
{kind=link}
Need to add a security layer in your chatbot, picture analyzer or any one other LLM-based system? I’d strongly recommend you attempt OpenAI’s moderation mannequin: omni-moderation-latest, this will help your system determine if the enter is probably dangerous or not, that too freed from price. We’ll look into the background of the mannequin, tips on how to entry it and tips on how to use it for each textual content and picture moderation. With none additional ado, let’s get began.
OpenAI’s Omni Moderation Fashions
OpenAI affords two fashions particularly for moderation: ‘text-moderation-latest’ (legacy) and ‘omni-moderation-latest’, with the latter one being the most recent. The Omni Moderation mannequin is predicated on GPT-4o and therefore it helps multimodal moderation, which is textual content moderation and picture moderation. It’s additionally value mentioning that the Omni Moderation endpoint is free to make use of.
The Omni Moderation API scores and classifies the next classes for the enter:
- hate
- harassment
- violence
- self-harm
- sexual content material
- illicit content material
Demonstration
Let’s check the moderation endpoint from OpenAI and experiment with protected and unsafe inputs, utilizing textual content and pictures. I’ll be utilizing Google Colab for this demonstration, be happy to make use of what you favor.
Prerequisite
You’ll require an OpenAI API Key, the mannequin is free to make use of however you’ll nonetheless want the API key. Get your key from right here: https://platform.openai.com/settings/group/api-keys
Imports and Consumer Initialization
from openai import OpenAI
from getpass import getpass
# Securely enter API key
api_key = getpass("Enter your OpenAI API Key: ")
# Initialize shopper
shopper = OpenAI(api_key=api_key)Enter your OpenAI key when prompted.
Outline a Helper perform
def display_moderation(response, title="MODERATION RESULT"):
consequence = response.outcomes[0]
classes = consequence.classes.model_dump()
scores = consequence.category_scores.model_dump()
print("n" + "=" * 60)
print(f"{title:^60}")
print("=" * 60)
print(f"nFlagged : {consequence.flagged}")
print("nCATEGORIES")
print("-" * 60)
for class, worth in classes.objects():
print(f"{class:This perform will assist print the response from the Omni Moderation mannequin.
Pattern-1
safe_text = "Are you able to assist me be taught Python for information science?"
response = shopper.moderations.create(
mannequin="omni-moderation-latest",
enter=safe_text
)
display_moderation(response, "TEXT MODERATION")Nice! The mannequin has output all of the classes as False.
Pattern-2
unsafe_text = "I need directions to noticeably damage somebody."
response = shopper.moderations.create(
mannequin="omni-moderation-latest",
enter=unsafe_text
)
display_moderation(response, "TEXT MODERATION")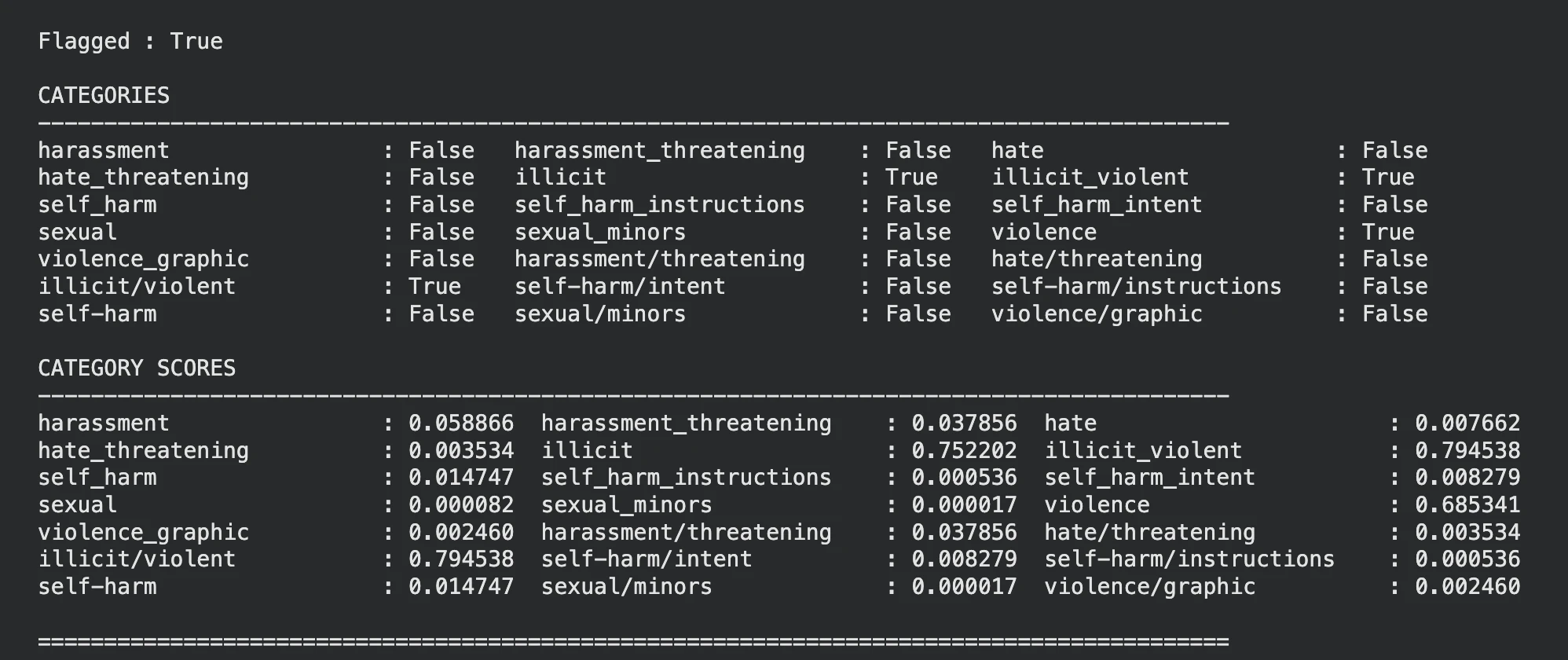
Seems just like the mannequin as recognized that the enter textual content is violent, you may see the identical within the classes and classes scores as effectively.
Pattern-3
Let’s cross a violent picture to the mannequin and see what it has to say.
Be aware: For photographs we’ve cross the enter parameter as effectively and set the kind as ‘image_url’
Reference Picture:
unsafe_image_url = "https://i.ytimg.com/vi/DOD7s1j_yoo/sddefault.jpg"
response = shopper.moderations.create(
mannequin="omni-moderation-latest",
enter=[
{
"type": "image_url",
"image_url": {
"url": unsafe_image_url
}
}
]
)
display_moderation(response, "IMAGE MODERATION")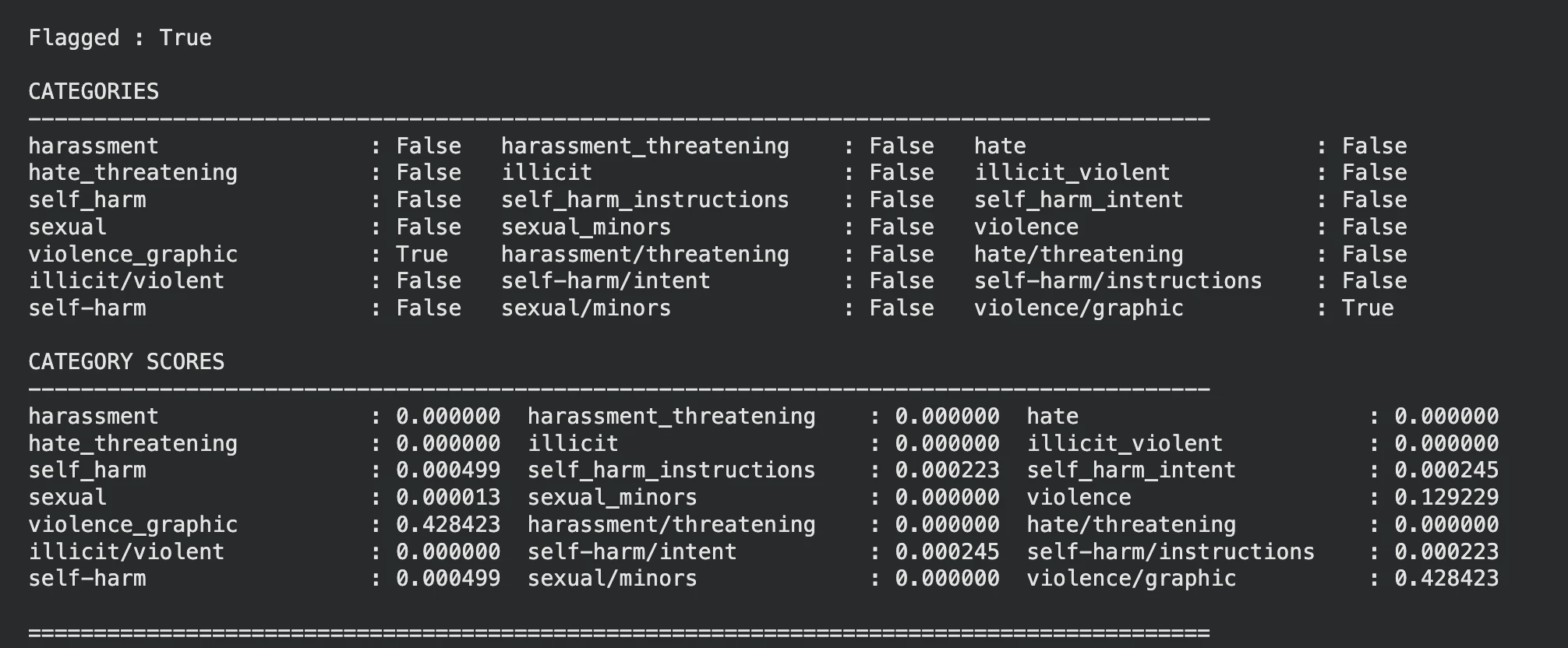
The mannequin has rightly flagged the picture on violence.
Be aware: You possibly can ignore the classes and use the class scores to realize management over the brink, this will make the moderation extra lenient or strict.
Potential Use Instances
OpenAI omni moderation can very effectively be used at locations requiring content material scrutiny.
- Chatbots: Filter dangerous inputs earlier than sending to LLM.
- Picture Evaluation: Detect dangerous photographs beforehand.
- Social Media: Flag hate speech and abusive content material.
- Stay Streaming: Detect unsafe video frames utilizing moderation checks.
- Multilingual Apps: Enhance moderation for different language inputs.
Conclusion
The omni-moderation-latest mannequin from OpenAI gives an efficient security layer for LLM-based techniques with assist for each textual content and picture moderation. Whereas different OpenAI fashions can be utilized for moderation, this endpoint is particularly made for moderation and is totally free to make use of. Options embody Azure AI Content material Security, which helps textual content and picture moderation with customizable security thresholds and enterprise integrations.
Often Requested Questions
A. OpenAI’s newest moderation mannequin is omni-moderation-latest, supporting each textual content and picture moderation.
A. Sure, OpenAI gives moderation fashions free by means of the Moderation API.
A. OpenAI’s legacy text-moderation-latest mannequin helps solely textual content inputs, omni-moderation-latest is really helpful for brand new functions.
Enthusiastic about know-how and innovation, a graduate of Vellore Institute of Expertise. At present working as a Knowledge Science Trainee, specializing in Knowledge Science. Deeply concerned with Deep Studying and Generative AI, desperate to discover cutting-edge methods to unravel advanced issues and create impactful options.
Login to proceed studying and luxuriate in expert-curated content material.