
{kind=link}
In e-commerce, delivering quick, related search outcomes helps customers discover merchandise rapidly and precisely, enhancing satisfaction and growing gross sales. OpenSearch is a distributed search engine that gives superior search capabilities together with superior full-text and faceted search, customizable analyzers and tokenizers, and auto-complete to assist prospects rapidly discover the merchandise they need. It scales to deal with tens of millions of merchandise, catalogs and visitors surge. Amazon OpenSearch Service is a managed service that lets customers construct search workloads balancing search high quality, efficiency at scale and price. Designing and sizing an Amazon OpenSearch Service cluster appropriately is required to fulfill these calls for.
Whereas basic sizing tips for OpenSearch Service domains are lined intimately in OpenSearch Service documentation, on this publish we particularly concentrate on T-shirt-sizing OpenSearch Service domains for e-commerce search workloads. T-shirt sizing simplifies advanced capability planning by categorizing workloads into sizes like XS, S, M, L, XL primarily based on key workload parameters reminiscent of information quantity and question concurrency. For e-commerce search, the place information progress is average and read-heavy queries predominate, this method presents a versatile, scalable solution to allocate the assets with out overprovisioning or underestimating wants.
How OpenSearch Service shops indexes and performs queries
E-commerce search platforms deal with huge quantities of information and each day information ingestion is usually comparatively small and incremental, reflecting catalog adjustments, worth updates, stock standing and person actions like clicks and critiques. Effectively managing this information and organizing it per OpenSearch Service greatest practices is essential in reaching optimum efficiency. The workload is read-heavy, consisting of person queries with superior filtering and faceting, particularly throughout gross sales or seasonal spikes that require elasticity in compute and storage assets.
You ingest product and catalog updates (stock, listings, pricing) into OpenSearch utilizing bulk APIs or real-time streaming. You index information into logical indexes. The way you create and arrange indexes in e-commerce has a big affect on search, scalability and suppleness. The method is dependent upon the dimensions, variety and operational wants of the catalog. Small to medium-sized e-commerce platforms generally use a single, complete product index that shops all product info with product class. Further indexes might exist for orders, customers, critiques and promotions relying on search necessities and information separation wants. Giant, various catalogs might break up merchandise into category-specific indexes for tailor-made mappings and scaling. You break up every index into main shards, every storing a portion of the paperwork. To make sure excessive availability and improve question throughput, you configure every main shard with at the very least one duplicate shard saved on totally different information nodes.
Diagram 1. How main and duplicate shards are distributed amongst nodes
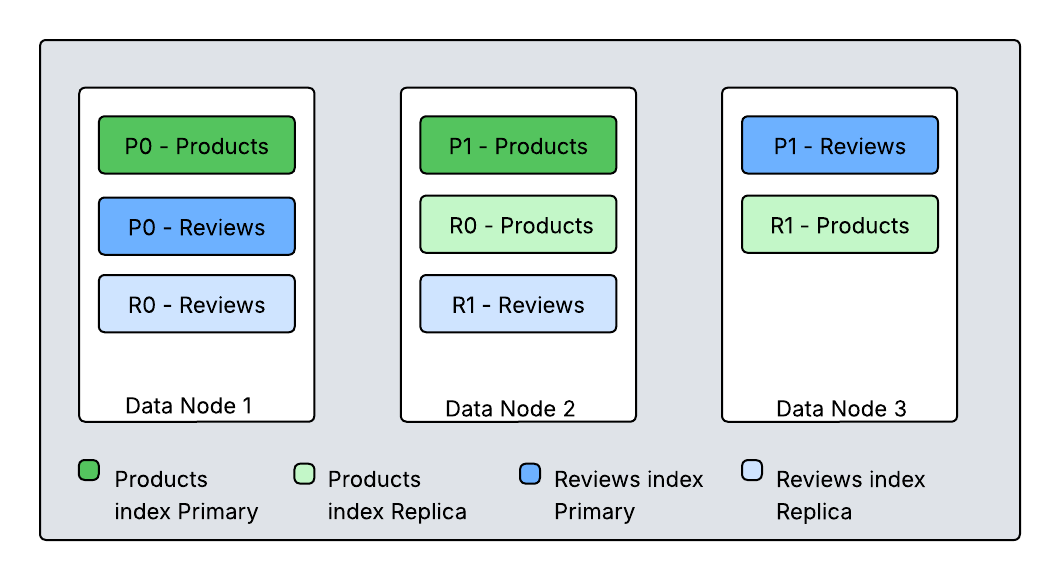{kind=link}
This diagram reveals two indexes (Merchandise and Critiques), every break up into two main shards with one duplicate. OpenSearch distributes these shards throughout cluster nodes to make sure that main and duplicate shards for a similar information don’t reside on the identical node. OpenSearch runs search requests utilizing a scatter-gather mechanism. When an software submits a request, any node within the cluster can obtain it. This receiving node turns into the coordinating node for that particular question. The coordinating node determines which indices and shards can serve the question. It forwards the question to both main or duplicate shards and orchestrates the totally different phases of the search operation and returns the response. This course of ensures environment friendly distribution and execution of search requests throughout the OpenSearch cluster.
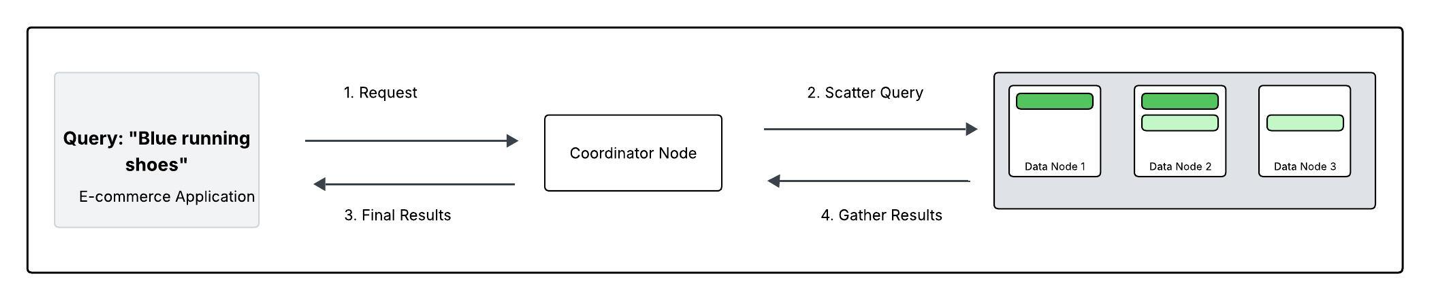
Diagram 2. Tracing a Search question: “blue trainers”This diagram walks via how a search question–for instance, “blue trainers”flows via your OpenSearch Service area .
- Request: The appliance sends the seek for “blue trainers” to the area. One information node acts because the coordinating node.
- Scatter: The coordinator broadcasts the question to both the first or duplicate shard for every of the shards within the ‘Merchandise’ index (Nodes 1, 2, and three on this case).
- Collect: Every information node searches its native shards(s) for “blue trainers” and returns its personal high outcomes (e.g. Node 1 returns its greatest matches from P0).
- Closing outcomes: The coordinator merges these partial lists, kinds them into single definitive record of probably the most related sneakers, and sends the outcome again to the app.
Understanding T-Shirt Sizing for E-commerce OpenSearch Service Cluster
Storage planning
Storage impacts each efficiency and price. OpenSearch Service presents two essential storage choices primarily based on question latency necessities and information persistence wants. Deciding on the suitable storage sort in a managed OpenSearch Service improves each efficiency and optimizes price of the area. You possibly can select between Amazon Elastic Block Retailer( EBS) storage volumes and occasion storage volumes (native storage) to your information nodes.
Amazon EBS gp3 volumes supply excessive throughput, whereas the native NVMe SSD volumes, for instance, on the r8gd, i3, or i4i occasion households, supply low latency, quick indexing efficiency and high-speed storage, making them very best for situations the place actual time information updates and excessive search throughput are crucial for search operations. For search workloads that require a steadiness between efficiency and price, situations backed with EBS GP3 SSD volumes present a dependable choice. This SSD storage presents enter/output operations per second (IOPS) which are well-suited for general-purpose search workloads. It additionally permits customers to provision extra IOPS and storage as wanted.
When sizing an OpenSearch cluster, begin by estimating complete storage wants primarily based on catalog measurement and anticipated progress. For instance, if the catalog comprises 500,000 inventory conserving items (SKUs), averaging 50KB every; the uncooked information sums to about 25GB. The scale of the uncooked information, nevertheless, is only one facet of the storage necessities. Additionally contemplate the Reproduction rely, indexing overhead (10%), Linux reserves (5%), and OpenSearch Service reserves (20% as much as 20GB) per occasion whereas calculating the required storage.
In abstract,when you have 25GB of information at any given time who need one duplicate, the minimal storage requirement is nearer to 25 * 2 * 1.1 / 0.95 / 0.8 = 72.5 GB. This calculation may be generalized as follows:
Storage requirement = Uncooked information * (1 + variety of replicas) * 1.45
This helps guarantee disk area headroom on all information nodes, stopping shard failures and sustaining search efficiency. Provisioning storage barely past this minimal is really helpful to accommodate future progress and cluster rebalancing.
Information nodes:
For search workloads, compute-optimized situations (C8g) are well-suited for central processing unit (CPU)-intensive operations like nested queries and joins. Nonetheless, general-purpose situations like M8g supply a greater steadiness between CPU and reminiscence. Reminiscence-optimized situations (R8g, R8gd) are really helpful for memory-intensive operations like KNN search, the place bigger reminiscence footprint is required. In massive, advanced deployments, compute-optimized situations like c8g or general-purpose m8g, deal with CPU-intensive duties, offering environment friendly question processing and balanced useful resource allocation. The steadiness between CPU and reminiscence, makes them very best for managing advanced search operations for large-scale information processing. For terribly massive search workloads (tens of TB) the place latency just isn’t a main concern, think about using the brand new Amazon OpenSearch Service Writable heat which helps write operations on heat indices.
| Occasion Class | Finest for customers who… | Examples (AWS) | Traits |
| Common Goal | have average search visitors and need a well-balanced, entry-level setup | M household (M8g) | Balanced CPU & reminiscence, EBS storage. Good place to begin for small to medium-sized catalogs. |
| Compute Optimized | have excessive queries per second (QPS) search visitors or queries contain scoring scripts or advanced filtering | C household (C8) | Excessive CPU-to-memory ratio. Perfect for CPU-bound workloads like many concurrent queries. |
| Reminiscence Optimized | work with massive catalogs, want quick aggregations, or cache rather a lot in reminiscence | R household (R8g) | Extra reminiscence per core. Holds massive indices in reminiscence to hurry up searches and aggregations. |
| Storage Optimized | replace stock steadily or have a lot information that disk entry slows issues down | I household (I3, I4g), Im4gn | NVMe SSD and SSD native storage. Finest for I/O-heavy operations like fixed indexing or massive product catalogs hitting disk steadily. |
Cluster supervisor nodes:
For manufacturing workloads, it is strongly recommended so as to add devoted cluster supervisor nodes to extend the cluster stability and offload cluster administration duties from the info nodes. To decide on the proper occasion sort to your cluster supervisor nodes, assessment the service suggestions primarily based on the OpenSearch model and variety of shards within the cluster.
Sharding technique
As soon as storage necessities are understood, you may examine the indexing technique. You create shards in OpenSearch Service to distribute an index evenly throughout the nodes in a cluster. AWS recommends single product index with class sides for simplicity or partition indexes by class for big or distributed catalogs. The scale and variety of shards per index play an important function in OpenSearch Service efficiency and scalability. The appropriate configuration ensures balanced information distribution, avoids sizzling recognizing, and minimizes coordination overhead on nodes to be used instances that prioritizes question velocity and information freshness.
For read-heavy workloads like e-commerce, the place search latency is the important thing efficiency goal, keep shard sizes between 10-30GB. To attain this, calculate the variety of main shards by dividing your complete index measurement by your goal shard measurement. For instance, when you have a 300GB index and need 20GB shards, configure 15 main shards (300GB ÷ 20GB = 15 shards). Monitor shard sizes utilizing the _cat/shards API and modify the shard rely throughout reindexing if shards develop past the optimum vary.
Add duplicate shards to enhance search question throughput and fault tolerance. The minimal advice is to have one duplicate; you may add extra replicas for prime question throughput necessities. In OpenSearch Service, a shard processes operations like querying single-threaded, that means one thread handles a shard’s duties at a time. Reproduction shards can serve learn requests by distributing them throughout a number of threads and nodes, enabling parallel processing.
T-shirt sizing for an e-commerce workload
In an OpenSearch T-shirt sizing desk, every measurement label (XSmall, Small, Medium, Giant, XLarge) represents a generalized cluster scale class that may assist groups translate technical necessities into easy, actionable capability planning. Every measurement permits architects to rapidly align their catalog measurement, storage necessities, shard planning, CPU and AWS occasion decisions to the cluster assets provisioned, making it simpler to scale infrastructure as enterprise grows.
By referring to this desk, groups can choose the class much like their present workload and use the T-shirt measurement as a place to begin whereas persevering with to refine configuration as they monitor and optimize real-world efficiency. For instance, XSmall is fitted to small catalogs with lots of of 1000’s of merchandise and minimal search visitors. Small clusters are designed for rising catalogs with tens of millions of SKUs, supporting average question volumes and scaling up throughout busy intervals. Medium corresponds to mid-size e-commerce operations dealing with tens of millions of merchandise and better search calls for, whereas Giant matches massive on-line companies with tens of tens of millions of SKUs, requiring sturdy infrastructure for quick, dependable search. XLarge is meant for main marketplaces or world platforms with twenty million or extra SKUs, huge information storage wants, and large concurrent utilization.
| T-shirt measurement | Variety of Merchandise | Catalog Dimension | Storage wanted | Major Shard Rely | Lively Shard Rely | Information Nodes Occasion Sort | Cluster Supervisor Node instanceType |
| XSmall | 500K | 50 GB | 145 GB | 2 | 4 | [2] r8g.xlarge | [3] m8g.massive |
| Small | 2M | 200 GB | 580 GB | 8 | 16 | [2] c8g.4xlarge | [3] m8g.massive |
| Medium | 5M | 500 GB | 1.45 TB | 20 | 40 | [2] c8g.8xlarge | [3] m8g.massive |
| Giant | 10M | 1 TB | 2.9 TB | 40 | 80 | [4] c8g.8xlarge | [3] m8g.massive |
| XLarge | 20M | 2 TB | 5.8 TB | 80 | 160 | [4] c8g.16xlarge | [3] m8g.massive |
- T-shirt measurement: Represents the dimensions of the cluster, starting from XS as much as XL for high-volume workloads.
- Variety of merchandise: The estimated rely of SKUs within the e-commerce catalog, which drives the info quantity.
- Catalog measurement: The whole estimated disk measurement of all listed product information, primarily based on typical SKU doc measurement.
- Storage wanted: The precise storage required after accounting for replicas and overhead, guaranteeing sufficient room for protected and environment friendly operation.
- Major shard rely: The variety of essential index shards chosen to steadiness parallel processing and useful resource administration.
- Lively shard rely: The whole variety of stay shards (main with one duplicate), indicating what number of shards must be distributed for availability and efficiency.
- Information node occasion sort: The really helpful occasion sort to make use of for information nodes, chosen for reminiscence, CPU, and disk throughput.
- Cluster supervisor node occasion sort: The really helpful occasion sort for light-weight, devoted grasp nodes which handle cluster stability and coordination.
Scaling methods for e-commerce workloads
E-commerce platforms regularly face challenges with unpredictable visitors surges and rising product catalogs. To deal with these challenges, OpenSearch Service routinely publishes crucial efficiency metrics to Amazon CloudWatch, enabling customers to watch when particular person nodes attain useful resource limits. These metrics embody CPU utilization exceeding 80%, JVM reminiscence strain above 75%, frequent rubbish assortment pauses, and thread pool rejections.
OpenSearch Service additionally offers sturdy scaling options that keep constant search efficiency throughout various workload calls for. Use the vertical scaling technique to improve occasion varieties from smaller to bigger configurations, reminiscent of m6g.massive to m6g.2xlarge. Whereas vertical scaling triggers a blue-green deployment, scheduling these adjustments throughout off-peak hours minimizes affect on operations.
Use the horizontal scaling technique so as to add extra information nodes for distributing indexing and search operations. This method proves significantly efficient when scaling for visitors progress or growing dataset measurement. In domains with cluster supervisor nodes, including information nodes proceeds easily with out triggering a blue-green deployment. CloudWatch metrics information horizontal scaling selections by monitoring thread pool rejections throughout nodes, indexing latency, and cluster-wide load patterns. Although the method requires shard rebalancing and should briefly affect efficiency, it successfully distributes workload throughout the cluster.
Momentary replicas present a versatile answer for managing high-traffic intervals. By growing duplicate shards via the _settings API, learn throughput may be boosted when wanted. This method presents a dynamic response to altering visitors patterns with out requiring extra substantial infrastructure adjustments.
For extra info on scaling an OpenSearch Service area, please consult with How do I scale up or scale out an OpenSearch Service area?
Monitoring and operational greatest practices
Monitoring key efficiency CloudWatch metrics is important to make sure a well-optimised OpenSearch service area. One of many key elements is sustaining CPU utilization on information nodes beneath 80% to stop question slowdowns. One other metric is guaranteeing that JVM reminiscence strain is maintained beneath 75% on information nodes to stop rubbish assortment (GC) pauses that may have an effect on search response time. OpenSearch service publishes these metrics to CloudWatch at 1 minute interval and customers can create alarms on these metrics for alerts on the manufacturing workloads. Please refer really helpful CloudWatch alarms for OpenSearch Service
P95 question latency needs to be monitored to establish gradual queries and optimize efficiency. One other essential indicator is thread pool rejections. A excessive variety of thread pool rejections can lead to failed search requests, and affecting person expertise. By repeatedly monitoring these CloudWatch metrics, customers can proactively scale assets, optimise queries, and forestall efficiency bottlenecks.
Conclusion
On this publish, we confirmed methods to right-size Amazon OpenSearch Service domains for e-commerce workloads utilizing a T-shirt sizing method. We explored key elements together with storage optimization, sharding methods, scaling strategies, and important Amazon CloudWatch metrics for monitoring efficiency.
To construct a performant search expertise, begin with a smaller deployment and iterate as your corporation scales. Get began with these 5 steps:
- Consider your workload necessities when it comes to storage, search throughput, and search efficiency
- Choose your preliminary T-shirt measurement primarily based in your product catalog measurement and visitors patterns
- Deploy the really helpful sharding technique to your catalog scale
- Load take a look at your cluster utilizing OpenSearch benchmark and re-iterate till efficiency necessities are reached
- Configure Amazon CloudWatch monitoring and alarms, then proceed to watch your manufacturing area
Concerning the authors