
{kind=link}
On this put up, you’ll learn to use Terraform to automate and streamline your Apache Flink utility lifecycle administration on Amazon Managed Service for Apache Flink. We’ll stroll you thru the entire lifecycle together with deployment, updates, scaling, and troubleshooting widespread points.
Managing Apache Flink functions by way of their complete lifecycle from preliminary deployment to scaling or updating will be complicated and error-prone when performed manually. Groups typically battle with inconsistent deployments throughout environments, problem monitoring configuration adjustments over time, and sophisticated rollback procedures when points come up.
Infrastructure as Code (IaC) addresses these challenges by treating infrastructure configuration as code that may be versioned, examined, and automatic. Whereas there are completely different IaC instruments accessible together with AWS CloudFormation or AWS Cloud Growth Package (AWS CDK), we concentrate on HashiCorp Terraform to automate the entire lifecycle administration of Apache Flink functions on Amazon Managed Service for Apache Flink.
Managed Service for Apache Flink permits you to run Apache Flink jobs at scale with out worrying about managing clusters and provisioning sources. You may concentrate on creating your Apache Flink utilizing your Built-in Growth Setting (IDE) of selection, constructing and packaging the appliance utilizing customary construct and CI/CD instruments. As soon as your utility is packaged and uploaded to Amazon S3, you’ll be able to deploy and run it with a serverless expertise.
Whilst you can management your Managed Service for Apache Flink functions instantly utilizing the AWS Console, CLI, or SDKs, Terraform offers key benefits resembling model management of your utility configuration, consistency throughout environments, and seamless CI/CD integration. This put up builds upon our two-part weblog sequence “Deep dive into the Amazon Managed Service for Apache Flink utility lifecycle – Half 1” and “Half 2” that discusses the overall lifecycle ideas of Apache Flink functions.
We use the pattern code revealed on the GitHub repository to show the lifecycle administration. Notice that this isn’t a production-ready resolution.
Organising your Terraform atmosphere
Earlier than you’ll be able to handle your Apache Flink functions with Terraform, you might want to arrange your execution atmosphere. On this part, we’ll cowl the right way to configure Terraform state administration and credential dealing with. The Terraform AWS supplier helps Managed Service for Apache Flink by way of the aws_kinesis_analyticsv2_application useful resource (utilizing the legacy identify “Kinesis Analytics V2“).
Terraform state administration
Terraform makes use of a state file to trace the sources it manages. In Terraform, storing the state file in Amazon S3 is a greatest follow for groups working collaboratively as a result of it offers a centralised, sturdy, and safe location for monitoring infrastructure adjustments. Nonetheless, since a number of engineers or CI/CD pipelines could run Terraform concurrently, state locking is important to forestall race situations the place concurrent executions may corrupt the state. S3 as backend is usually used for state storage and locking, guaranteeing that just one Terraform course of can modify the state at a time, thus sustaining infrastructure consistency and avoiding deployment conflicts.
Passing credentials
To run Terraform inside a Docker container whereas guaranteeing that it has entry to the required AWS credentials and infrastructure code, we observe a structured strategy. This course of entails exporting AWS credentials, mounting required directories, and executing Terraform instructions inside a Docker container. Let’s break this down step-by-step. Earlier than working Terraform, we have to be sure that our Docker container has entry to the required AWS credentials. Since we’re utilizing momentary credentials, we generate them utilizing the AWS CLI with the next command:
aws configure export-credentials --profile $AWS_PROFILE --format env-no-export > .env.dockerThis command does the next:
- It exports AWS credentials from a selected AWS profile (
$AWS_PROFILE). - The credentials are saved in
.env.dockerin a format appropriate for Docker. - The
--format env-no-exportchoice shows credentials as non-exported shell variables
This file (.env.docker) will later be used to go credentials into the Docker container
Operating Terraform in Docker
Operating Terraform inside a Docker container offers a constant, moveable, and remoted atmosphere for managing infrastructure with out requiring Terraform to be put in instantly on the native machine. This strategy ensures that Terraform runs in a managed atmosphere, lowering dependency conflicts and bettering safety. To execute Terraform inside a Docker container, we use a docker run command that mounts the required directories and passes AWS credentials, permitting Terraform to use infrastructure adjustments seamlessly.
The Terraform configuration recordsdata are saved in an area terraform folder, which is nearly connected to the container utilizing the -v flag. This enables the containerised Terraform occasion to entry and modify infrastructure code as if it had been working domestically.
To run Terraform in Docker, the next command is executed:
Breaking down this command step-by-step:
--env-file .env.dockeroffers the AWS credentials required for Terraform to authenticate.--rm -itruns the container interactively and is eliminated after execution to forestall litter.-v ./terraform:/residence/flink-project/terraformmounts the Terraform listing into the container, making the configuration recordsdata accessible.-v ./construct.sh:/residence/flink-project/construct.shmounts theconstruct.shscript, which incorporates the logic to construct JAR file for flink and execute Terraform instructions.msf-terraformis the Docker picture used, which has Terraform pre-installed.bash construct.sh applyruns theconstruct.shscript contained in the container, passingapplyas an argument to set off the Terraform apply course of.
Contained in the container, construct.sh sometimes contains instructions resembling terraform init to initialise the Terraform working listing and terraform apply to use infrastructure adjustments. Because the Terraform execution occurs completely throughout the container, there isn’t a want to put in Terraform domestically, and the method stays constant throughout completely different programs. This technique is especially useful for groups working in collaborative environments, because it standardises Terraform execution and permits for reproducibility throughout improvement, staging, and manufacturing environments.
Managing utility lifecycle with Terraform
On this part, we stroll by way of every part of the Apache Flink utility lifecycle and perceive how one can implement these operations utilizing Terraform. Whereas these operations are normally totally automated as a part of a CI/CD pipeline, you’ll execute the person steps manually from the command line for demonstration functions. There are a lot of methods to run Terraform relying in your group’s tooling and infrastructure setup, however for this demonstration, we run Terraform in a container alongside the appliance construct to simplify dependency administration. In real-world situations, you’d sometimes have separate CI/CD phases for constructing your utility and deploying with Terraform, with distinct configurations for every atmosphere. Since each group has completely different CI/CD tooling and approaches, we preserve these implementation particulars out of scope and concentrate on the core Terraform operations.
For a complete deep dive into Apache Flink utility lifecycle operations, check with our earlier two-part weblog sequence.
Create and begin a brand new utility
To get began you wish to create your Apache Flink utility working on Managed Service for Apache Flink. It is best to execute the next Docker command:
This command will full the next operations by executing the bash script construct.sh:
- Constructing the Java ARchive (JAR) file out of your Apache Flink utility
- Importing the JAR file to S3
- Setting the config variables to your Apache Flink utility in
terraform/config.tfvars.json - Create and deploy the Apache Flink utility to Managed Service for Apache Flink utilizing
terraform apply
Terraform totally covers this operation. You may examine the working Apache Flink utility utilizing AWS CLI or contained in the Managed Apache Flink Console after Terraform completes with Apply Full! Terraform is anticipating the Apache Flink artifact, i.e. the JAR file to be packaged and copied to S3. This operation is normally a part of the CI/CD pipeline and executed earlier than invoking the terraform apply. Right here, the operation is specified within the construct.sh script.
Deploy code change to an utility
You have got efficiently created and began the Flink utility. Nonetheless, you notice that you need to make a change to the Flink utility code. Let’s make a code change to the appliance code in flink/ and see the right way to construct and deploy it. After making the required adjustments, you merely should run the next Docker command once more that builds the JAR file, uploads it to S3 and deploys the Apache Flink utility utilizing Terraform:
This part of the lifecycle is totally supported by Terraform so long as each functions are state suitable, that means that the operators of the upgraded Apache Flink utility are in a position to restore the state from the snapshot that’s taken from the outdated utility model, earlier than Managed Service for Apache Flink stops and deploys the change. For instance, eradicating a stateful operator with out enabling the allowNonRestoredState flag or altering an operator’s UID may stop the brand new utility from restoring from the snapshot. For extra info on state compatibility, check with Upgrading Functions and Flink Variations. For an instance of state incompatibility, and techniques for dealing with state incompatibility, check with Introducing the brand new Amazon Kinesis supply connector for Apache Flink.
When deploying a code change goes fallacious – An issue prevents the appliance code from being deployed
You additionally should be cautious with deploying code adjustments that include bugs stopping the Apache Flink job from beginning. For extra info, check with failure mode (a) – an issue prevents the appliance code from being deployed below When beginning or updating the appliance goes fallacious. For example, this may be simulated by setting the mainClass in flink/pom.xml mistakenly to com.amazonaws.providers.msf.WrongJob. Much like earlier than you construct the JAR, add it and run the terraform apply by working the Docker command from above. Nonetheless, Terraform now fails to accurately apply the adjustments and throws an error message because the Apache Flink utility fails to accurately replace. Lastly, the utility standing strikes to READY.
{kind=link}
To treatment the difficulty, you need to change the worth of mainClass again to the unique one and deploy the adjustments to Managed Service for Apache Flink. The Apache Flink utility stays in READY standing and doesn’t begin mechanically, as this was its state earlier than making use of the repair. Notice that Terraform doesn’t attempt to begin the appliance if you deploy a change. You’ll have to manually begin the Flink utility utilizing the AWS CLI or by way of the Managed Apache Flink Console.
As detailed in Half 2 of the companion weblog, there’s a second failure situation the place the appliance begins efficiently, however the job turns into caught in a steady fail-and-restart loop. A code change also can trigger this failure mode. We’ll cowl the second error situation once we cowl deploying configuration adjustments.
Handbook rollback utility code to earlier utility code
As a part of the lifecycle administration of your Apache Flink utility, you could must explicitly rollback to a earlier working utility model. That is significantly helpful when a newly deployed utility model with utility code adjustments reveals surprising behaviour and also you wish to explicitly rollback the appliance. At the moment, Terraform doesn’t help express rollbacks of your Apache Flink utility working in Managed Service for Apache Flink. You’ll have to resort to therollbackApplication API by way of the AWS CLI or the Managed Service for Apache Flink Console to revert the appliance to the earlier working model.
While you carry out the express rollback, Terraform will initially not pay attention to the adjustments. Extra particularly, the S3 path to the JAR file within the Managed Service for Apache Flink service (see left a part of the picture under) is completely different to the S3 path denoted within the terraform.tfstate file saved in Amazon S3 (see the suitable a part of the picture under). Thankfully, Terraform will all the time carry out refreshing actions that embody studying the present settings from all managed distant objects and updating the Terraform state to match as a part of making a plan in each terraform plan and terraform apply instructions.
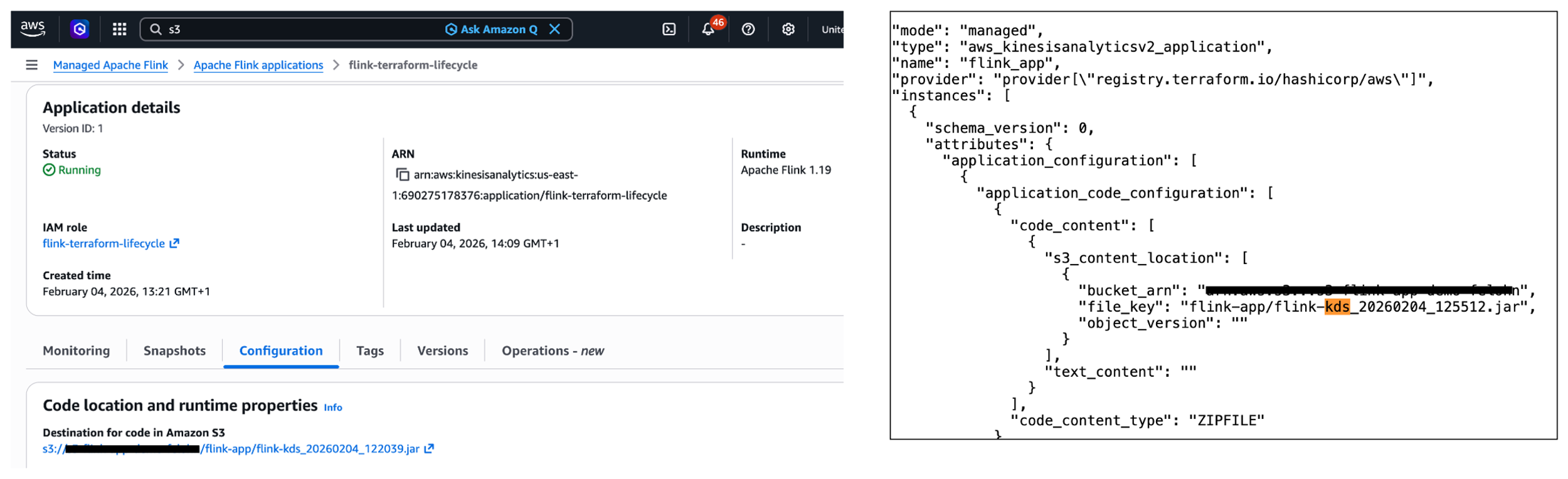
In abstract, whereas you can’t carry out a guide rollback utilizing Terraform, Terraform will mechanically refresh the state when deploying a change utilizing terraform apply.
Deploy config change to utility
You have got already made adjustments to the appliance code of your Apache Flink utility. What about making adjustments to the config of the appliance, e.g., altering runtime parameters? Think about you wish to change the utility logging degree of your working Apache Flink utility. To vary the logging degree from ERROR to INFO, you need to change the worth for flink_app_monitoring_metrics_level within the terraform/config.tfvars.json to INFO. To deploy the config adjustments, you might want to run the docker run command once more as performed within the earlier sections. This situation works as anticipated and is totally lined by Terraform.
What occurs when the Apache Flink utility deploys efficiently however fails and restarts throughout execution? For extra info, please check with failure mode (b) – the appliance is began, the job is caught in a fail-and-restart loop below When beginning or updating the appliance goes fallacious. Notice that this failure mode can occur when making code adjustments as effectively.
When deploying config change goes fallacious – The applying is began, the job is caught in a fail-and-restart loop
Within the following instance, we apply a fallacious configuration change stopping the Kinesis connector from initialising accurately, in the end placing the job in a fail-and-restart loop. To simulate this failure situation, you’ll want to switch the Kinesis stream configuration by altering the stream identify to a non-existent one. This variation is made within the terraform/config.tfvars.json file, particularly altering the stream.identify worth below flink_app_environment_variables. While you deploy with this invalid configuration, the preliminary deployment will seem profitable, displaying an Apply Full! message. The Flink utility standing can even present as RUNNING. Nonetheless, the precise behaviour reveals issues. When you examine the Flink Dashboard, you’ll see the appliance is repeatedly failing and restarting. Additionally, you will notice a warning message in regards to the utility requiring consideration within the AWS Console.
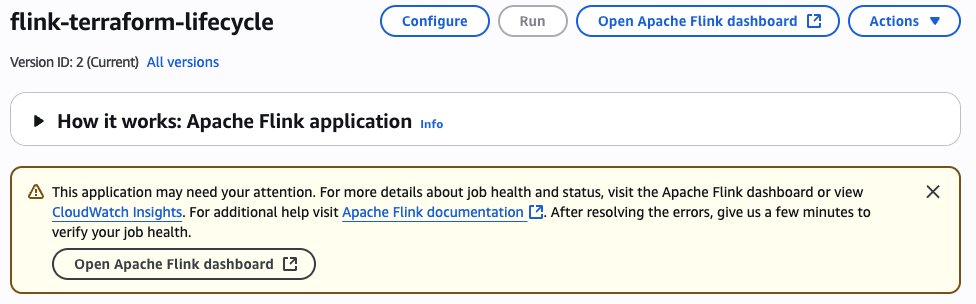
As detailed within the part Monitoring Apache Flink utility operations within the companion weblog (half 2), you’ll be able to monitor the FullRestarts metric to detect the fail-and-restart loop.
Reverting the adjustments made to the atmosphere variable and deploying the adjustments will end in Terraform displaying the next error message: Didn’t take snapshot for the appliance flink-terraform-lifecycle at this second. The applying is presently experiencing downtime.

You must force-stop with no snapshot and restart the appliance with a snapshot to get your Flink utility again to a correctly functioning state. It is best to consistently monitor the appliance state of your Apache Flink utility to detect any points.
Different widespread operations
Manually scaling the appliance
One other widespread operation within the lifecycle of your Apache Flink utility is scaling the appliance up or down by adjusting the parallelism. This operation adjustments the variety of Kinesis Processing Models (KPUs) allotted to your utility. Let’s have a look at two completely different scaling situations and the way they’re dealt with by Terraform.
Within the first situation, you wish to change the parallelism of your working Apache Flink utility throughout the default parallelism quota. To do that, you might want to modify the worth for flink_app_parallelism within the terraform/config.tfvars.json file. After updating the parallelism worth, you deploy the adjustments by working the Docker command as performed within the earlier sections:
This situation works as anticipated and is totally lined by Terraform. The applying will likely be up to date with the brand new parallelism setting, and Managed Service for Apache Flink will modify the allotted KPUs accordingly. Notice that there’s a default quota of 64 KPUs for a single Managed Service for Apache Flink utility, which have to be raised proactively through a quota improve request if you might want to scale your Managed Service for Apache Flink utility past 64 KPUs. For extra info, check with Managed Service for Apache Flink quota.
Much less widespread change deployments which require particular dealing with On this part we analyze some much less widespread change deployment situations which require some particular dealing with.
Deploy code change that removes an operator
Eradicating an operator out of your Apache Flink utility requires particular consideration, significantly concerning state administration. While you take away an operator, the state from that operator nonetheless exists within the newest snapshot, however there’s not a corresponding operator to revive it. Let’s take a better have a look at this situation and perceive how one can deal with it correctly. First, you might want to be sure that the parameter AllowNonRestoredState is ready to True. This parameter specifies whether or not the runtime is allowed to skip a state that can not be mapped to the brand new program, when restoring from a snapshot. Permitting non-restored state is required to efficiently replace an Apache Flink utility if you dropped an operator. To allow the AllowNonRestoredState, you might want to set the configuration worth for flink_app_allow_non_restored_state to true in terraform/config.tfvars.json. Then, you’ll be able to go forward and take away an operator: For instance, you’ll be able to instantly have the sourceStream write to the sink connector in flink/src/important/java/com/amazonaws/providers/msf/StreamingJob.java. Change code line 146 from windowedStream.sinkTo(sink).uid("kinesis-sink")to sourceStream.sinkTo(sink).uid("kinesis-sink"). Just be sure you have commented out the complete windowedStream code block (traces 103 to 140).
This variation will take away the windowed computation and instantly join the supply stream to the sink, successfully eradicating the stateful operation. After eradicating the operator out of your Flink utility code, you deploy the adjustments utilizing the Docker command as beforehand performed. Nonetheless, the deployment fails with the next error message: Couldn’t execute utility. Consequently, the Apache Flink utility strikes to the READY state. To recuperate from this example, you might want to restart the Apache Flink utility utilizing the most recent snapshot for the appliance to efficiently begin and transfer to RUNNING standing. Importantly, you might want to be sure that AllowNonRestoredState is enabled. In any other case, the appliance will fail to start out because it can not restore the state for the eliminated operator.
Deploy change that breaks state compatibility with system rollback enabled
In the course of the lifecycle administration of your Apache Flink utility, you would possibly encounter situations the place code adjustments break state compatibility. This sometimes occurs if you modify stateful operators in ways in which stop them from restoring their state from earlier snapshots.
A standard instance of breaking state compatibility is altering the UID of a stateful operator (resembling an aggregation or windowing operator) in your utility code. To safeguard in opposition to such breaking adjustments, you’ll be able to allow the automated system rollback characteristic in Managed Service for Apache Flink as described within the subsection Rollback below Lifecycle of an utility in Managed Service for Apache Flink beforehand. This characteristic is disabled by default and will be enabled utilizing the AWS Administration Console or invoking the UpdateApplication API operation. There is no such thing as a manner in Terraform to allow system rollback.
Subsequent, let’s show this by breaking the state compatibility of your Apache Flink utility by altering the UID of a stateful operator, e.g., the string windowed-avg-price in line 140 of flink/src/important/java/com/amazonaws/providers/msf/StreamingJob.java to windowed-avg-price-v2 and deploy the adjustments as earlier than. You’ll encounter the next error:
Error: ready for Kinesis Analytics v2 Utility (flink-terraform-lifecycle) operation (*) success: surprising state ‘FAILED’, wished goal ‘SUCCESSFUL’. final error: org.apache.flink.runtime.relaxation.handler.RestHandlerException: Couldn’t execute utility.
At this level, Managed Service for Apache Flink mechanically rolls again the appliance to the earlier snapshot with the earlier JAR file, sustaining your utility’s availability as you’ve got enabled system-rollback functionality. Terraform will initially be not conscious of the carried out rollback. Thankfully, as we’ve already witnessed in subsection Handbook rollback utility code to earlier utility code, Terraform will mechanically refresh the state once we change UID to the earlier worth and deploy the adjustments.
In-place improve of Apache Flink runtime model
Managed Service for Apache Flink helps in-place improve to new Flink runtime variations. See the documentation for extra particulars. Updating the appliance dependencies and any required code adjustments is a duty of the consumer. Upon getting up to date the code artifact, the service is ready to improve the runtime of your working utility in-place, with out knowledge loss. Let’s look at how Terraform handles Flink model upgrades.
To improve your Apache Flink utility from model 1.19.1 to 1.20, you might want to:
- Replace the Flink dependencies in your
flink/pom.xmlto model1.20.0(flink.modelto1.20.1andflink.connector.modelto5.0.0-1.20in - Replace the
flink_app_runtime_environmenttoFLINK-1_20interraform/config.tfvars.json - Construct and deploy the adjustments utilizing the acquainted
docker runcommand
Terraform efficiently performs an in-place improve of your Flink utility. You’ll obtain the next message: Apply full! Assets: 0 added, 1 modified, 0 destroyed.
Operations presently not supported by Terraform
Let’s take a better have a look at operations which are presently not supported by Terraform.
Beginning or stopping the appliance with none configuration change
Terraform offers the start_application parameter, indicating whether or not to start out or cease the appliance. You may set this parameter utilizing flink_app_start in config.tfvars.json to cease your working Apache Flink utility. Nonetheless, this may solely work if the present configuration worth is ready to true. In different phrases, Terraform solely responds to the change within the parameter worth, not absolutely the worth itself. After Terraform applies this modification, your Apache Flink utility will cease and its utility standing will transfer to READY. Equally, restarting the appliance requires altering the flink_app_start worth again to true, however this may solely take impact if the present configuration worth is false. Terraform will then restart your utility, transferring it again to the RUNNING state.
In abstract, you can not begin or cease your Apache Flink utility with out making any configuration change in Terraform. You must use AWS CLI, AWS SDK or AWS Console to start out or cease your utility.
Restarting utility from an older snapshot or no snapshot with none configuration change
Much like the earlier part, Terraform requires an precise configuration change of application_restore_type to set off a restart with completely different snapshot settings. Merely reapplying the identical configuration values received’t provoke a restart from a unique snapshot or no snapshot. You must use AWS CLI, AWS SDK or AWS Console to restart your utility from an older snapshot.
Performing rollback triggered manually or by system-rollback characteristic
Terraform doesn’t help performing a guide rollback nor automated system rollback. As well as, Terraform can even not bear in mind when such a rollback is going down. The state info will likely be outdated, e.g. S3 path info. Nonetheless, Terraform mechanically performs refreshing actions to learn settings from all managed distant objects and updates the Terraform state to match. Consequently, you’ll be able to have Terraform refresh the Terraform state by efficiently working a terraform apply command.
Conclusion
On this put up, we demonstrated the right way to use Terraform to automate the lifecycle administration of your Apache Flink functions on Managed Service for Apache Flink. We walked by way of basic operations together with creating, updating, and scaling functions, explored how Terraform handles varied failure situations and examined superior situations resembling eradicating operators and performing in-place runtime upgrades. We additionally recognized operations which are presently not supported by Terraform.
For extra info, see Run a Managed Service for Apache Flink utility and our two-part weblog on Deep dive into the Amazon Managed Service for Apache Flink utility lifecycle.