
{kind=link}
Guaranteeing buyer databases are all the time accessible is without doubt one of the most necessary issues we do in Lakebase. We’ve designed the system with redundancy at each stage, robotically failing over and recovering your database within the occasion of {hardware} or software program failures.
In a large-scale system, such unplanned failures are a statistical expectation, however for a person database, they’re not that frequent. For a person database, deliberate upkeep tends to trigger extra workload disruption. In any case, a typical database is patched extra often than it experiences {hardware} failure.
At present, practically each database supplier operates with upkeep home windows: intervals the place your database severs all lively connections and will get up to date and restarted in a course of that may take wherever from a couple of seconds to minutes. Whereas Lakebase permits you to schedule updates at a time that is optimum for you, it is nonetheless a quick interruption when it occurs.
We expect we will do higher. This weblog put up is the primary in a collection on how we’re leveraging the lakebase structure to remove the influence of deliberate upkeep totally. Our purpose: make model updates and safety patches utterly unnoticeable.
On this put up, we’ll cowl prewarming: a method that forestalls any efficiency degradation that follows a database restart. In future posts, we’ll focus on enhancements to the failover course of itself and extra optimizations that deliver us nearer to true zero-downtime patching.
The Drawback with Chilly Restarts
The problem with restarting PostgreSQL is that in-memory caches (particularly the buffer cache and native file cache) are misplaced. Although the database is again on-line in a short time (1 second @ P99), the workload could expertise a slowdown within the first minutes after restart – we noticed a ~70% discount in pgbench TPS. This is because of a low cache hit ratio whereas information is learn again from storage and the cache warms up. Whereas this would possibly look like solely a efficiency downside, it may be an availability concern if the slowdown is extreme sufficient that the database can not sustain with the workload and timeouts happen.
Strategies to handle this exist in Postgres: pg_prewarm can be utilized to heat up buffer caches. Nevertheless, this runs after a restart when the workload is already impacted. Streaming replication can be utilized to arrange a reproduction, which will be prewarmed earlier than failing over to it (selling it to main). Nevertheless, this requires making a full duplicate and punctiliously orchestrating the prewarming earlier than failover.
Prewarming on the Lakebase Structure
Within the lakebase structure, we mix stateless, elastic compute nodes with disaggregated, shared storage. The compute nodes make use of native caches to ship most efficiency with out sacrificing serverless properties. Whereas the cache faces the identical cold-start points outlined above, now we have extra choices with the Lakebase structure.
Since Lakebase’s Postgres compute replicas are stateless, we will spin them up and down on demand. We make the most of this and mix it with computerized prewarming on deliberate restarts to reduce the efficiency influence on the workload. That is the way it works:
- A brand new model of Lakebase’s Postgres compute picture turns into accessible. You obtain a notification and may schedule the restart for a time that works for you.
- Shortly earlier than the scheduled time, our management aircraft spins up a brand new Postgres compute within the background. You don’t see it, and also you’re not billed for it. The present main’s workload is unaffected.
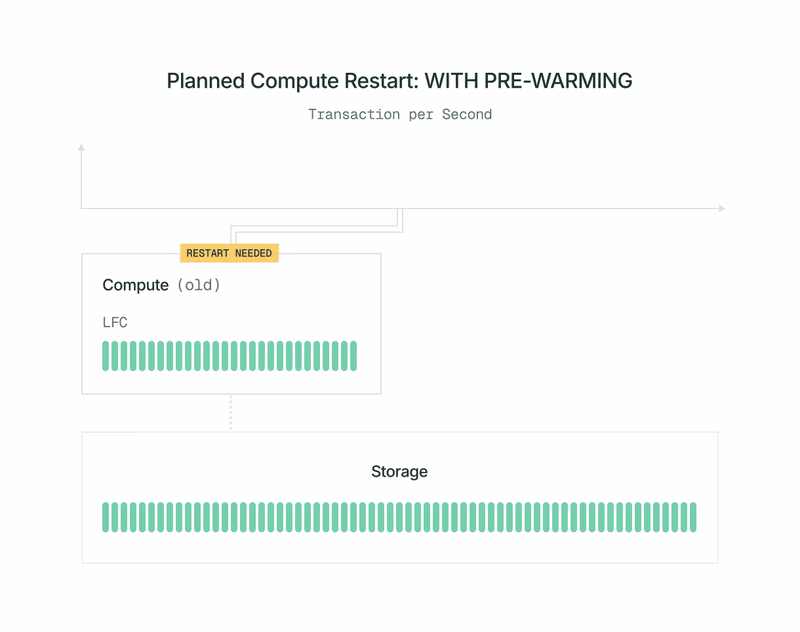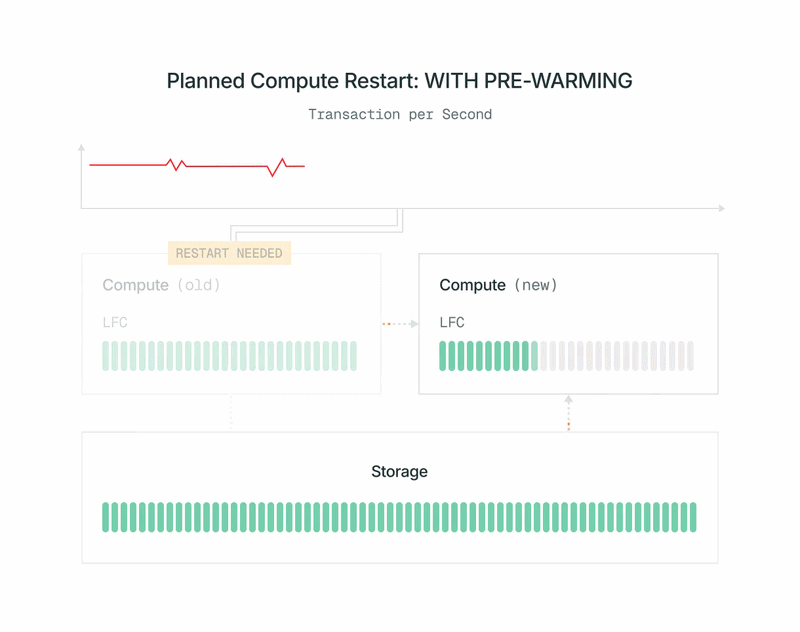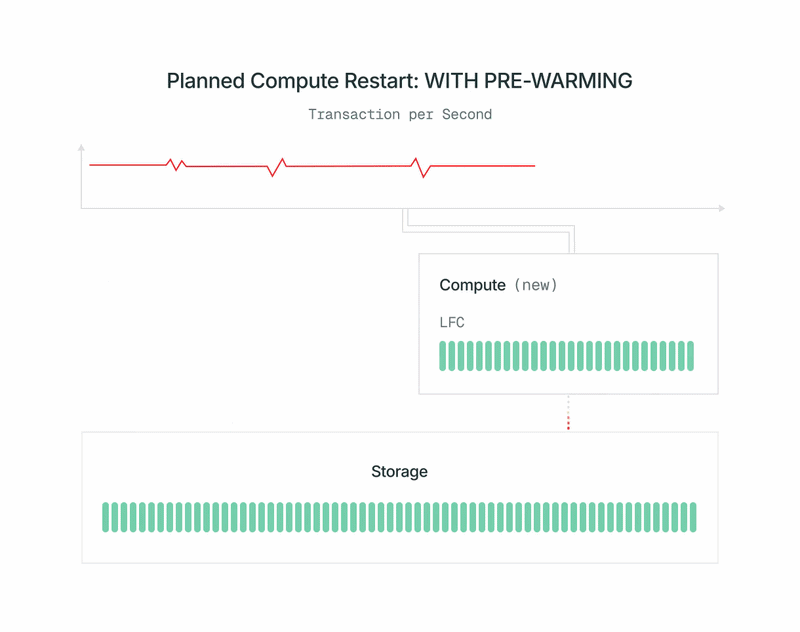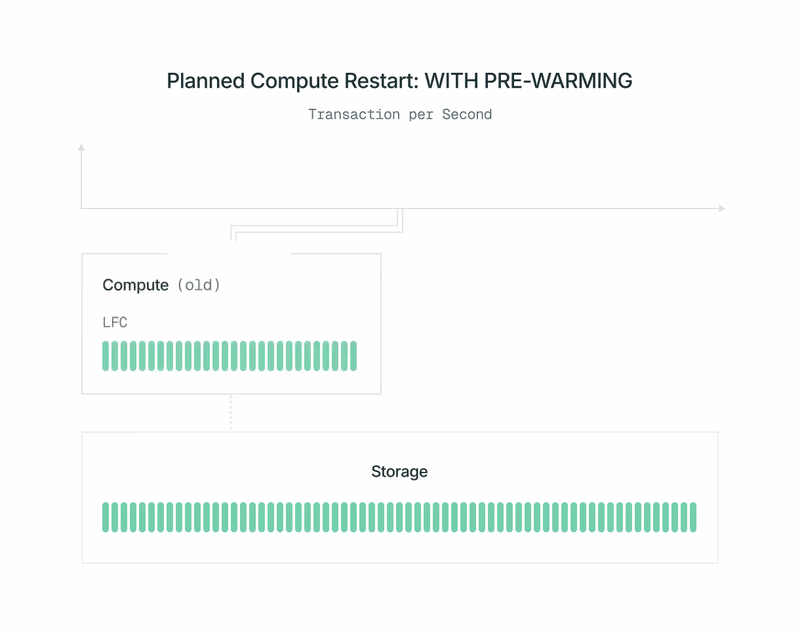
- An inventory of pages within the present main’s cache is shipped to the brand new compute. The brand new compute masses these pages into cache from our shared storage tier with out impacting the first.
- The brand new compute subscribes to the WAL (write-ahead log) to maintain its cache updated. For effectivity, in contrast to a traditional Postgres duplicate, it could ignore all WAL data that don’t have an effect on its cache. It will get the WAL from our Safekeepers, placing no further load on the first compute.
- When prewarming is full, we rapidly shut down the previous main, promote the brand new compute to main, and swap it in. Promotion makes use of the usual pg_promote from OSS Postgres and doesn’t restart the database server.
Earlier than:
After:
With the lakebase structure, you get this at no further value, with out paying for extra replicas. As of at present, all deliberate restarts of learn/write endpoints are carried out this manner with out you having to do something. Quickly we’ll be extending it to read-only endpoints as effectively.
Outcomes
To measure the influence of chilly caches, we ran 10 GB pgbench (scale issue 670) on a database whereas restarting it – first with prewarming enabled, then with out prewarming. The primary chart reveals a read-only workload (pgbench “choose solely”), whereas the second reveals a read-write workload (pgbench “easy replace”).


In each circumstances, we see that throughput recovers practically immediately with prewarming. With out prewarming, restoration is way slower whereas the chilly cache is warming up. The distinction is starkest for the read-only workload as a result of prewarming improves the cache hit ratio which helps reads proportionally greater than writes.