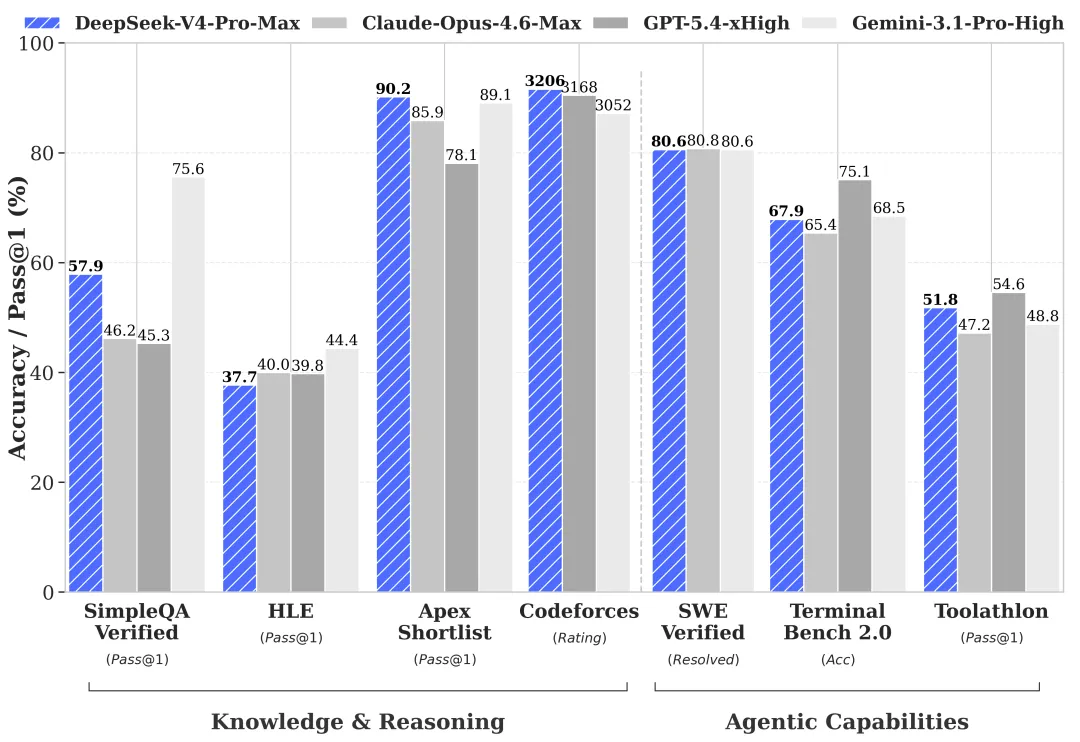
Here’s a desk define the efficiency in distinction to different SOTA fashions:
| Mannequin | SWE-bench Verified (Rating) | Context Reliability (1M Tokens) |
| DeepSeek-V4 Professional | 80.6% | 97.0% (Close to-Good) |
| GPT-5.5 | 80.8% | 82.5% |
| Gemini 3.1 Professional | 80.6% | 94.0% |
2. Arithmetic & Reasoning (AIME / GPQA)
In PhD-level science and aggressive math, DeepSeek-V4’s “Considering Mode” (DeepSeek-Reasoner V4) now trades blows with the costliest “O-series” fashions from OpenAI.
- GPQA (PhD-level Science): 91.8% (DeepSeek-V4) vs. 93.2% (GPT-5.5 Professional).
- AIME 2026 (Math): 96.4% (DeepSeek-V4) vs. 95.0% (Claude 4.6).
There’s a clear competitors when it comes to each reasoning and mathematical duties.
The best way to Entry DeepSeek-V4
You’ll be able to entry DeepSeek-V4 by means of a number of strategies:
- Internet Interface: Entry by means of DeepSeek’s platform at chat.deepseek.com with a easy sign-up and login.
- Cloud Platforms: Use DeepSeek-V4 by way of cloud-based IDEs or providers like HuggingFace areas.
- Native Deployment: Use providers like VLLM which supply DeepSeek-V4 native downloads and utilization.
Every technique supplies alternative ways to combine DeepSeek-V4 into your workflow based mostly in your wants. Select your technique and enter the frontier with these new fashions.
Shaping the Future
DeepSeek-V4 represents the transition of AI from a query-response software to a persistent collaborator. Its mixture of open-source accessibility, unprecedented context depth, and “Flash” pricing makes it probably the most important launch of 2026. For builders, the message is obvious: the bottleneck is now not the price of intelligence, however the creativeness of the individual prompting it.
Incessantly Requested Questions
A. Sure, the weights are launched below the DeepSeek License, permitting for industrial use with minor restrictions on massive-scale redeployment.
A. DeepSeek-V4 is natively multimodal, however at the moment it doesn’t assist that. The builders declare that It’d be rolled out quickly.
A. It makes use of a “distilled” MoE structure, the place solely 13B of the 248B parameters are energetic at any given inference step.
I concentrate on reviewing and refining AI-driven analysis, technical documentation, and content material associated to rising AI applied sciences. My expertise spans AI mannequin coaching, information evaluation, and knowledge retrieval, permitting me to craft content material that’s each technically correct and accessible.
Login to proceed studying and luxuriate in expert-curated content material.