
{kind=link}
Deep Brokers can plan, use instruments, handle state, and deal with lengthy multi-step duties. However their actual efficiency depends upon context engineering. Poor directions, messy reminiscence, or an excessive amount of uncooked enter rapidly degrade outcomes, whereas clear, structured context makes brokers extra dependable, cheaper, and simpler to scale.
Because of this the system is organized into 5 layers: enter context, runtime context, compression, isolation, and long-term reminiscence. On this article, you’ll see how every layer works, when to make use of it, and how one can implement it utilizing the create_deep_agent(...) Python interface.
What context engineering means in Deep Brokers
Context in Deep Brokers just isn’t that of the chat historical past alone. Some context is loaded into the system immediate at startup. Half is handed over on the time of invocation. A part of it’s mechanically compressed when the working set of the agent turns into too large. An element is confined inside subagents. Others is carried over between conversations utilizing the digital filesystem and store-backed reminiscence. The documentation is obvious that they’re separate mechanisms with separate scopes and that’s what makes deep brokers usable in manufacturing.
The 5 layers are:
- Enter context: Begin-up, fastened data, which was pooled into the system immediate.
- Runtime context: Per-run, dynamic configuration at invocation.
- Context compression: Offloading and summarization primarily based on automated reminiscence administration.
- Isolation of context with subagents: Assigning duties to subagents with new context home windows.
- Lengthy-term reminiscence: Enduring information that’s saved between classes.
Let’s assemble each one proper.
Stipulations
You’ll require Python 3.10 or later, the deepagents bundle and a supported mannequin supplier. In case you need to use dwell net search or hosted instruments, configure the supplier API keys in your surroundings. The official quickstart helps supplier setups to Anthropic, OpenAI, Google, OpenRouter, Fireworks, Baseten and Ollama.
!pip set up -U deepagents langchain langgraph Layer 1: Enter context
Enter context refers to all that the agent perceives at initiation as a part of its constructed system immediate. That comprises your customized system immediate, reminiscence information like AGENTS.md, expertise loaded primarily based on SKILL.md, and power prompts primarily based on built-in or customized instruments within the Deep Brokers docs. The docs additionally reveal that the entire assembled system immediate comprises inbuilt planning recommendation, filesystem software recommendation, subagent recommendation, and optionally available middleware prompts. That’s, what you customized immediate is is only one element of what the mannequin will get.
That design issues. It doesn’t suggest that you’ll hand concatenate your agent immediate, reminiscence file, expertise file and power assist right into a single massive string. Deep Brokers already understands how one can assemble such a construction. It’s your process to position the suitable content material within the applicable channel.
Use system_prompt for identification and habits
Request the system immediate on the function of the agent, tone, boundaries and top-level priorities. The documentation signifies that system immediate is immutable and in case you need it to be totally different relying on the consumer or request, you need to use dynamic immediate middleware somewhat than enhancing immediate strings instantly.
Use reminiscence for always-relevant guidelines
Reminiscence information like AGENTS.md are at all times loaded when configured. The docs recommend that reminiscence ought to be used to retailer steady conventions, consumer preferences or important directions which ought to be used all through all conversations. Since reminiscence is at all times injected, it should stay brief and high-signal.
Use expertise for workflows
Expertise are reusable workflows that are solely partially relevant. Deep Brokers masses the talent frontmatter on startup, and solely masses the complete talent physique when it determines the talent applies. The sample of progressive disclosure is among the many easiest strategies of minimizing token waste with out compromising means.
Use software descriptions as operational steering
The metadata of the software is included within the immediate that the mannequin is reasoning about. The docs recommend giving names to instruments in clear language, write descriptions indicating when to make use of them, and doc arguments in a way that may be understood by the agent and so, they’ll choose the instruments appropriately.
Palms-on Lab 1: Construct a mission supervisor agent with layered enter context
The First lab develops a easy but real looking mission supervisor agent. It has a hard and fast place, a hard and fast reminiscence file of conventions and a capability to do weekly reporting.
Challenge construction
mission/
├── AGENTS.md
├── expertise/
│ └── weekly-report/
│ └── SKILL.md
└── agent_setup.py
AGENTS.md
## Position
You're a mission supervisor agent for Acme Corp.## Conventions
- All the time reference duties by process ID, akin to TASK-42
- Summarize standing in three phrases or fewer
- By no means expose inner value information to exterior stakeholders
expertise/weekly-report/SKILL.md
---
identify: weekly-report
description: Use this talent when the consumer asks for a weekly replace or standing report.
---
# Weekly report workflow
1. Pull all duties up to date within the final 7 days.
2. Group them by standing: Carried out, In Progress, Blocked.
3. Format the end result as a markdown desk with proprietor and process ID.
4. Add a brief government abstract on the high.agent_setup.py
from pathlib import Path
from IPython.core.show import Markdown
from deepagents import create_deep_agent
from deepagents.backends import FilesystemBackend
from langchain.instruments import software
ROOT = Path.cwd().resolve().guardian
@software
def get_blocked_tasks() -> str:
"""Return blocked duties for the present mission."""
return """
TASK-17 | Blocked | Priya | Ready on API approval
TASK-23 | Blocked | Omar | Vendor dependency
TASK-31 | Blocked | Mina | Check surroundings unstable
""".strip()
agent = create_deep_agent(
mannequin="openai:gpt-4.1",
system_prompt="You might be Acme Corp's mission supervisor agent.",
instruments=[get_blocked_tasks],
reminiscence=["./AGENTS.md"],
expertise=["./skills/"],
backend=FilesystemBackend(root_dir=str(ROOT), virtual_mode=True),
)
end result = agent.invoke(
{
"messages": [
{"role": "user", "content": "What tasks are currently blocked?"}
]
}
)
Markdown(end result["messages"][-1].content material[0]["text"])Output:
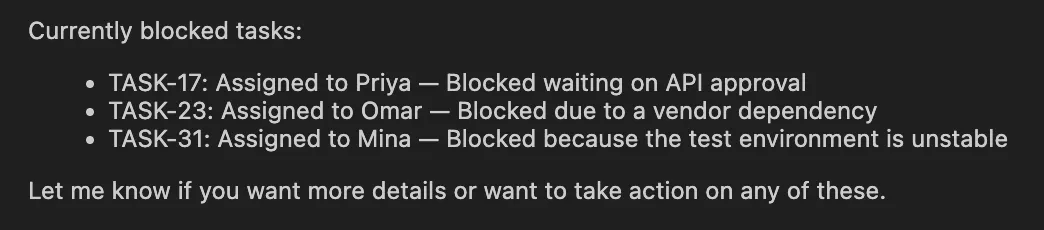
This variant coincides with the recorded Deep Brokers sample. Reminiscence is proclaimed with reminiscence=… and expertise with expertise=… and a backend gives entry to these information by the agent. The agent won’t ever get optimistic concerning the contents of AGENTS.md, however totally load SKILL.md on events when it finds it crucial to take action, i.e. when the weekly-report workflow is in play.
The ethical of the story is simple. Repair lasting legal guidelines in thoughts. Find reusable and non-constant workflows in expertise. Keep a system that’s behaviorally and identification oriented. A single separation already aids a great deal of well timed bloat.
Layer 2: Runtime context
The info that you simply cross throughout invocation time is the runtime context. One other vital reality that’s made very clear by the docs is that the runtime context just isn’t mechanically offered to the mannequin. Solely is it seen whether or not instruments or middleware explicitly learn it and floor it. It’s the proper place, then, to maintain consumer IDs, roles, characteristic flags, database handles, API keys, or something that’s operational however to not be present in a immediate.
The sample that’s at present recommended is to specify a context_schema, and invoke the agent with context=…, and to entry these values inside instruments with ToolRuntime. The docs of the LangChain instruments additionally point out that runtime is the suitable injection level of execution data, context, entry to a retailer, and different related metadata.
Palms-on Lab 2: Go runtime context with out polluting the immediate
from openai import api_key
from dataclasses import dataclass
import os
from IPython.core.show import Markdown
from deepagents import create_deep_agent
from langchain.instruments import software, ToolRuntime
@dataclass
class Context:
user_id: str
org_id: str
db_connection_string: str
weekly_report_enabled: bool
@software
def get_my_tasks(runtime: ToolRuntime[Context]) -> str:
"""Return duties assigned to the present consumer."""
user_id = runtime.context.user_id
org_id = runtime.context.org_id
# Change this stub with an actual question in manufacturing.
return (
f"Duties for consumer={user_id} in org={org_id}n"
"- TASK-12 | In Progress | End onboarding flown"
"- TASK-19 | Blocked | Await authorized reviewn"
)
agent = create_deep_agent(
mannequin="openai:gpt-4.1",
instruments=[get_my_tasks],
context_schema=Context,
)
end result = agent.invoke(
{
"messages": [
{"role": "user", "content": "What tasks are assigned to me?"}
]
},
context=Context(
user_id="usr_8821",
org_id="acme-corp",
db_connection_string="postgresql://localhost/acme",
weekly_report_enabled=True,
),
)
Markdown(end result["messages"][-1].content material[0]["text"])Output:

That is the clear minimize that you simply want in manufacturing. The mannequin can invoke get my duties however the true userid and orgid stay within the runtime context somewhat than being pushed onto the system immediate or chat historical past. It’s a lot safer and simpler to purpose about, throughout debugging of permissions and information circulation.
One rule is as follows: When the mannequin should purpose a few reality instantly, put it in prompt-space. To go away it in runtime context in case your instruments require it to be in operational state.
Layer 3: Context compression
Duties which might be long-running generate two points rapidly: big software outputs and prolonged histories. Deep Brokers helps them each with inbuilt context compression. The 2 native mechanisms, offloading and summarization, are described within the docs. Unloads shops with massive software inputs and replicates them with references within the filesystem. Summarization is used to cut back the dimensions of older messages because the agent nears the context constraint of the mannequin.
Offloading
In keeping with the context engineering docs, content material offloading happens when the software name inputs or outputs surpass a token threshold, with default threshold being 20,000 tokens. Large historic instruments information are substituted with references to the information which have been endured in order that the agent can entry it later when required.
Summarization
In case the lively context turns into excessively massive, Deep Brokers summarizes older elements of the dialog to proceed with the duty with out surpassing the window of the mannequin. It additionally has an optionally available summarization software middleware, which permits the agent to summarize on extra fascinating boundaries, e.g., between process phases, somewhat than simply on the computerized threshold.
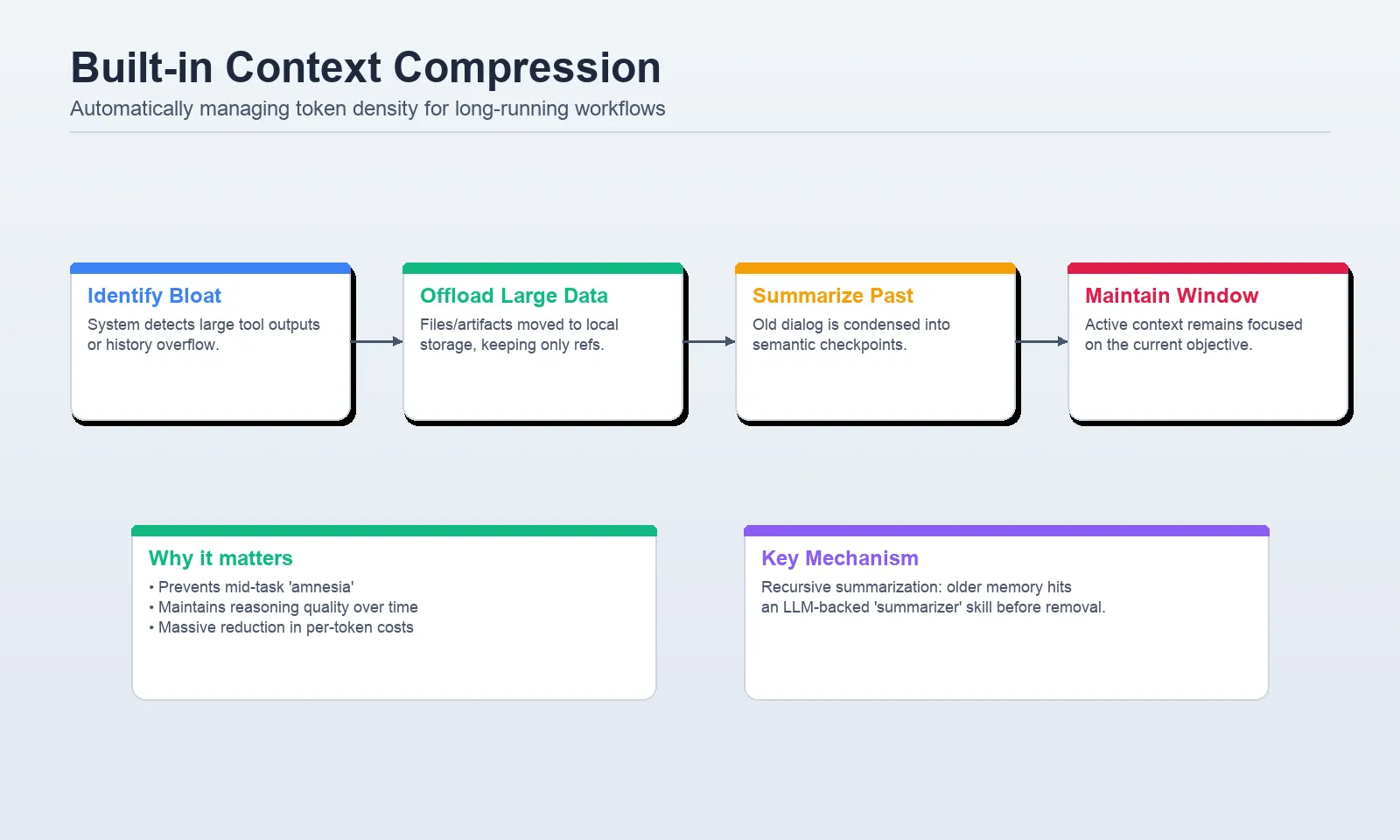
Palms-on Lab 3: Use built-in compression the precise means
from deepagents import create_deep_agent
from IPython.core.show import Markdown
def generate_large_report(subject: str) -> str:
"""Generate a really detailed report on vector database tradeoffs."""
# Simulate a big software end result
return ("Detailed report about " + subject + "n") * 5000
agent = create_deep_agent(
mannequin="openai:gpt-4.1-mini",
instruments=[generate_large_report],
)
end result = agent.invoke(
{
"messages": [
{
"role": "user",
"content": "Generate a very detailed report on vector database tradeoffs.",
}
]
}
)
Markdown(end result["messages"][-1].content material[0]["text"])Output:

In a setup like this, Deep Brokers handles the heavy lifting. If the software output turns into massive sufficient, the framework can offload it to the filesystem and hold solely the related reference in lively context. Which means you need to begin with the built-in habits earlier than inventing your personal middleware.
In order for you proactive summarization between phases, use the documented middleware:
from deepagents import create_deep_agent
from deepagents.backends import StateBackend
from deepagents.middleware.summarization import create_summarization_tool_middleware
agent = create_deep_agent(
mannequin="openai:gpt-4.1",
middleware=[
create_summarization_tool_middleware("openai:gpt-4.1", StateBackend),
],
)That provides an optionally available summarization software so the agent can compress context at logical checkpoints as a substitute of ready till the window is almost full.
Layer 4: Context isolation with subagents
Subagents can be found to take care of the first agent clear. The docs recommend them in multi-step work that will in any other case litter the guardian context, in particular areas, and in work that may require a unique toolset or mannequin. They clearly recommend that they don’t seem to be for use in one-step duties or duties the place the dad and mom intermediate reasoning will nonetheless be inside the scope.
The Deep Brokers sample is at present to declare subagents with the subagents= parameter. Within the majority of functions, they are often represented as a dictionary with a reputation, description, system immediate, instruments and optionally available mannequin override as every subagent.
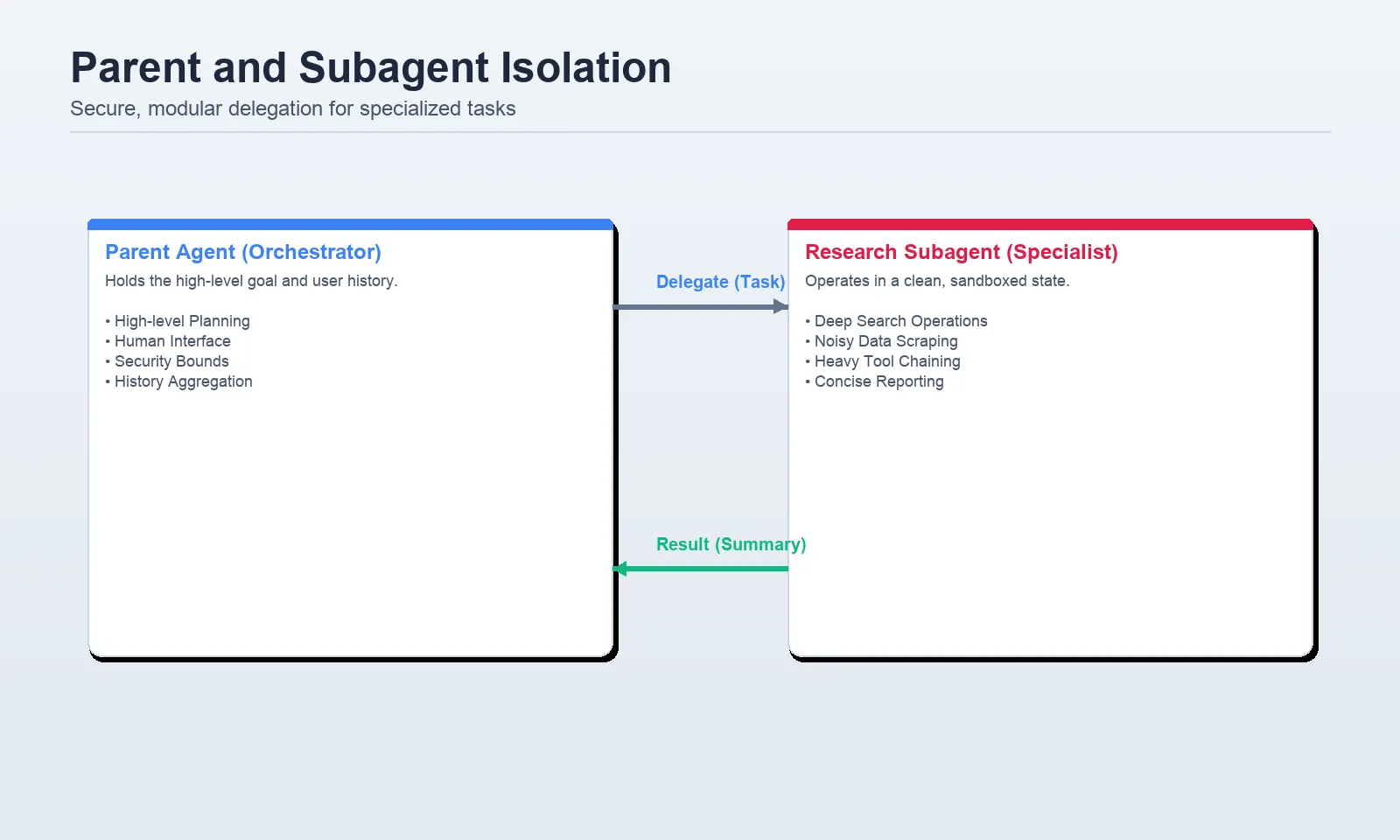
Palms-on Lab 4: Delegate analysis to an remoted subagent
from deepagents import create_deep_agent
from IPython.core.show import Markdown
def internet_search(question: str, max_results: int = 5) -> str:
"""Run an online seek for the given question."""
return f"Search outcomes for: {question} (high {max_results})"
research_subagent = {
"identify": "research-agent",
"description": "Use for deep analysis and proof gathering.",
"system_prompt": (
"You're a analysis specialist. "
"Analysis completely, however return solely a concise abstract. "
"Don't return uncooked search outcomes, lengthy excerpts, or software logs."
),
"instruments": [internet_search],
"mannequin": "openai:gpt-4.1",
}
agent = create_deep_agent(
mannequin="openai:gpt-4.1",
system_prompt="You coordinate work and delegate deep analysis when wanted.",
subagents=[research_subagent],
)
end result = agent.invoke(
{
"messages": [
{
"role": "user",
"content": "Research best practices for retrieval evaluation and summarize them.",
}
]
}
)
Markdown(end result["messages"][-1].content material[0]["text"])Output:
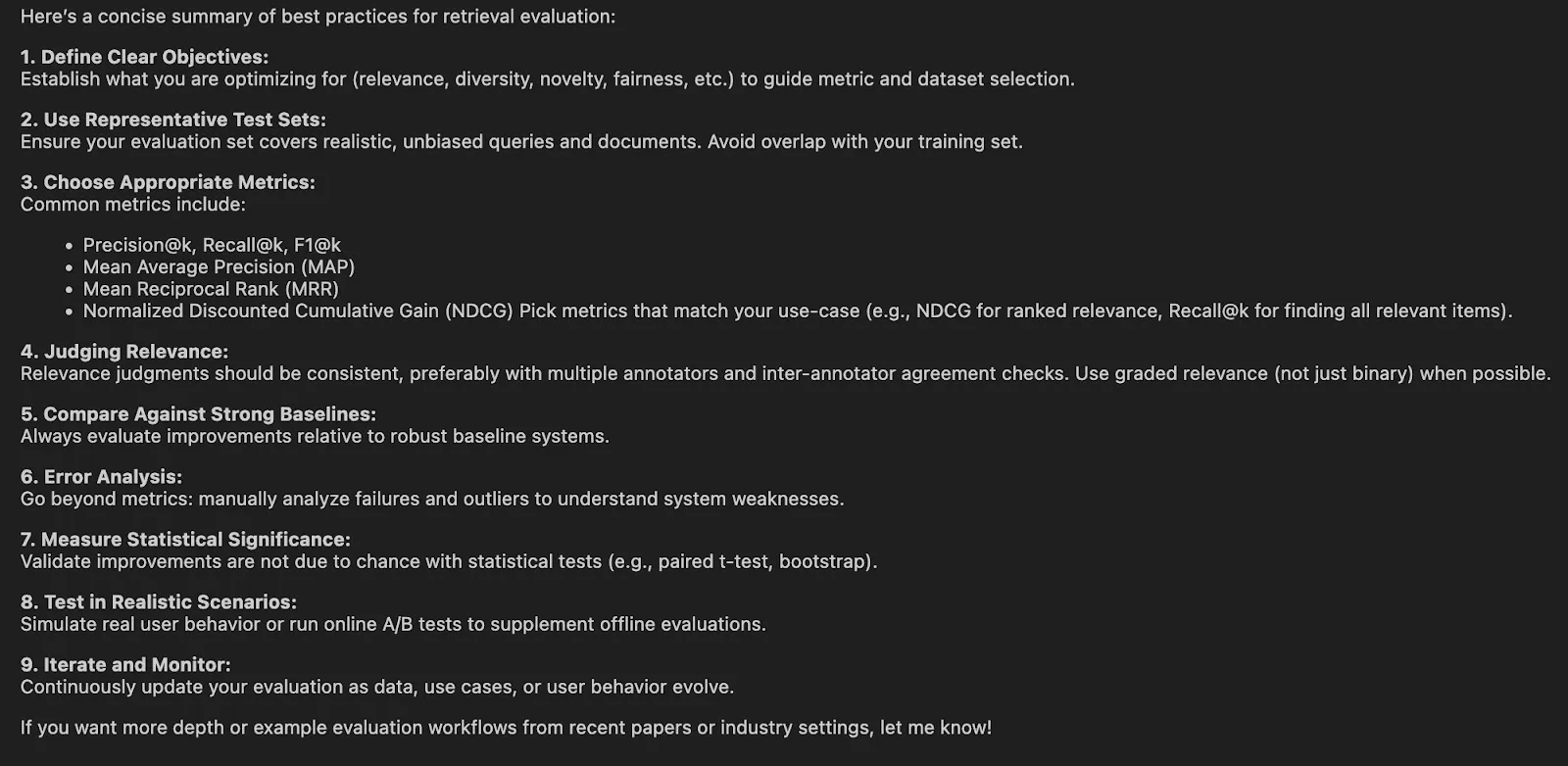
Delegation just isn’t the important thing to good subagent design. It’s containment. The subagent just isn’t supposed to provide the uncooked information, however a concise reply. In any other case, you lose all of the overhead of isolation with out having any context financial savings.
The opposite noteworthy reality talked about within the paperwork is that runtime context is propagated to subagents. When the guardian has an present consumer, org or function within the runtime context, the subagent inherits it as effectively. That’s the reason subagents are much more handy to work with in actual methods since you don’t want to re-enter the identical information in each place manually.
Layer 5: Lengthy-term reminiscence
Lengthy-term reminiscence is the place Deep Brokers turns into way more than a elaborate immediate wrapper. The docs describe reminiscence as persistent storage throughout threads by means of the digital filesystem, often routed with StoreBackend and infrequently mixed with CompositeBackend so totally different filesystem paths can have totally different storage habits.
That is what most examples err at wrongly. It ought to have a path to a backend akin to StoreBackend and to not a uncooked retailer object. The shop itself is exchanged to type create deep_agent(...). The paths of the reminiscence information are outlined in reminiscence=[…], which may be then loaded mechanically into the system immediate.
The reminiscence docs additional make clear that there are different dimensions to reminiscence apart from storage. It’s essential to think about size, kind of knowledge, protection, and updating plan. Virtually, probably the most important alternative is scope: Is it going to be per-user, per-agent, or an organization-wide reminiscence?
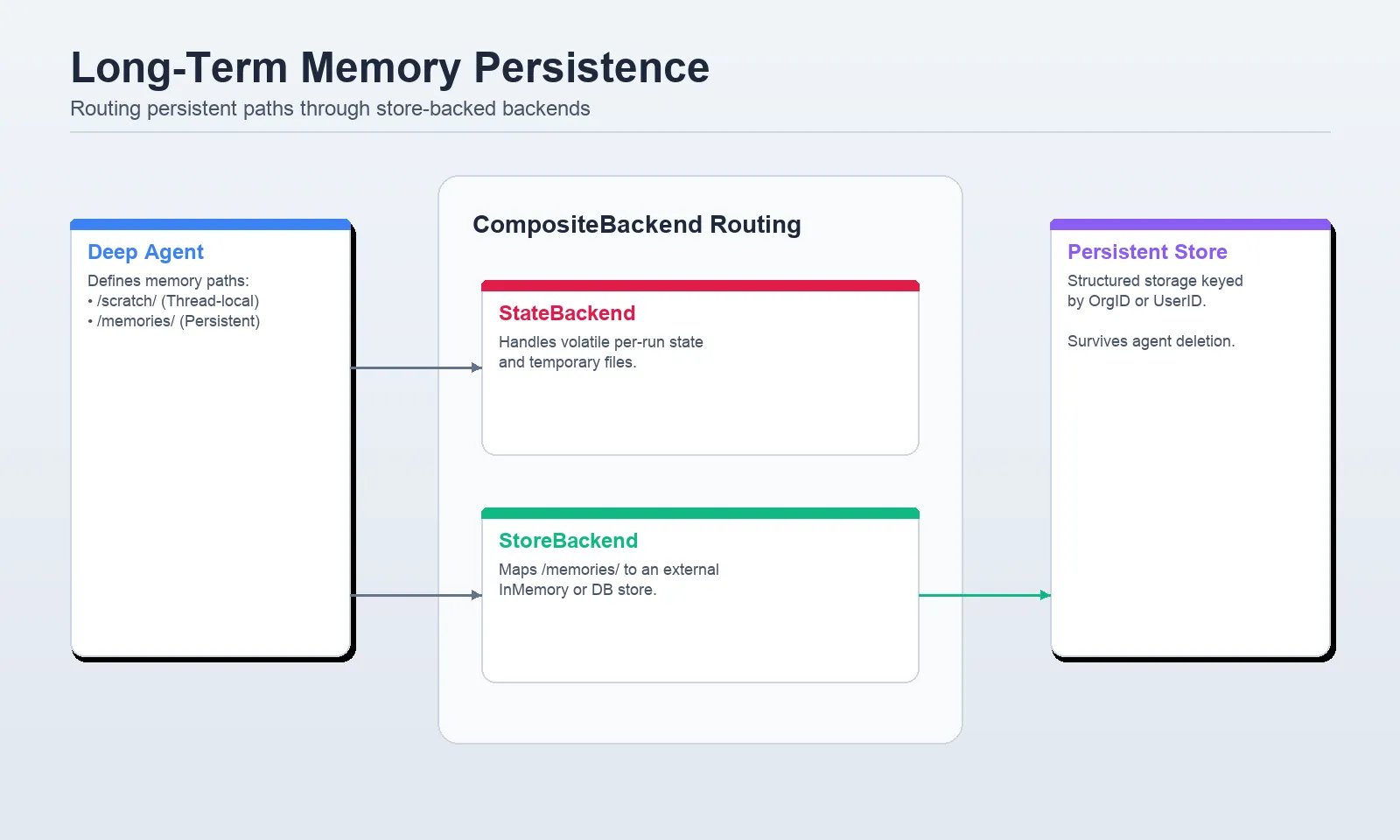
CompositeBackend to ship scratch information to StateBackend and /reminiscences/ paths to StoreBackend. Palms-on Lab 5: Add user-scoped cross-session reminiscence
from dataclasses import dataclass
from IPython.core.show import Markdown
from deepagents import create_deep_agent
from deepagents.backends import CompositeBackend, StateBackend, StoreBackend
from deepagents.backends.utils import create_file_data
from langgraph.retailer.reminiscence import InMemoryStore
from langchain_core.utils.uuid import uuid7
@dataclass
class Context:
user_id: str
retailer = InMemoryStore()
# Seed reminiscence for one consumer
retailer.put(
("user-alice",),
"/reminiscences/preferences.md",
create_file_data("""## Preferences
- Hold responses concise
- Want Python examples
"""),
)
agent = create_deep_agent(
mannequin="openai:gpt-4.1-mini",
reminiscence=["/memories/preferences.md"],
context_schema=Context,
backend=lambda rt: CompositeBackend(
default=StateBackend(rt),
routes={
"/reminiscences/": StoreBackend(
rt,
namespace=lambda ctx: (ctx.runtime.context.user_id,),
),
},
),
retailer=retailer,
system_prompt=(
"You're a useful assistant. "
"Use reminiscence information to personalize your solutions when related."
),
)
end result = agent.invoke(
{
"messages": [
{"role": "user", "content": "How do I read a CSV file in Python?"}
]
},
config={"configurable": {"thread_id": str(uuid7())}},
context=Context(user_id="user-alice"),
)
Markdown(end result["messages"][-1].content material[0]["text"])Output:
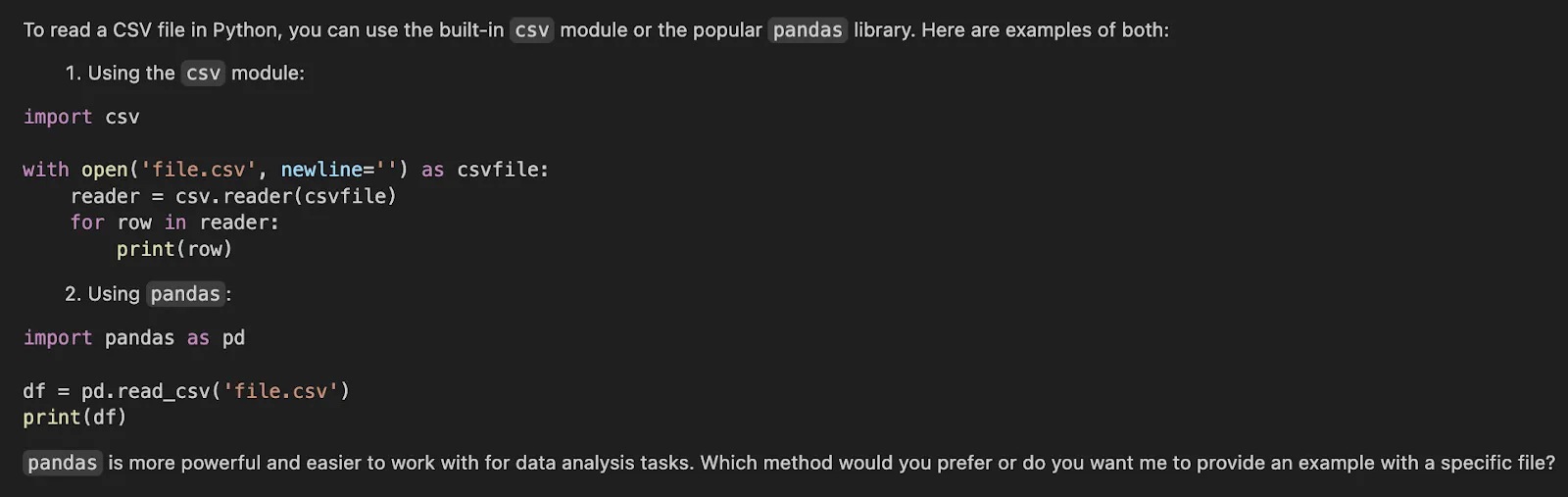
There are three important issues that this setup does. It masses a reminiscence file to the agent. It sends /reminiscences/ to persistent store-backed storage. And it’s namespace remoted per consumer by utilizing user_id because the namespace. That is the right default with most multi-user methods because it doesn’t enable reminiscence to leak between customers.
While you require organizational reminiscence that you simply share, you need to use a unique namespace and continuously a unique path like /insurance policies or /org-memory. While you require agent stage shared procedural reminiscence, then use agent particular namespace. Nevertheless, consumer scope is probably the most safe start line, when it comes to consumer preferences and customised habits.
Frequent errors to keep away from
The prevailing documentation implicitly cautions towards a number of the typical pitfalls, they usually can’t harm to be specific.
- Watch out to not overload the system. All the time-loaded immediate area is expensive and tough to take care of. Be conscious of reminiscence and expertise.
- Don’t switch runtime-only data utilizing chat messages. IDs, permissions, characteristic flags and connection particulars fall in runtime context.
- Offloading and summarization shouldn’t be reimplemented till you could have quantified an precise distinction within the built-ins.
- Shouldn’t have subagents undertake insignificant single duties. The paperwork clearly point out to set them apart to context-intensive or specialised work.
- The default is to not retailer all long-term reminiscence in a single shared namespace. Decide the proprietor of the reminiscence, the consumer or the agent, or the group.
Conclusion
Deep Brokers usually are not efficient since they possess prolonged prompts. They’re robust since they mean you can decouple context by function and lifecycle. Cross-thread reminiscence, per-run state, startup directions, compressed historical past, and delegated work are just a few different issues. Deep Brokers framework gives you with a clear abstraction of every. While you instantly use these abstractions somewhat than debugging round them, your brokers are easier to debug, cheaper to execute, and extra dependable to make use of in actual workloads.
That’s the precise artwork of context engineering. It doesn’t matter about offering extra context. It’s giving the agent simply the context that it requires, simply the place it’s required.
Incessantly Requested Questions
A. It’s the process of giving AI brokers the right data. That is supplied within the applicable format and on the opportune second. It directs their actions and makes them accomplish any process.
A. Context performs an vital function because it helps brokers to remain centered. It assists them in not being irrelevant. It additionally makes positive that they get requisite information. This outcomes into efficient and reliable efficiency of duties.
A. Subagents are context isolating. They sort out intricate output-intensive jobs inside their very distinct setting. This ensures that the reminiscence of the primary agent is clear and goal in direction of its major objectives.
Harsh Mishra is an AI/ML Engineer who spends extra time speaking to Giant Language Fashions than precise people. Captivated with GenAI, NLP, and making machines smarter (so that they don’t substitute him simply but). When not optimizing fashions, he’s most likely optimizing his espresso consumption. 🚀☕
Login to proceed studying and luxuriate in expert-curated content material.