
{kind=link}
Immediately we’re asserting a serious replace that makes Agent Bricks Data Assistant each sooner and better high quality. Reply era time has dropped by 2x, and search time has dropped by greater than 3x, bringing Time To First Token (TTFT) to round two seconds.¹ Thus, Data Assistant customers will get noticeably sooner solutions throughout their use circumstances, with no reconfiguration required and no tradeoff in high quality.
These features are powered by Instructed-Retriever-1, a retrieval-specialized mannequin constructed for parallel test-time scaling. In contrast to commonplace agentic retrieval, the place an agent works sequentially and causes over every consequence earlier than deciding its subsequent step, our method followers this work out in parallel. Instructed-Retriever-1 is a single mannequin skilled for each retrieval levels: question era to extend recall and reranking to extend precision, run in parallel to maintain latency low. On this submit, we describe how this method leads to a Pareto-optimal efficiency, how we practice one mannequin to assist the complete retrieval pipeline, and the way we validate efficiency on real looking enterprise workloads.
Determine: On KARLBench, Data Assistant with Instructed-Retriever-1 improves each search latency and retrieval high quality.
1. Parallel Check-Time Scaling for Search
Our earlier analysis demonstrated that high quality can enhance with further test-time compute. Nonetheless, most agentic search methods right this moment spend that compute on sequential operations, like software calls, reason-act loops, and chain-of-thought reasoning. These strategies do enhance search high quality, however they arrive on the expense of considerably increased latency and value. For coaching Instructed-Retriever-1, we take a unique route: fairly than scaling compute sequentially, we parallelize it through the preliminary search section. By broadening the vary of retrieved proof and deciding on essentially the most related context up entrance, we obtain extremely efficient search with considerably decrease latency.
Bettering the preliminary search relies upon closely on the coaching harness. Our harness supplies the mannequin with consumer directions and the exact schema of the underlying retrieval index, and it propagates them to all the next levels of question and filter era, reranking, and reply era. We described how this may be achieved in our earlier Instructed Retriever weblog, and we use the identical search harness in coaching our Instructed-Retriever-1 mannequin. This method is particularly vital for enterprise questions, which frequently contain domain-specific constraints comparable to time interval, group, doc sort, or product space.
Parallel question and filter era improves candidate-set recall by concurrently exploring a number of formulations and elements of the identical request. This enables the system to go looking extra broadly whereas maintaining latency low. Broader search creates an aggregation problem. Totally different formulations might return overlapping or solely partially related chunks. To pick out essentially the most helpful context from the merged candidate set, we use a multi-pivot groupwise reranker. Candidates are ranked in parallel teams, every anchored by a number of pivot chunks, and the group rankings are merged right into a ultimate ordering. This captures the important thing advantages of evaluating proof in context whereas maintaining reranking environment friendly.
Collectively, these levels present two test-time scaling knobs: growing the variety of question and filter formulations improves recall, whereas growing the variety of pivots improves precision. As a result of each levels can use parallelism, the system can commerce further test-time compute for higher-quality context whereas preserving low latency.
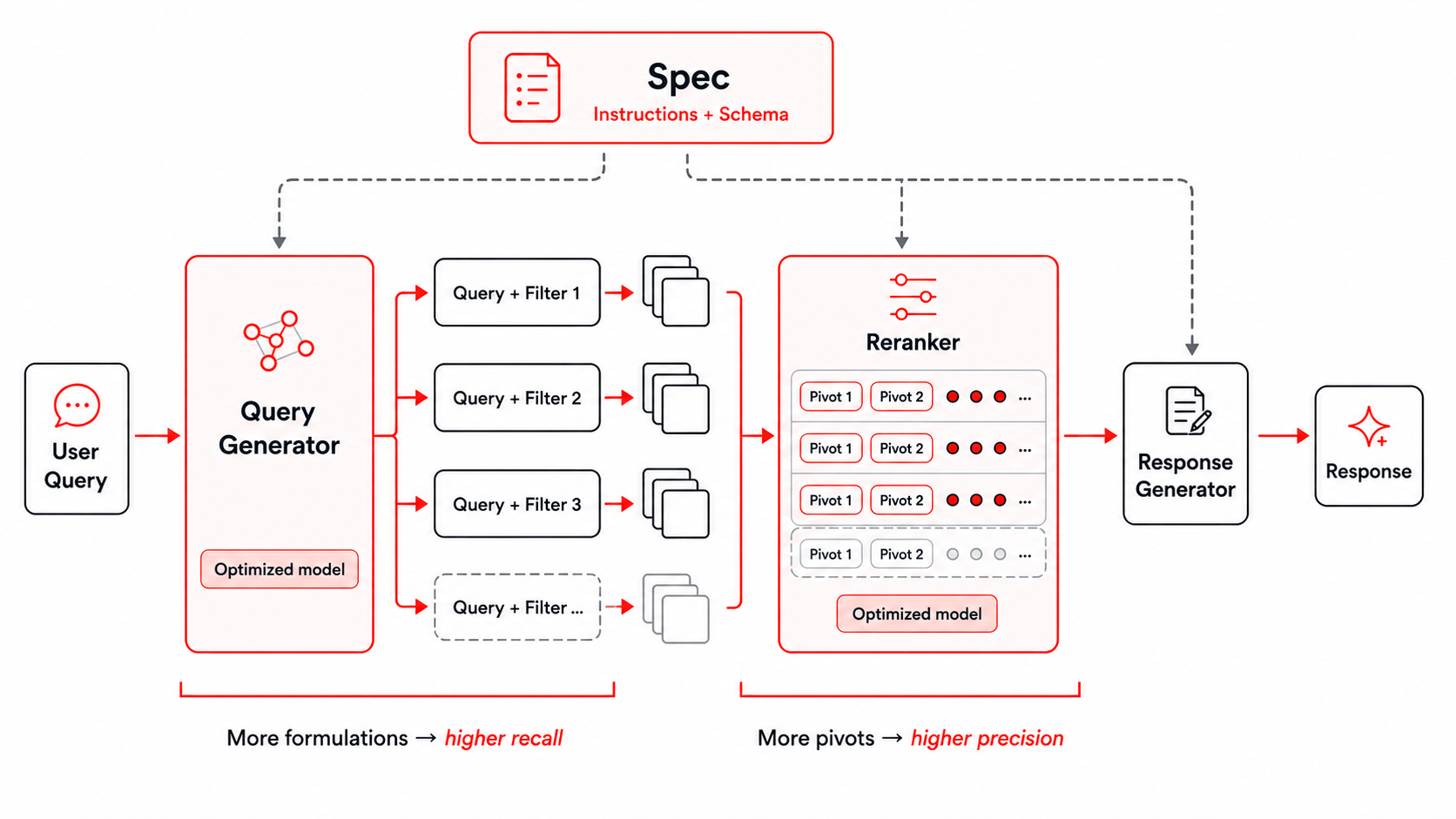
Determine: The search harness used for Instructed-Retriever-1.
2. Coaching Instructed-Retriever-1
Parallel test-time scaling for search requires a mannequin that may do two issues effectively: generate efficient searches and choose retrieved proof. We skilled Instructed-Retriever-1 as a single retrieval-specialized mannequin that helps parallel question era and reranking. The result’s a mannequin that matches Claude Sonnet 4.5 retrieval high quality on KARLBench whereas sustaining low latency.
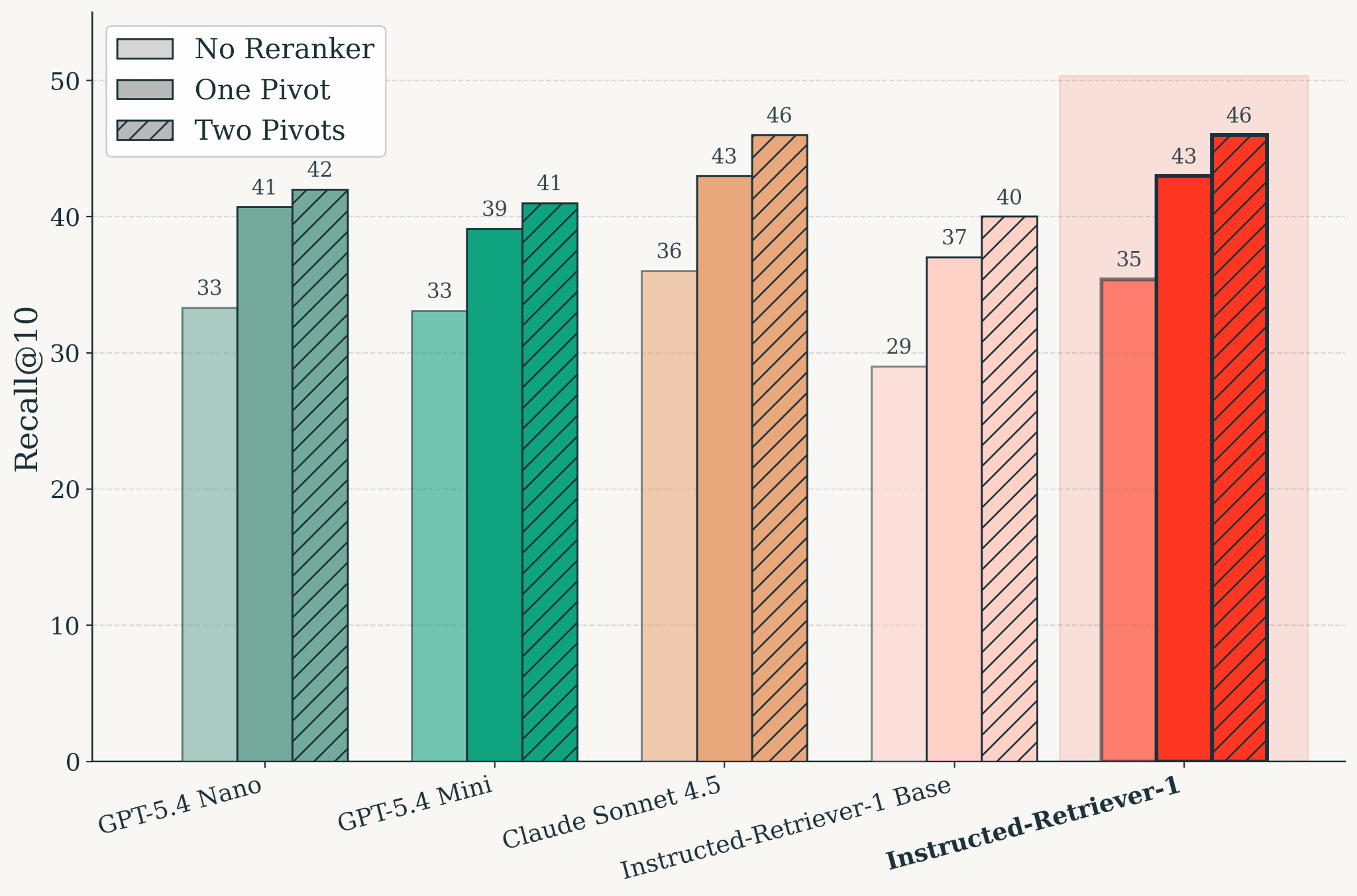
Determine: Retrieval high quality on KARLBench after coaching, evaluated throughout reranking configurations. Instructed-Retriever-1 matches Claude Sonnet 4.5 retrieval high quality. Throughout fashions, pivot-based reranking improves Recall@10 over the no-reranker setting, and two pivots additional enhance high quality over one pivot.
To arrange the information for coaching, we construct artificial enterprise-style retrieval environments from a broad pretraining corpus, independently from our analysis benchmark. We create them utilizing the agentic knowledge synthesis method described within the KARL report. The ensuing environments replicate the sorts of duties Data Assistant should deal with, together with factual lookup, summarization, suggestion, drawback fixing, and resolution assist over corpora that mix unstructured paperwork with structured metadata.
The mannequin is skilled in two levels to seize a number of search capabilities. The ensuing mannequin helps each question and filter era, in addition to verification-style retrieval capabilities, enabling the 2 levels that make parallel test-time scaling helpful in apply.
3. Validating Instructed-Retriever-1 in Manufacturing
Bettering retrieval solely issues if it really works on real looking workloads and suits inside manufacturing latency constraints. We consider Instructed-Retriever-1 on a large-scale inside dataset consultant of Data Assistant utilization, measuring whether or not the 2 scaling mechanisms launched above enhance retrieval high quality: parallel question and filter era for recall, and multi-pivot reranking for precision.
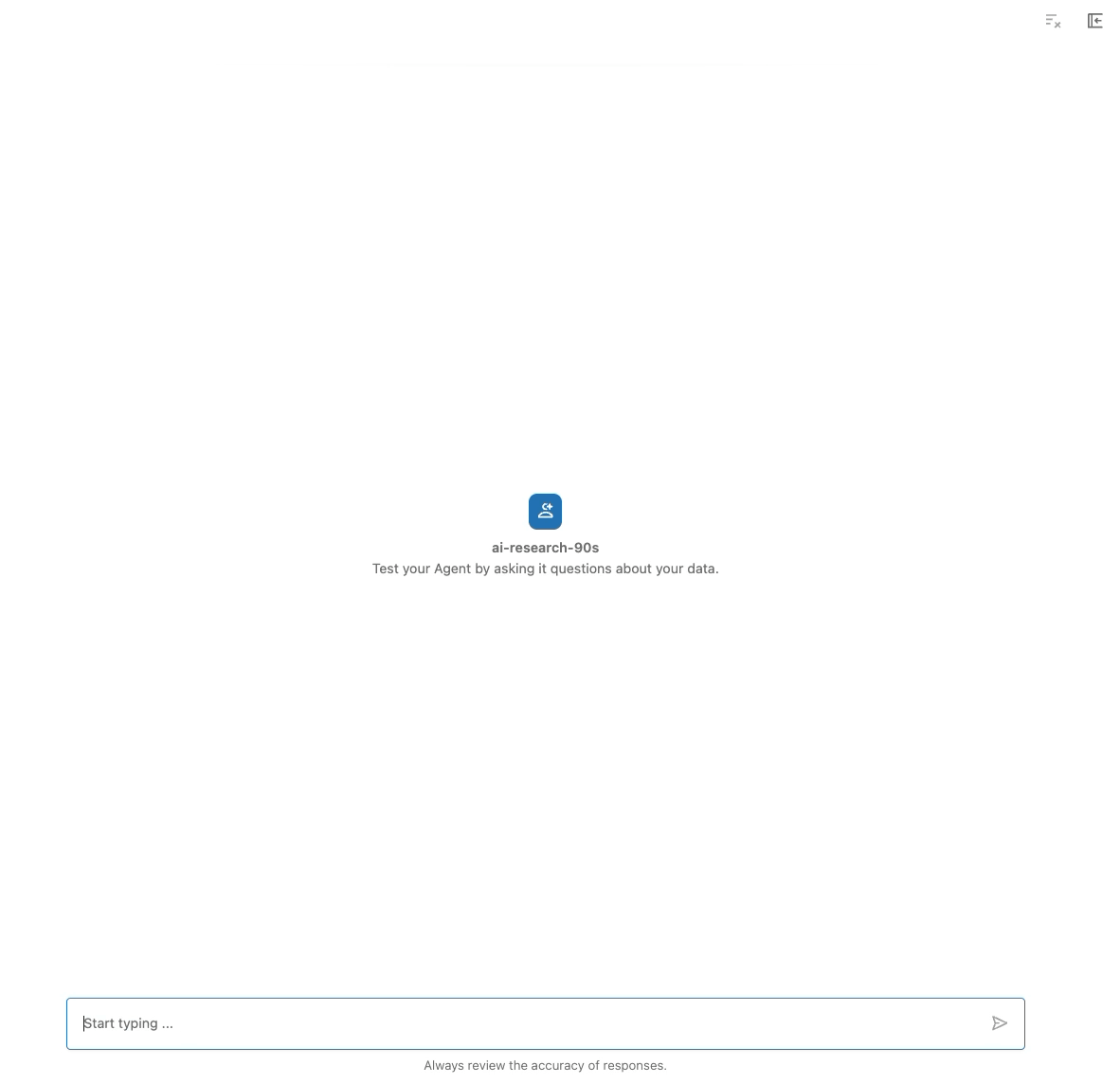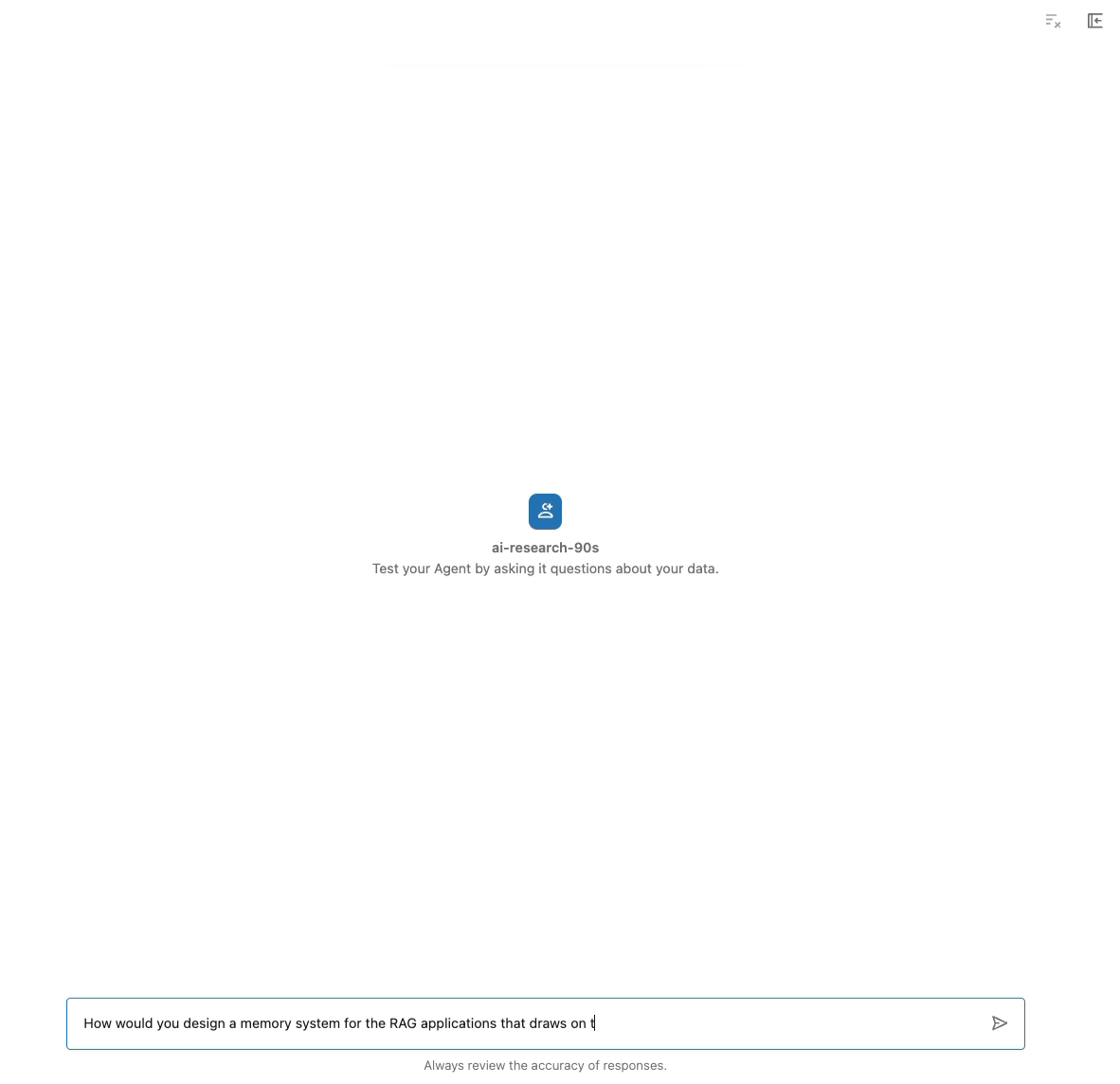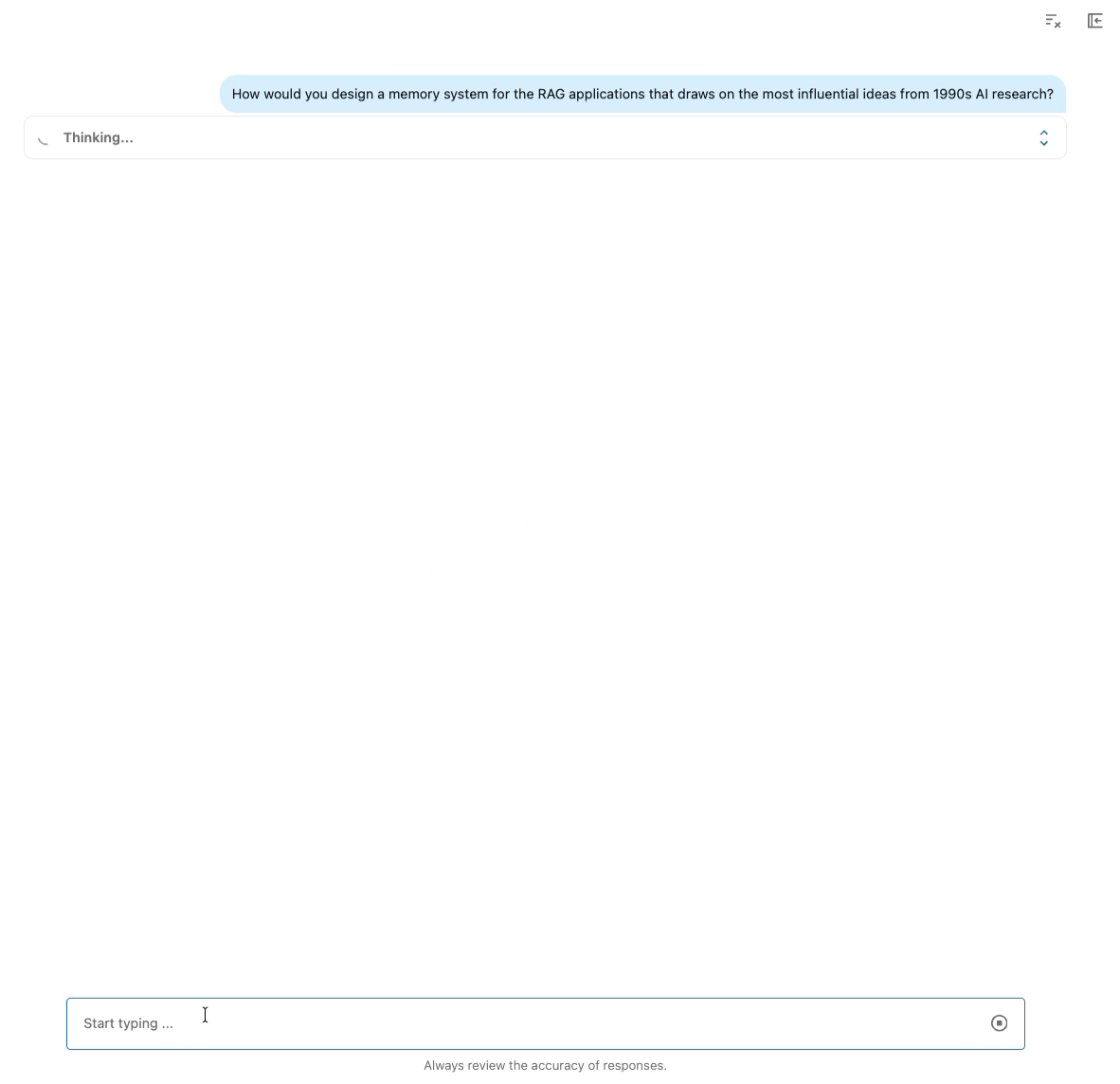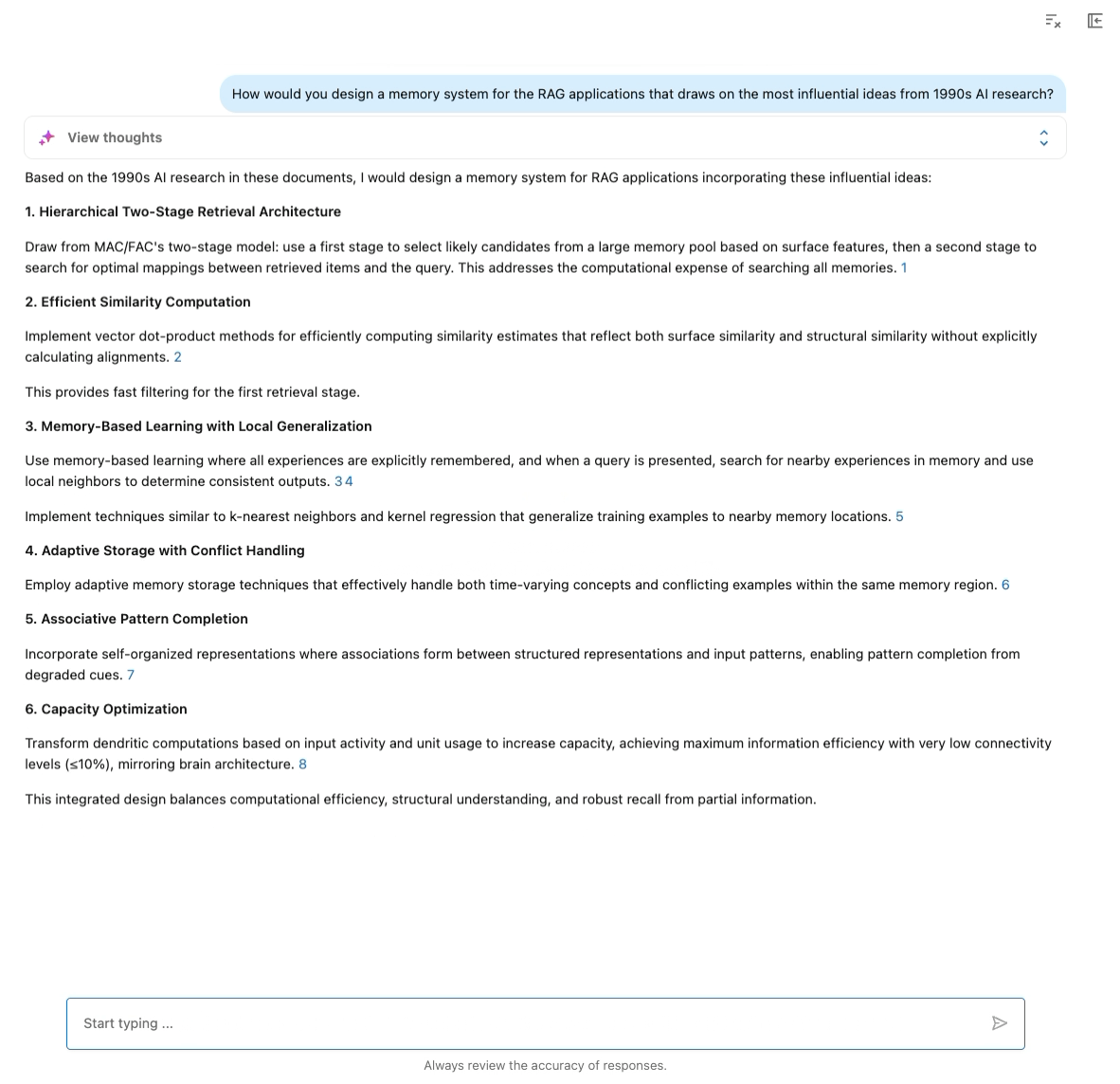
Determine: Demonstration of Data Assistant powered by Instructed-Retriever-1.
Retrieval high quality on real looking workloads
Our analysis dataset relies on real-world Data Assistant workloads, the place helpful solutions usually require a number of items of supporting proof fairly than a single ground-truth doc. We consider retrieval in two levels. First, we measure question era latency and high quality throughout all candidate methods. For high quality, we use LLM-judge rubric scores for specificity, breadth, and relevance. These metrics seize whether or not generated queries are focused, cowl the vital elements of the request, and stay helpful for answering the query.
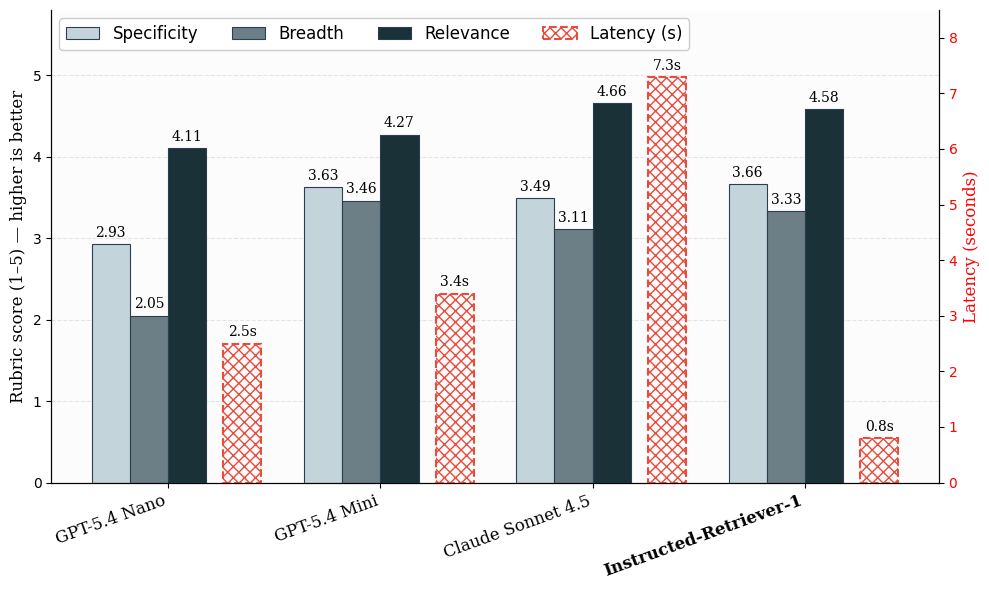
Determine: Question-generation high quality and latency on production-like inside examples. Imply rubric scores assess question era high quality throughout specificity, breadth, and relevance on a 1–5 scale. Latency is computed for a question era stage.
For reranking, we maintain the retrieved candidate set fastened and consider how successfully every reranker surfaces essentially the most helpful proof. To acquire dense relevance labels, we use an LLM choose to attain every chunk on a 0-3 TREC-style relevance scale, then compute nDCG@10 from the ensuing rankings. Claude Sonnet 4.5 and Instructed-Retriever-1 rating 80.1 and 81.0 nDCG@10, respectively. These are features of +12.8% and +14.1% in comparison with a setting with no reranking, demonstrating the effectiveness of our multi-pivot groupwise reranker.
General, on real looking workloads, Instructed-Retriever-1 performs strongly throughout the query-generation rubric metrics and stays aggressive with the strongest baseline on reranking. This helps the usage of a single retrieval-specialized mannequin for each question era and candidate choice.
Serving efficiency
Parallel test-time scaling is beneficial provided that the extra compute could be served effectively and scales with the variety of searches. To this finish, Instructed-Retriever-1 makes use of a Combination-of-Consultants structure and serving optimizations together with FP8 quantization,2 speculative decoding, and extra infrastructure tuning for the complete retrieval pipeline. In our evals, FP8 exhibits no high quality degradation whereas bettering inference velocity and throughput in comparison with BF16.3 Speculative decoding provides one other 30%+ speed-up for the mixed query-generation and reranking path.
Conclusion
This replace brings Parallel Check-Time Scaling into the manufacturing search stack. The system retrieves broadly via parallel question and filter era, then reranks exactly with multi-pivot proof comparability. Instructed-Retriever-1 powers each levels with a single retrieval-specialized mannequin skilled for search era and proof rating. The result’s a Data Assistant that’s each higher and sooner: search time drops by greater than 3x, reply era time drops by 2x, TTFT is round 2s, and end-to-end latency is persistently under 10s on our offline eval setup.¹ Early customers, like Baylor College and others, are already noticing the distinction.
“(The brand new expertise is) extra concise, with a ‘snappy’ really feel that surfaces key info sooner-a noticeable UX enchancment for our use circumstances.” — Kyle Van Pelt, Director of Course of and Governance, Enrollment Administration at Baylor College.
Begin asking extra of your Data Assistant right this moment. Instructed-Retriever-1 has begun rolling out to all clients, serving to groups retrieve higher-quality context with much less ready; you possibly can ask extra questions, uncover extra data, and transfer from query to reply sooner. Attempt it now.
1 Latency estimates measured as the typical throughout offline evaluations, with common size round 256 output tokens. Precise latency might differ based mostly on knowledge shapes in particular Data Assistant cases and queries.
2 We use NVIDIA’s ModelOpt library for FP8 quantization.
3 We evaluated the BF16 and FP8 fashions on KARLBench throughout 10 trials. FP8 confirmed no statistically vital high quality degradation relative to BF16: the imply rating distinction was +0.33 factors, with commonplace error 1.69 factors and 95% confidence interval [-2.99, 3.65].