
{kind=link}
Within the gaming business, each millisecond counts. To drive in-game personalization, gas suggestion engines, and make dynamic content material scheduling selections, platforms should course of session information for thousands and thousands of world gamers with sub-second latency.
Right this moment, assembly these ultra-low latency necessities not requires a disjointed structure with a number of engines. On this weblog, we discover a real-world implementation of Apache Spark Actual-Time Mode. By leveraging the brand new transformWithState operator for complicated stateful logic, we exhibit how Spark delivers end-to-end millisecond efficiency. Uncover how your group can speed up growth and construct mission-critical operational functions utilizing the acquainted Structured Streaming ecosystem.
Use Case Overview
From Sport Begin to Sport Finish – Why Session Monitoring Issues
For gaming platforms, understanding which gadgets are lively and for a way lengthy is not simply an infrastructure concern — it drives the enterprise. Actual-time session information powers personalised in-game experiences, fuels suggestion engines, informs content material scheduling selections, and supplies gadget well being alerts throughout thousands and thousands of consoles and PCs. Operations groups use it to implement parental controls and detect irregular session patterns.
Session Occasion Fundamentals
Session occasions from each consoles and PCs stream into Kafka subjects. Every occasion carries a tool ID and a session ID. The gadget ID identifies the console or PC; the session ID identifies the gaming session. Just one session will be lively per gadget at any time.
The pipeline handles 4 eventualities:
- Session Begin (GameStart): A begin occasion arrives. The pipeline shops the session ID and begin time, emits a SessionActive occasion, and registers a 30-second processing-time timer. If one other session was already lively for that gadget, it ends the outdated one first.
- Session Heartbeat (Energetic): The timer fires each 30 seconds. The pipeline calculates now – start_time, emits a SessionActive heartbeat with the present period, and re-registers the timer.
- Session Finish (GameEnd): An finish occasion arrives matching the lively session. The pipeline emits a SessionEnd with the ultimate period and clears the state.
- Session Timeout (GameSessionTimeout): The timer fires and the calculated period exceeds a configurable most. As a substitute of emitting a heartbeat, the pipeline emits a SessionEnd with a timeout purpose and cleans up the state.
Why Spark with Actual-Time Mode is a recreation changer
Spark Structured Streaming in micro-batch mode can deal with stateful sessionization, however when the use case calls for sub-second precision for each enter processing and timer-driven output, micro-batch falls brief. Up to now, that hole pushed groups towards managing a further specialised engines or constructing customized options.
With Apache Flink: State administration and timers will be carried out, however adopting Flink means adopting a whole parallel ecosystem: a separate cluster, state backend, deployment mannequin, monitoring stack, and codebase, all alongside the Databricks Platform. The result’s infrastructure fragmentation, operational complexity, and the price of working and staffing a second streaming engine.
With customized in-house options: Some groups construct their very own sessionization service — for instance, an Akka-based actor system the place every gadget will get an actor that manages session state, timers, and heartbeat emission. These carry the identical infrastructure and operational overhead as Flink, with a further problem: they do not scale. Distributing thousands and thousands of stateful actors throughout nodes is one thing you must engineer your self. These programs work initially, however over time find yourself in upkeep mode — steady sufficient to run, however not simply extendable.
Right this moment, Actual-Time Mode closes this hole for patrons — delivering sub-second precision with the identical Spark APIs groups already use, all in a single unified engine.
Actual-Time Mode with transformWithState
transformWithState is a next-generation operator in Spark Structured Streaming that makes complicated stateful processing versatile and scalable. Key options embrace object-oriented state administration, composite information sorts, timer-driven logic, automated TTL assist, and schema evolution. Mixed with Actual-Time Mode, it delivers sub-second precision for each enter processing and timer-driven output.
The gaming sessionization use case calls for two issues:
- Reactive processing: dealing with session begins and ends as they arrive.
- Proactive output: producing a heartbeat for each lively session on a schedule, impartial of incoming information
transformWithState delivers each in a single StatefulProcessor class with two devoted strategies.
handleInputRows() reacts to incoming Kafka occasions — processing session begins and session ends, sustaining sessionization state as occasions arrive.
handleExpiredTimer() handles the whole lot that occurs in between — firing to supply proactive output like heartbeats and timeouts, impartial of whether or not any new information has arrived.
How It Works: Constructing a Actual-Time Gaming Sessionization Pipeline
Pipeline Structure Overview
- Occasion Ingestion: Session occasions (begins and ends) from consoles and PCs arrive on Kafka subjects. Every occasion is parsed, and a deviceId is derived from the device-specific identifier.
- Stateful Grouping: The stream is grouped by deviceId — guaranteeing all occasions for a given gadget are routed to the identical stateful processor occasion.
- Course of: transformWithState applies the Sessionization processor, which makes use of a MapState keyed by session ID to trace the lively session per gadget. When a session begin arrives, handleInputRows() shops the session state, emits a SessionActive occasion, and registers the primary 30-second timer. From that time on, handleExpiredTimer() takes over — emitting heartbeats each 30 seconds and checking for timeouts. When a session finish occasion arrives, handleInputRows() picks it again up — emitting a SessionEnd with the ultimate period, clearing the state, and stopping the timer loop.
- Output: Processed session occasions — begins, heartbeats, ends, and timeouts — are written as JSON to an output Kafka subject, prepared for downstream consumption.
Implementation Deep-Dive
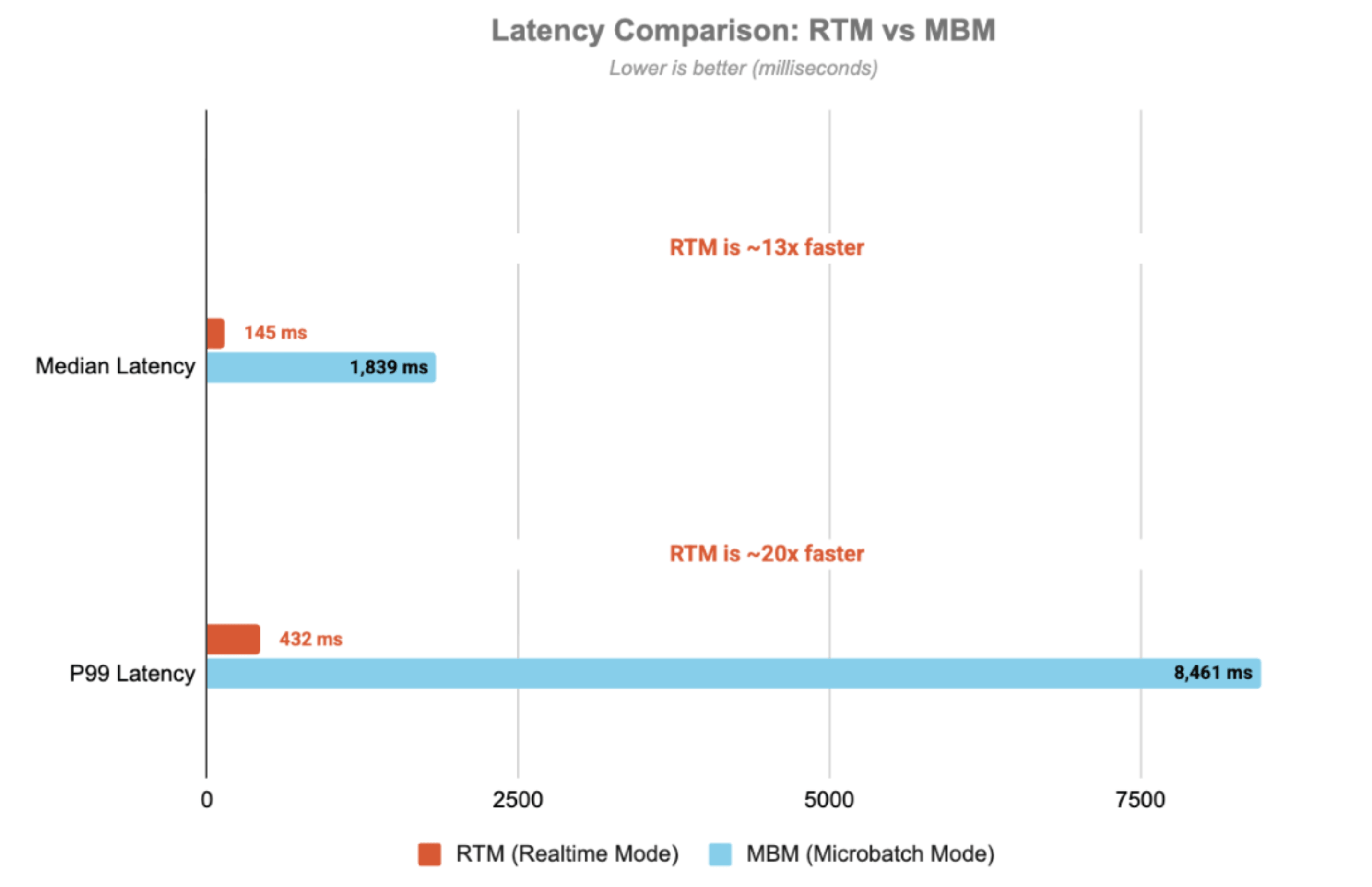
For an in depth walkthrough of the structure, code implementation, and manufacturing issues, see this companion weblog — the place we step by the StatefulProcessor code, timer lifecycle, state administration patterns, and monitoring with StreamingQueryListener. The next outcomes illustrate the throughput and latency traits of the pipeline, highlighting the numerous latency variations between micro-batch mode (MBM) and Actual-Time Mode (RTM):
Throughput
To validate the pipeline below real looking load, we examined with the next sustained throughput:
|
Metric (per minute) |
Worth |
|
Enter occasions (session begins + ends) |
~500K |
|
Variety of Energetic classes |
~4M |
|
Heartbeat data emitted |
~8M |
|
Enter-to-output amplification |
~16x |
The overwhelming majority of output shouldn’t be triggered by incoming information — it is generated totally by handleExpiredTimer(), proactively emitting heartbeats on a schedule.
Latency
Latency is measured end-to-end — from Kafka enter subject timestamp to output subject timestamp. With Actual-Time mode, the pipeline achieves 432ms p99 latency — 20x sooner than micro-batch mode.
Conclusion
Use circumstances like gaming sessionization require pipelines that transcend processing incoming occasions — proactively emitting heartbeats on a schedule, monitoring thousands and thousands of concurrent classes and managing state effectively. The sample is not restricted to gaming. Any workload that wants timer-driven output — IoT heartbeats, session monitoring, real-time alerting, tools monitoring — will be constructed the identical manner.
Timers in transformWithState make this attainable. A single StatefulProcessor class handles your entire session lifecycle — reactive enter processing and proactive timer-driven output. Paired with Actual-Time Mode, enter data are processed and timers hearth with sub-second precision — not on the subsequent batch interval, however now. All inside Databricks, and not using a second engine.
In case you’re already working Structured Streaming pipelines in micro-batch mode and reaching for a second engine to hit decrease latency, strive Actual-Time Mode first. Switching is a single set off change — no rewrites, no replatforming:
Strive it your self:
Actual-Time mode is now Usually Out there.