
{kind=link}
There are a number of dimensions we normally wish to obtain and monitor in our codebases: Practical correctness (works as supposed), architectural health (is quick/safe/usable sufficient), and maintainability. I outline maintainability right here as making it straightforward and low danger to alter the codebase over time – also referred to as “inside high quality”. So I do not solely need to have the ability to make adjustments rapidly at the moment, but in addition sooner or later. And I do not wish to fear about introducing bugs or degradation of health each time I make a change – or have AI make a change. I normally see the primary indicators of cracks within the maintainability of an AI-generated codebase when the variety of information modified for a small adjustment will increase. Or when adjustments begin breaking issues that used to work.
Inner high quality issues have an effect on AI brokers in comparable ways in which they have an effect on human builders. An agent working in a tangled codebase may look within the mistaken place for an present implementation, create inconsistencies as a result of it has not observed a replica, or be pressured to load extra context than a activity ought to require.
On this article, I describe my experimentation with numerous sensors that assist us and AI mirror on the maintainability of a codebase, and what I discovered from that.
The appliance
I am engaged on an inside analytics dashboard for neighborhood managers that reads chat house exercise, engagement, and demographic information from a mix of APIs and presents the info in an online frontend.
Determine 1:
The instance app: net UI, service layer, and exterior APIs.
The tech stack is a TypeScript, NextJS, and React. The backend reads and joins information from the APIs. The appliance has been round for some time, however for the sake of those experiments I rebuilt it with AI from scratch.
There are hardly any guides (e.g. markdown information) for AI about code high quality and maintainability current, I needed to see how nicely it may well do exactly by counting on sensor suggestions.
Overview of all sensors used
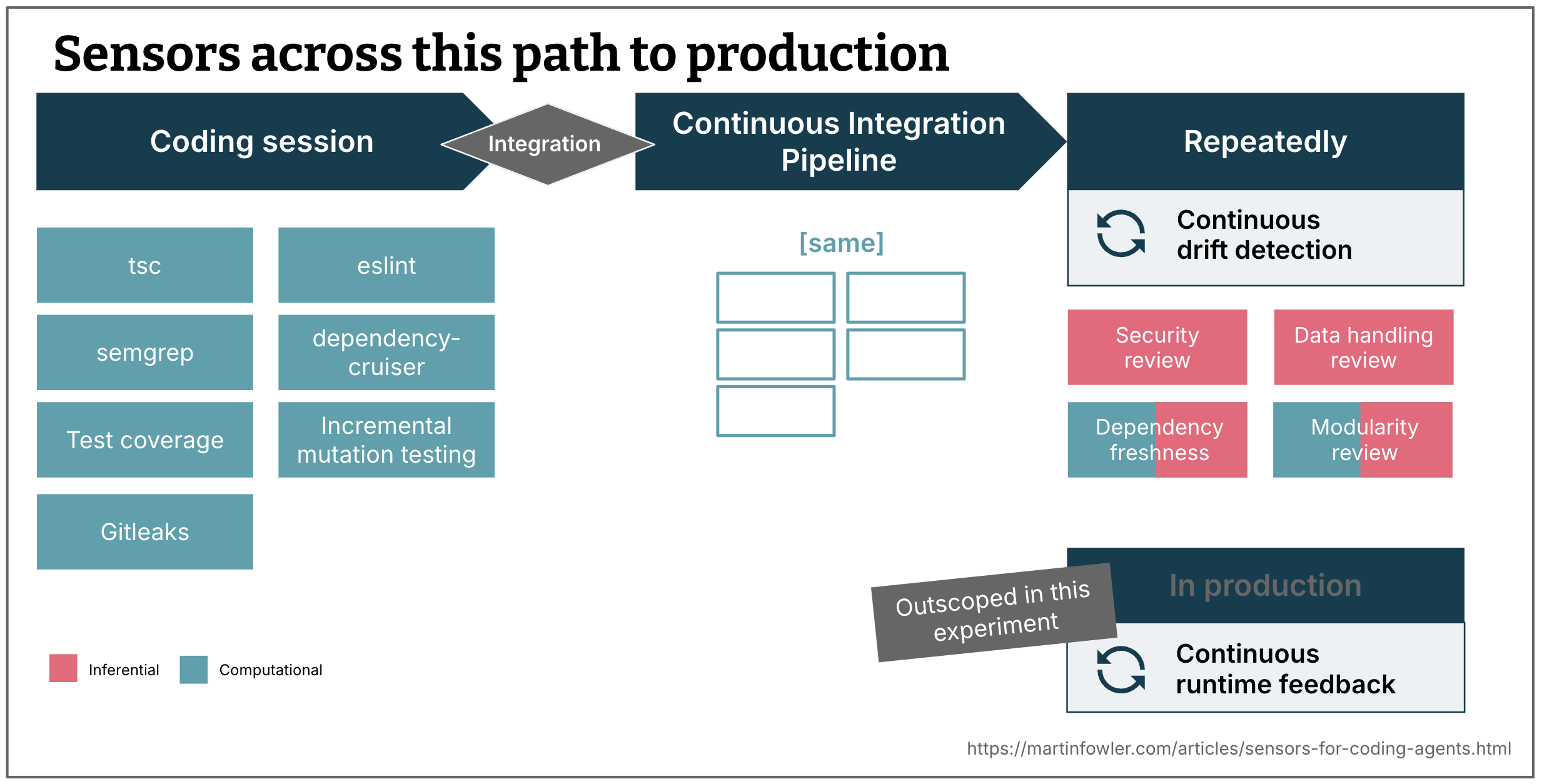
Determine 2:
The place sensors can run: throughout the preliminary coding session, within the pipeline, on a schedule, and in manufacturing.
That is an summary of the sensors I arrange throughout the trail to manufacturing.
Throughout coding session
Sensors that run constantly alongside the agent to supply quick suggestions.
- Sort checker (computational)
- ESLint (computational)
- Semgrep, SAST device prescribed by our inside AppSec staff (computational)
- dependency-cruiser, runs structural guidelines to examine inside module dependencies (computational)
- Check suite outcomes together with take a look at protection (computational – although the take a look at suite is generated by AI, subsequently created in an inferential approach)
- Incremental mutation testing (computational)
- GitLeaks runs as a part of the pre-commit hook, I think about it to be a sensor as nicely, as it is going to give the agent suggestions when it tries to commit (computational)
After integration – pipeline
The identical computational sensors run once more in CI. The in-session sensors give the agent early suggestions throughout growth. The CI pipeline confirms the outcome on clear infrastructure and after integration.
Repeatedly
Sensors that run on a slower cadence to detect drift that accumulates over time, fairly than errors that happen within the second.
- A safety overview, immediate derived from our AppSec guidelines for inside purposes (inferential)
- An information dealing with overview, immediate describes issues like “no consumer names ought to ever be despatched to the online frontend” (inferential)
- Dependency freshness report, which runs a script first to get the age and exercise of the library dependencies, after which has AI create a report with suggestions about potential upgrades, deprecations, and so forth (computational and inferential)
- Modularity and coupling overview (computational and inferential)
With this context out of the way in which, let’s dive into the primary class of sensors.
Base harnesses and fashions
All through constructing the applying, I used a mixture of Cursor, Claude Code, and OpenCode (in that order of frequency). My default mannequin was normally Claude Sonnet, for a number of the planning and evaluation duties I used Claude Opus, and for implementation duties I regularly used Cursor’s composer-2 mannequin.
Static code evaluation: Fundamental linting
I am going to begin with my learnings from utilizing ESLint on this utility. Fundamental linting instruments like ESLint principally goal maintainability danger on the stage of particular person information and features.
Guidelines for typical AI shortcomings
In my expertise, the AI failure modes which can be essentially the most low-hanging fruit for static code evaluation are
- Max variety of arguments for features
- File size
- Perform size
- Cyclomatic complexity
Nevertheless, these weren’t even lively in ESLint’s default preset, I needed to configure maximums for them first. Hopefully, static evaluation instruments will evolve to supply higher presets for utilization with AI. A little bit of analysis exhibits that individuals are additionally beginning to publish ESLint plugins with rule units which can be particularly concentrating on recognized agent failure modes, like this one by Manufacturing unit, with guidelines about issues like requiring take a look at information or structured logging.
Steering for self-correction
A sensor is supposed to offer the agent suggestions in order that it may well self-correct. Ideally, we wish to give the agent further context for that self-correction – an excellent form of immediate injection. To try this, I constructed a customized ESLint formatter to override a number of the default messages – with the assistance of AI in fact, naturally.
Right here is an instance of my steering for the no-explicit-any warning.
We wish issues to be typed to make it simpler to keep away from errors, particularly for key ideas. However we additionally wish to keep away from cluttering our codebase with pointless varieties. Make a judgment name about this. In case you select to not introduce a sort, suppress it with: // eslint-disable-next-line @typescript-eslint/no-explicit-any -- (give purpose why)`,
Managing warnings – now extra possible?
Static code evaluation has been round for a very long time, and but, groups typically did not use it persistently, even once they had it arrange. One of many causes for that’s the administration overhead that comes with it. Efficient use of this evaluation requires a staff to maintain a “clear home”, in any other case the metrics simply grow to be noise. Particularly warnings just like the no-explicit-any instance above are tough, since you do not at all times wish to repair them – it relies upon. And suppressing them one after the other has at all times felt tedious, and like noise within the code.
With coding brokers, we would now have an opportunity at that clear baseline. Within the steering textual content above, the agent is informed to make a judgment name, and allowed to suppress a warning within the code. This retains the suppressions manageable, seen and reviewable.
For thresholds, like the utmost variety of strains, or the utmost allowed cyclomatic complexity, I informed the agent within the lint message that it could barely enhance the thresholds if it thinks {that a} refactoring is pointless or inconceivable in a selected case. This does not suppress the brink perpetually, simply will increase it, in order that the rule fires once more if it will get even worse sooner or later. Constraints are preserved with out forcing a binary suppress-or-comply alternative.
Observations
- Trying on the exceptions AI created (suppressed warnings, elevated thresholds) was an excellent level to begin my code overview.
- AI regularly determined to extend the cyclomatic complexity threshold, however steered good refactorings after I nudged it additional. It was the one class the place it did that, and I later found that I did not have a self-correction steering in place for this one, so there was no specific instruction saying {that a} threshold enhance must be absolutely the exception. That is an indicator that the customized lint messages can certainly make fairly a distinction.
- Generally I wish to deal with guidelines in a different way in numerous elements of the code. Let’s take
no-console, telling AI off when it makes use ofconsole.log. Within the backend, I need it to make use of a logger part as an alternative. Within the frontend, I would wish to not use direct logging in any respect, or on the very least I would like to make use of a special logging part. That is one other instance of the ability of the self-correction steering, and the place AI might help with semantic judgment and administration of research warnings. - I used to be watching out for examples of trade-offs between guidelines. The one one I’ve seen to this point was created by the
max-linesandmax-lines-per-functionguidelines. I’ve seen AI do fairly a little bit of helpful refactoring and breakdown into smaller features and elements because of this sensor suggestions. Nevertheless, within the React frontend, I am seeing a worrying development of elements with tons and many properties because of passing values by means of a rising chain of smaller and smaller elements. I have never obtained helpful observations but about how good AI is perhaps at making constant selections between tradeoffs like that.
Primary takeaways
Total, I used to be positively shocked by what number of issues I can cowl with static evaluation. I needed to remind myself a number of instances why it has been considerably underused previously, and what has modified: The fee-benefit steadiness. Value is decreased as a result of it is less expensive to create customized scripts and guidelines with AI. And the profit has additionally elevated: the evaluation outcomes assist me get a primary sense of numerous hygiene components that would not even occur that a lot after I write code myself, so I can get widespread AI errors out of the way in which.
Nevertheless, I am unable to assist however surprise if this will additionally result in a false sense of safety and an phantasm of high quality. In spite of everything, another excuse why linters like this have been much less used previously is that they’ve limits, and we have now been cautious of utilizing them as a simplified indicator of high quality. There are many extra semantic features of high quality that static evaluation can’t catch, it stays to be seen if AI can adequately fill that hole in partnership with these instruments. I additionally found new supposed points within the code each time I activated a brand new algorithm. It was at all times a mixture of irrelevant issues and issues that truly matter. So I fear about suggestions overload for the agent, sending it right into a spiral of over-engineered refactorings.