
{kind=link}
AI and ML builders usually work with native datasets whereas preprocessing information. Engineering options, and constructing prototypes make this simple with out the overhead of a full server. The commonest comparability is between SQLite, a serverless database launched in 2000 and extensively used for light-weight transactions, and DuckDB, launched in 2019 because the SQLite of analytics, centered on quick in-process analytical queries. Whereas each are embedded, their objectives differ. On this article, we’ll evaluate DuckDB and SQLite that can assist you select the proper device for every stage of your AI workflow.
What’s SQLite?
SQLite is a self-contained database engine that’s serverless. It creates a button instantly out of a disk file. It’s zero-configured and has a low footprint. The database is all saved in a single file that’s.sqlite and the tables and indexes are all contained in that file. The engine itself is a C library that’s embedded in your utility.
SQLite is an ACID-compliant database, although it’s easy. This makes it reliable within the transactions and information integrity.
Key options embody:
- Row-oriented storage: The info is saved row by row. This renders updating or retrieving a person row to be fairly environment friendly.
- Single-file database: All the database is in a single file. This allows it to be copied or transferred simply.
- No server course of: Direct studying and writing to the database file are made to your utility. No separate server is required.
- Broad SQL help: It’s based mostly on most SQL-2 and helps things like joins, window capabilities, and indexes.
SQLite is continuously chosen in cell purposes and Web of Issues, in addition to small internet purposes. It’s luminous the place you require a simple answer to retailer structured information regionally, and when you’ll require quite a few quick learn and write operations.
What’s DuckDB?
DuckDB is a knowledge analytics in-process database. It takes the power of the SQL database to embedded purposes. It’s going to execute sophisticated analytical queries successfully with out a server. This analytical focus is continuously the idea of comparability between DuckDB and SQLite.
The essential options of DuckDB are:
- Columnar storage format: DuckDB shops information columns. On this format, it is ready to scan and merge big datasets at a a lot higher fee. It reads solely the columns that it requires.
- Vectorized question execution: DuckDB is designed to carry out calculations in chunks, or vectors, somewhat than in a single row. This methodology entails the appliance of present CPU capabilities to compute at a higher fee.
- Direct file querying: DuckDB can question Parquet, CSV and Arrow information instantly. There isn’t any have to put them into the database.
- Deep information science integration: It’s appropriate with Pandas, NumPy and R. DataFrame will be requested questions like database tables.
DuckDB can be utilized to shortly course of interactive information evaluation in Jupyter notebooks and pace up Pandas workflows. It takes information warehouse capabilities in a small and native bundle.
Key Variations
First, here’s a abstract desk evaluating SQLite and DuckDB on essential points.
| Side | SQLite (since 2000) | DuckDB (since 2019) |
| Main Goal | Embedded OLTP database (transactions) | Embedded OLAP database (analytics) |
| Storage Mannequin | Row-based (shops whole rows collectively) | Columnar (shops columns collectively) |
| Question Execution | Iterative row-at-a-time processing | Vectorized batch processing |
| Efficiency | Glorious for small, frequent transactions | Glorious for analytical queries on massive information |
| Information Dimension | Optimized for small-to-medium datasets | Handles massive and out-of-memory datasets |
| Concurrency | Multi-reader, single-writer (through locks) | Multi-reader, single-writer; parallel question execution |
| Reminiscence Use | Minimal reminiscence footprint by default | Leverages reminiscence for pace; can use extra RAM |
| SQL Options | Strong fundamental SQL with some limits | Broad SQL help for superior analytics |
| Indexes | B-tree indexes are sometimes wanted | Depends on column scans; indexing is much less frequent |
| Integration | Supported in almost each language | Native integration with Pandas, Arrow, NumPy |
| File Codecs | Proprietary file; can import/export CSVs | Can instantly question Parquet, CSV, JSON, Arrow |
| Transactions | Absolutely ACID-compliant | ACID inside a single course of |
| Parallelism | Single-threaded question execution | Multi-threaded execution for a single question |
| Typical Use Instances | Cellular apps, IoT units, native app storage | Information science notebooks, native ML experiments |
| License | Public area | MIT License (open supply) |
This desk reveals that SQLite focuses on reliability and operations of transactions. DuckDB is optimized to help fast analytic queries on huge information. Now we’re going to talk about every certainly one of them.
Palms-On in Python: From Idea to Apply
We’ll see tips on how to make the most of each databases in Python. It’s an open-source AI growth surroundings.
Utilizing SQLite
That is a straightforward illustration of SQLite Python. We will develop a desk, enter information, and execute a question.
import sqlite3
# Connect with a SQLite database file
conn = sqlite3.join("instance.db")
cur = conn.cursor()
# Create a desk
cur.execute(
"""
CREATE TABLE customers (
id INTEGER PRIMARY KEY,
identify TEXT,
age INTEGER
);
"""
)
# Insert data into the desk
cur.execute(
"INSERT INTO customers (identify, age) VALUES (?, ?);",
("Alice", 30)
)
cur.execute(
"INSERT INTO customers (identify, age) VALUES (?, ?);",
("Bob", 35)
)
conn.commit()
# Question the desk
for row in cur.execute(
"SELECT identify, age FROM customers WHERE age > 30;"
):
print(row)
# Anticipated output: ('Bob', 35)
conn.shut()Output:
The database on this case is stored within the instance.db file. Now we have made a desk, added two rows to it, and executed a easy question. SQLite makes you load information into the tables after which question. In case you’ve got a CSV file, you need to import the knowledge first.
Utilizing DuckDB
Nonetheless, it’s time to repeat this feature with DuckDB. We will additionally carry your consideration to its information science conveniences.
import duckdb
import pandas as pd
# Connect with an in-memory DuckDB database
conn = duckdb.join()
# Create a desk and insert information
conn.execute(
"""
CREATE TABLE customers (
id INTEGER,
identify VARCHAR,
age INTEGER
);
"""
)
conn.execute(
"INSERT INTO customers VALUES (1, 'Alice', 30), (2, 'Bob', 35);"
)
# Run a question on the desk
consequence = conn.execute(
"SELECT identify, age FROM customers WHERE age > 30;"
).fetchall()
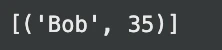
print(consequence) # Anticipated output: [('Bob', 35)]Output:
The straightforward use resembles the fundamental utilization. Nonetheless, exterior information can be queried by DuckDB.
Let’s generate a random dataset for querying:
import pandas as pd
import numpy as np
# Generate random gross sales information
np.random.seed(42)
num_entries = 1000
information = {
"class": np.random.alternative(
["Electronics", "Clothing", "Home Goods", "Books"],
num_entries
),
"value": np.spherical(
np.random.uniform(10, 500, num_entries),
2
),
"area": np.random.alternative(
["EUROPE", "AMERICA", "ASIA"],
num_entries
),
"sales_date": (
pd.to_datetime("2023-01-01")
+ pd.to_timedelta(
np.random.randint(0, 365, num_entries),
unit="D"
)
)
}
sales_df = pd.DataFrame(information)
# Save to sales_data.csv
sales_df.to_csv("sales_data.csv", index=False)
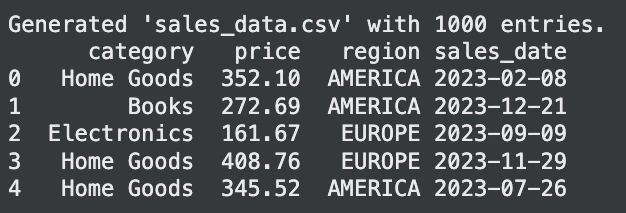
print("Generated 'sales_data.csv' with 1000 entries.")
print(sales_df.head())Output:
Now, let’s question this desk:
# Assume 'sales_data.csv' exists
# Instance 1: Querying a CSV file instantly
avg_prices = conn.execute(
"""
SELECT
class,
AVG(value) AS avg_price
FROM 'sales_data.csv'
WHERE area = 'EUROPE'
GROUP BY class;
"""
).fetchdf() # Returns a Pandas DataFrame
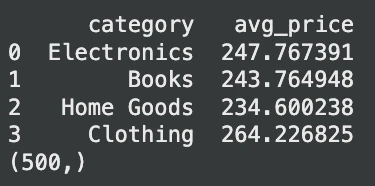
print(avg_prices.head())
# Instance 2: Querying a Pandas DataFrame instantly
df = pd.DataFrame({
"id": vary(1000),
"worth": vary(1000)
})
consequence = conn.execute(
"SELECT COUNT(*) FROM df WHERE worth % 2 = 0;"
).fetchone()
print(consequence) # Anticipated output: (500,)Output:
On this case, DuckDB reads the CSV file on the fly. No essential step is required. It is usually capable of question a Pandas DataFrame. This flexibility removes a lot of the information loading code and simplifies AI pipelines.
Structure: Why They Carry out So Otherwise
The variations within the efficiency of SQLite and DuckDB should do with their storage and question engines.
- Storage Mannequin: SQLite is row based mostly. It teams all information of 1 row in it. This is excellent for updating a single file. Nonetheless, it isn’t quick with analytics. Assuming that you simply simply require a single column, then SQLite will nonetheless should learn all the information of every row. DuckDB is column oriented. It places all of the values of 1 column in a single column. That is splendid for analytics. A question comparable to
SELECT AVG(age)solely reads the age column which is far sooner. - Question Execution: SQLite one question per row. That is reminiscence environment friendly with regards to small queries. DuckDB is predicated on a vectorized execution. It really works with information on massive batches. This system makes use of present CPUs to do important speedups on massive scans and joins. It is usually able to executing quite a few threads to execute a single question at a time.
- Reminiscence and On-Disk Habits: SQLite is designed to make use of minimal reminiscence. It reads from disk as wanted. DuckDB makes use of reminiscence to reinforce pace. It could execute information greater than out there RAM in out-of-core execution. This means that DuckDB can eat extra RAM, however it’s a lot sooner on an analytical activity. It has been demonstrated that in DuckDB, aggregation queries are 10-100 instances sooner than in SQLite.
The Verdict: When to Use DuckDB vs. SQLite
It is a good guideline to observe in your AI and machine studying tasks.
| Side | Use SQLite when | Use DuckDB when |
|---|---|---|
| Main objective | You want a light-weight transactional database | You want quick native analytics |
| Information measurement | Low information quantity, up to a couple hundred MBs | Medium to massive datasets |
| Workload sort | Inserts, updates, and easy lookups | Aggregations, joins, and enormous desk scans |
| Transaction wants | Frequent small updates with transactional integrity | Learn-heavy analytical queries |
| File dealing with | Information saved contained in the database | Question CSV or Parquet information instantly |
| Efficiency focus | Minimal footprint and ease | Excessive-speed analytical efficiency |
| Integration | Cellular apps, embedded programs, IoT | Accelerating Pandas-based evaluation |
| Parallel execution | Not a precedence | Makes use of a number of CPU cores |
| Typical use case | Software state and light-weight storage | Native information exploration and analytics |
Conclusion
Each SQLite and DuckDB are robust embedded databases. SQLite is an excellent light-weight information storage and easy-going transaction device. Nevertheless, DuckDB can considerably speed up the processing of information and prototyping of AI builders working with huge information. It’s because when you’re conscious of their variations, you’ll know the proper device to make use of in several duties. In case of latest information evaluation and machine studying processes, DuckDB can prevent a whole lot of time with a substantial efficiency profit.
Regularly Requested Questions
A. No, they’re of different makes use of. DuckDB is used to entry quick analytics (OLAP), whereas SQLite is used to enter into dependable transactions. Choose in accordance with your workload.
A. SQLite is usually extra suited to internet purposes which have a lot of small, speaking reads and writes as a result of it has a sound transactional mannequin and WAL mode.
A. Sure, with most large-scale jobs, comparable to group-bys and joins, DuckDB is usually a lot sooner than Pandas because of its parallel, vectorized engine.
Harsh Mishra is an AI/ML Engineer who spends extra time speaking to Giant Language Fashions than precise people. Obsessed with GenAI, NLP, and making machines smarter (so that they don’t exchange him simply but). When not optimizing fashions, he’s most likely optimizing his espresso consumption. 🚀☕
Login to proceed studying and luxuriate in expert-curated content material.