
{kind=link}
When you’re following AI Brokers, you then might need seen that LangChain has created a pleasant ecosystem with LangChain, LangGraph, LangSmith & LangServe. Leveraging these, we are able to construct, deploy, consider, and monitor Agentic AI methods. Whereas constructing an AI Agent, I simply thought to myself, “Why not present a easy demo to indicate the intertwined working of LangGraph & LangSmith?”. That is gonna be useful as AI Brokers typically want a number of LLM calls and now have greater prices related to them. This combo will assist observe the bills and in addition consider the system utilizing customized datasets. With none additional ado, let’s dive in.
LangGraph for AI Brokers
Merely put, AI Brokers are LLMs with the aptitude to suppose/cause and will entry instruments to handle their shortcomings or achieve entry to real-time data. LangGraph is an Agentic AI framework primarily based on LangChain to construct these AI Brokers. LangGraph helps construct graph-based Brokers; additionally, the creation of Agentic workflows is simplified with many inbuilt features already current within the LangGraph/LangChain libraries.
Learn extra: What’s LangGraph?
What’s LangSmith?
LangSmith is a monitoring and analysis platform by LangChain. It’s framework-agnostic, designed to work with any Agentic framework, resembling LangGraph, and even with Brokers constructed fully from scratch. LangSmith may be simply configured to hint the runs and in addition observe the bills of the Agentic system. It additionally helps working experiments on the system, like altering the immediate and fashions within the system, and evaluating the outcomes. It has predefined evaluators like helpfulness, correctness, and hallucinations. You may as well select to outline your individual evaluators. Let’s have a look at the LangSmith platform to get a greater thought of it.
Learn extra: Final Information to LangSmith
The LangSmith Platform
Let’s first join/check in to take a look at the platform: https://www.langchain.com/langsmith
That is how the platform appears with a number of tabs:
- Tracing Tasks: Retains a observe of a number of tasks together with their traces or units of runs. Right here, the prices, errors, latency, and lots of different issues are tracked.
- Monitoring: Right here you may set alerts to warn you, for example, if the system fails or the latency is above the set threshold.
- Dataset & Experiments: Right here, you may run experiments utilizing human-crafted datasets or use the platform to create AI-generated datasets for testing your system. You may as well change your mannequin to see how the efficiency varies.
- Prompts: Right here you may retailer a couple of prompts and later change the wording or sequence of directions to see how your outcomes are altering.
LangSmith in Motion
Be aware: We’ll solely construct easy brokers for this tutorial to deal with the LangSmith aspect of issues.
Let’s construct a basic math expression-solving agent that makes use of a easy instrument after which allow traceability. After which we’ll verify the LangSmith dashboard to see what may be tracked utilizing the platform.
Getting the API keys:
- Go to the Langsmith dashboard and click on on the ‘Setup Observability’ Button. Then you definately’ll see this display screen. https://www.langchain.com/langsmith
Now, click on on the ‘Generate API Key’ choice and maintain the LangSmith key useful.
- Now go to Google AI Studio to get your palms on the Gemini API key: https://aistudio.google.com/api-keys
Click on on ‘Create API key’ on the right-top and create a mission if it doesn’t exist already, and maintain the important thing useful.
Python Code
Be aware: I’ll be utilizing Google Colab for working the code.
Installations
!pip set up -q langgraph langsmith langchain
!pip set up -q langchain-google-genaiBe aware: Ensure that to restart the session earlier than persevering with from right here.
Setting the surroundings
Go the API keys when prompted.
from getpass import getpass
LANGCHAIN_API_KEY=getpass('Enter LangSmith API Key: ')
GOOGLE_API_KEY=getpass('Enter Gemini API Key: ')
import os
os.environ['LANGCHAIN_TRACING_V2'] = 'true'
os.environ['LANGCHAIN_API_KEY'] = LANGCHAIN_API_KEY
os.environ['LANGCHAIN_PROJECT'] = 'Testing'Be aware: It’s really useful to trace completely different tasks with completely different mission names; right here, I’m naming it ‘Testing’.
Organising and working the agent
- Right here, we’re utilizing a easy instrument that the agent can use to resolve math expressions
- We’re utilizing the in-built
create_react_agentfrom LangGraph, the place we’ve got to outline the mannequin, give entry to instruments, and we’re good to go.
from langgraph.prebuilt import create_react_agent
from langchain_google_genai import ChatGoogleGenerativeAI
def solve_math_problem(expression: str) -> str:
"""Clear up a math drawback."""
attempt:
# Consider the mathematical expression
outcome = eval(expression, {"__builtins__": {}})
return f"The reply is {outcome}."
besides Exception:
return "I could not clear up that expression."
# Initialize the Gemini mannequin with API key
mannequin = ChatGoogleGenerativeAI(
mannequin="gemini-2.5-flash",
google_api_key=GOOGLE_API_KEY
)
# Create the agent
agent = create_react_agent(
mannequin=mannequin,
instruments=[solve_math_problem],
immediate=(
"You're a Math Tutor AI. "
"When a person asks a math query, cause by means of the steps clearly "
"and use the instrument `solve_math_problem` for numeric calculations. "
"All the time clarify your reasoning earlier than giving the ultimate reply."
),
)
# Run the agent
response = agent.invoke(
{"messages": [{"role": "user", "content": "What is (12 + 8) * 3?"}]}
)
print(response)Output:
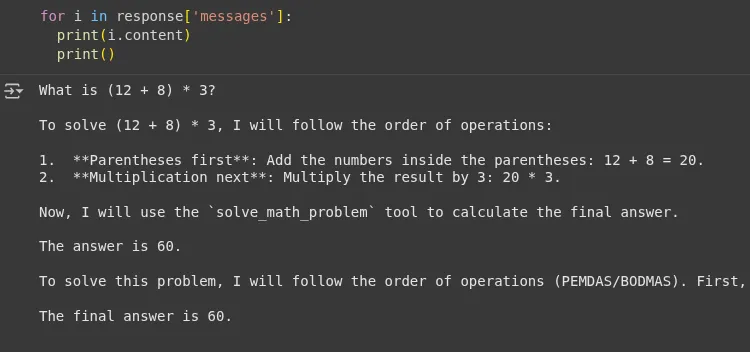
We will see that the agent used the instrument’s response ‘The reply is 60’ and didn’t hallucinate whereas answering the query. Now let’s verify the LangSmith dashboard.
LangSmith Dashboard
Tracing Tasks tab

We will see that the mission has been created with the title ‘testing’; you may click on on it to see detailed logs.

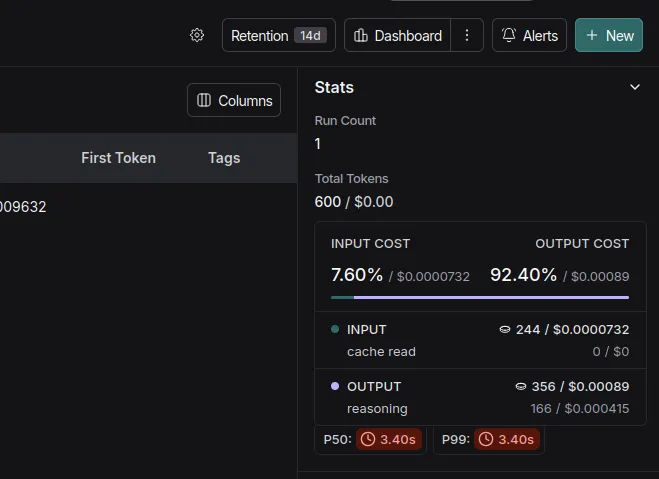
Right here it exhibits the run-wise:
- Whole Tokens
- Whole Value
- Latency
- Enter
- Output
- Time when the code was executed
Be aware: I’m utilizing the free tier of Gemini right here, so I can use the important thing freed from value based on the every day limits.
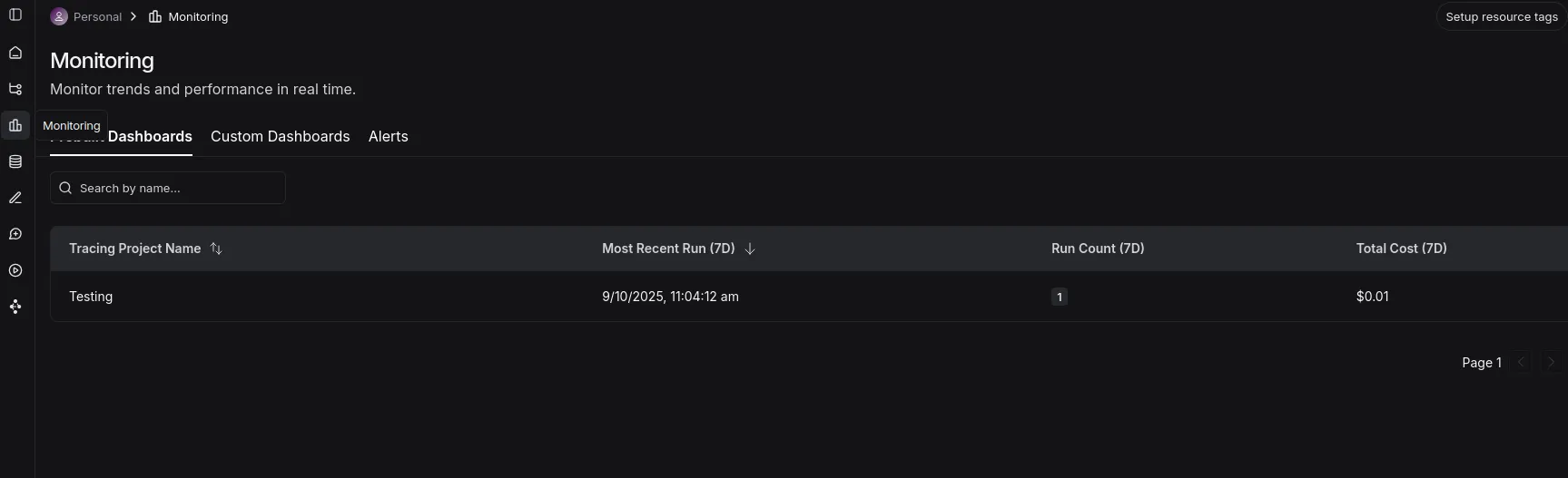
Monitoring tab
- Right here you may see a dashboard with the tasks, runs, and whole prices.
LLM as a choose
LangSmith permits the creation of a dataset utilizing a easy dictionary with enter and output keys. This dataset with the anticipated output can be utilized to guage an AI system’s generated outputs on metrics like helpfulness, correctness, and hallucinations.
We’ll use the same math agent, create the dataset, and consider our agentic system.
Be aware: I’ll be utilizing OpenAI API (gpt-4o-mini) for the demo right here, that is to keep away from API Restrict points with the free-tier Gemini API.
Installations
!pip set up -q openevals langchain-openai Surroundings Setup
import os
from google.colab import userdata
os.environ['OPENAI_API_KEY']=userdata.get('OPENAI_API_KEY')Defining the Agent
from langsmith import Consumer, wrappers
from openevals.llm import create_llm_as_judge
from openevals.prompts import CORRECTNESS_PROMPT
from langchain_openai import ChatOpenAI
from langgraph.prebuilt import create_react_agent
from langchain_core.instruments import instrument
from typing import Dict, Listing
import requests
# STEP 1: Outline Instruments for the Agent =====
@instrument
def solve_math_problem(expression: str) -> str:
"""Clear up a math drawback."""
attempt:
# Consider the mathematical expression
outcome = eval(expression, {"__builtins__": {}})
return f"The reply is {outcome}."
besides Exception:
return "I could not clear up that expression."
# STEP 2: Create the LangGraph ReAct Agent =====
def create_math_agent():
"""Create a ReAct agent with instruments."""
# Initialize the LLM
mannequin = ChatOpenAI(mannequin="gpt-4o-mini", temperature=0)
# Outline the instruments
instruments = [solve_math_problem]
# Create the ReAct agent utilizing LangGraph's prebuilt operate
agent = create_react_agent(
mannequin=mannequin,
instruments=[solve_math_problem],
immediate=(
"You're a Math Tutor AI. "
"When a person asks a math query, cause by means of the steps clearly "
"and use the instrument `solve_math_problem` for numeric calculations. "
"All the time clarify your reasoning earlier than giving the ultimate reply."
),
)
return agentCreating the dataset
- Let’s create a dataset with easy and exhausting math expressions that we are able to later use to run experiments.
consumer = Consumer()
dataset = consumer.create_dataset(
dataset_name="Math Dataset",
description="Onerous numeric + blended arithmetic expressions to guage the solver agent."
)
examples = [
# Simple check
{
"inputs": {"question": "12 + 7"},
"outputs": {"answer": "The answer is 19."},
},
{
"inputs": {"question": "100 - 37"},
"outputs": {"answer": "The answer is 63."},
},
# Mixed operators and parentheses
{
"inputs": {"question": "(3 + 5) * 2 - 4 / 2"},
"outputs": {"answer": "The answer is 14.0."},
},
{
"inputs": {"question": "2 * (3 + (4 - 1)*5) / 3"},
"outputs": {"answer": "The answer is 14.0."},
},
# Large numbers & multiplication
{
"inputs": {"question": "98765 * 4321"},
"outputs": {"answer": "The answer is 426,373,565."},
},
{
"inputs": {"question": "123456789 * 987654321"},
"outputs": {"answer": "The answer is 121,932,631,112,635,269."},
},
# Division, decimals, rounding
{
"inputs": {"question": "22 / 7"},
"outputs": {"answer": "The answer is approximately 3.142857142857143."},
},
{
"inputs": {"question": "5 / 3"},
"outputs": {"answer": "The answer is 1.6666666666666667."},
},
# Exponents, roots
{
"inputs": {"question": "2 ** 10 + 3 ** 5"},
"outputs": {"answer": "The answer is 1128."},
},
{
"inputs": {"question": "sqrt(2) * sqrt(8)"},
"outputs": {"answer": "The answer is 4.0."},
},
# Edge / error / “unanswerable” cases
{
"inputs": {"question": "5 / 0"},
"outputs": {"answer": "I couldn’t solve that expression."},
},
{
"inputs": {"question": "abc + 5"},
"outputs": {"answer": "I couldn’t solve that expression."},
},
{
"inputs": {"question": ""},
"outputs": {"answer": "I couldn’t solve that expression."},
},
]
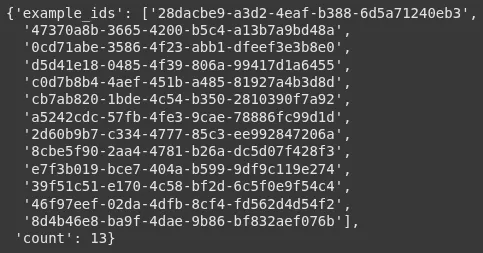
consumer.create_examples(
dataset_id=dataset.id,
examples=examples)Nice! We created a dataset with 13 information:
Defining the goal operate
- This operate invokes the agent and returns the response
def goal(inputs: Dict) -> Dict:
agent = create_math_agent()
agent_input = {
"messages": [{"role": "user", "content": inputs["question"]}]
}
outcome = agent.invoke(agent_input)
final_message = outcome["messages"][-1]
reply = final_message.content material if hasattr(final_message, 'content material') else str(final_message)
return {"reply": reply}Defining the Evaluator
- We use the pre-built
llm_as_judgeoperate and in addition import the immediate from the openevals library. - We’re utilizing 4o-mini for now to maintain the prices low, however a reasoning mannequin may be higher suited to this job.
def correctness_evaluator(inputs: Dict, outputs: Dict, reference_outputs: Dict) -> Dict:
evaluator = create_llm_as_judge(
immediate=CORRECTNESS_PROMPT,
mannequin="openai:gpt-4o-mini",
feedback_key="correctness",
)
eval_result = evaluator(
inputs=inputs,
outputs=outputs,
reference_outputs=reference_outputs
)
return eval_resultOperating the analysis
experiment_results = consumer.consider(
goal,
knowledge="Math Dataset",
evaluators=[correctness_evaluator],
experiment_prefix="langgraph-math-agent",
max_concurrency=2,
)Output:
A hyperlink will likely be generated after the run. On click on, you’ll be redirected to LangSmith’s ‘Datasets & Experiments’ tab, the place you may see the outcomes of the experiment.
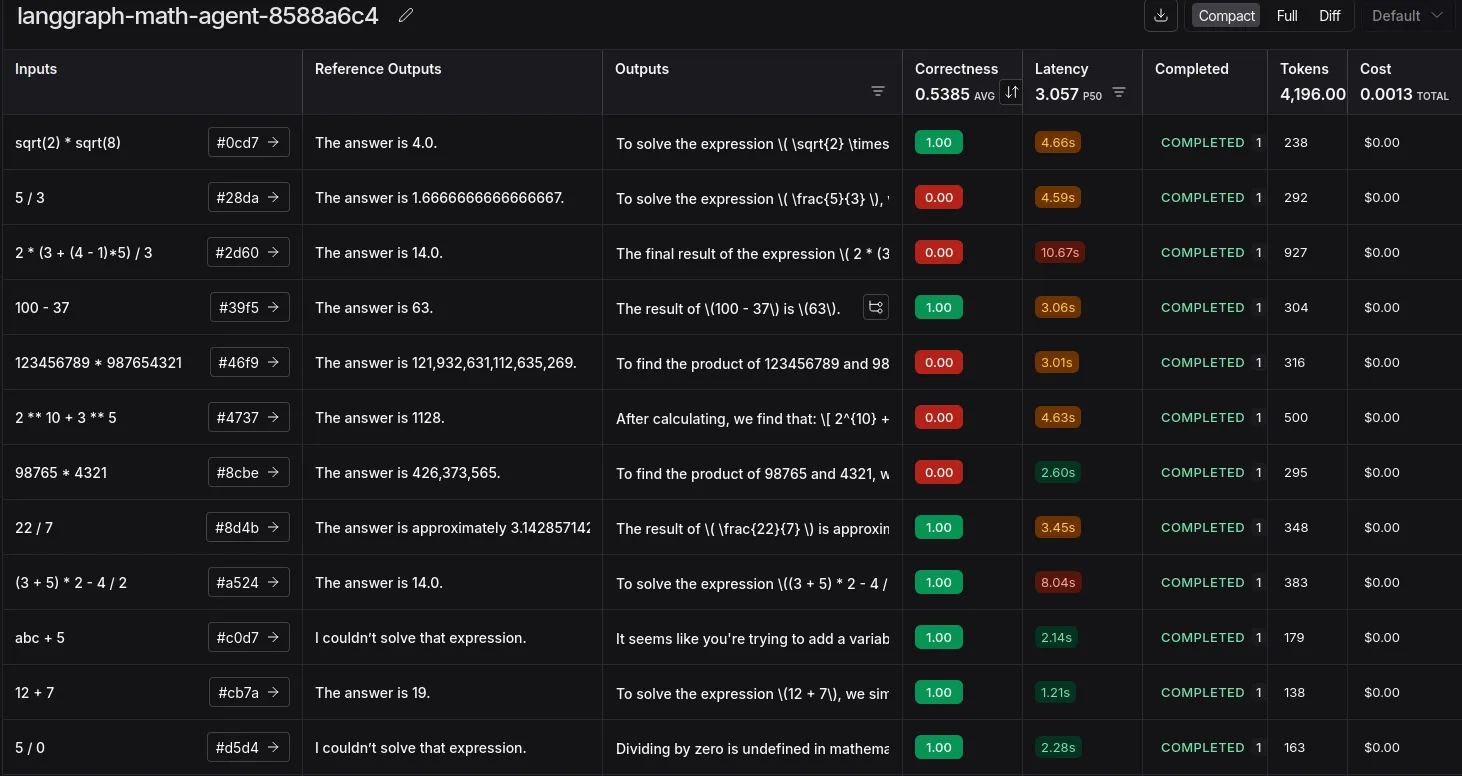
We now have efficiently experimented with utilizing LLM as a Decide. That is insightful when it comes to discovering edge instances, prices, and token utilization.
The errors listed here are largely mismatched because of using commas or the presence of lengthy decimals. This may be solved by altering the analysis immediate or attempting a reasoning mannequin. Or simplify including commas and guaranteeing decimal formatting on the instrument stage itself.
Conclusion
And there you will have it! We’ve efficiently proven the intertwined working of LangGraph for constructing our agent and LangSmith for tracing and evaluating it. This combo is extremely highly effective for monitoring bills and guaranteeing your agent performs as anticipated with customized datasets. Whereas we centered on tracing and experiments, LangSmith’s capabilities don’t cease there. You may as well discover highly effective options like A/B testing completely different prompts in manufacturing, including human-in-the-loop suggestions on to traces, and creating automations to streamline your debugging workflow.
Often Requested Questions
A. The -q (or –quiet) flag tells pip to be “quiet” throughout set up. It reduces the log output, making your pocket book cleaner by solely displaying necessary warnings or errors.
A. LangChain is finest for creating sequential chains of actions. LangGraph extends this by letting you outline advanced, cyclical flows with conditional logic, which is important for constructing subtle brokers.
A. No, LangSmith is framework-agnostic. You’ll be able to combine it into any LLM software to get tracing and analysis, even when it’s constructed from scratch utilizing libraries like OpenAI’s straight.
Keen about know-how and innovation, a graduate of Vellore Institute of Expertise. At present working as a Information Science Trainee, specializing in Information Science. Deeply taken with Deep Studying and Generative AI, wanting to discover cutting-edge strategies to resolve advanced issues and create impactful options.
Login to proceed studying and revel in expert-curated content material.