
{kind=link}
The time period “Hadoop Cluster” can have many meanings. In the most straightforward sense, it will possibly seek advice from the core parts: HDFS (Hadoop Distributed FileSystem), YARN (Useful resource scheduler), Tez, and batch MapReduce (MapReduce processing engines). In actuality, it’s rather more.
Many different Apache massive knowledge instruments are normally offered and resource-managed by YARN. It isn’t unusual to have HBase (Hadoop column-oriented database), Spark (scalable language), Hive (Hadoop RDBS), Sqoop (database to HDFS device), and Kafka (knowledge pipelines). Some background processes, like Zookeeper, additionally present a method to publish cluster-wide useful resource data.
Each service is put in individually with distinctive configuration settings. As soon as put in, every service requires a daemon to be run on some or the entire cluster nodes. As well as, every service has its personal raft of configuration recordsdata that have to be stored in sync throughout the cluster nodes. For even the only installations, it’s common to have over 100-200 recordsdata on a single server.
As soon as the configuration has been confirmed, start-up dependencies usually require particular providers to be began earlier than others can work. As an illustration, HDFS have to be began earlier than most of the providers will function.
If this is beginning to sound like an administrative nightmare, it’s. These actions will be “scripted-up” on the command line degree utilizing instruments like pdsh (parallel distributed shell). Nonetheless, even that method will get tedious, and it is extremely distinctive for every set up.
The Hadoop distributors developed instruments to assist in these efforts. Cloudera developed Cloudera Supervisor, and Hortonworks (now a part of Cloudera) created open-source Apache Ambari. These instruments offered GUI set up help (device dependencies, configuration, and so forth.) and GUI monitoring and administration interfaces for full clusters. The story will get a bit difficult from this level.
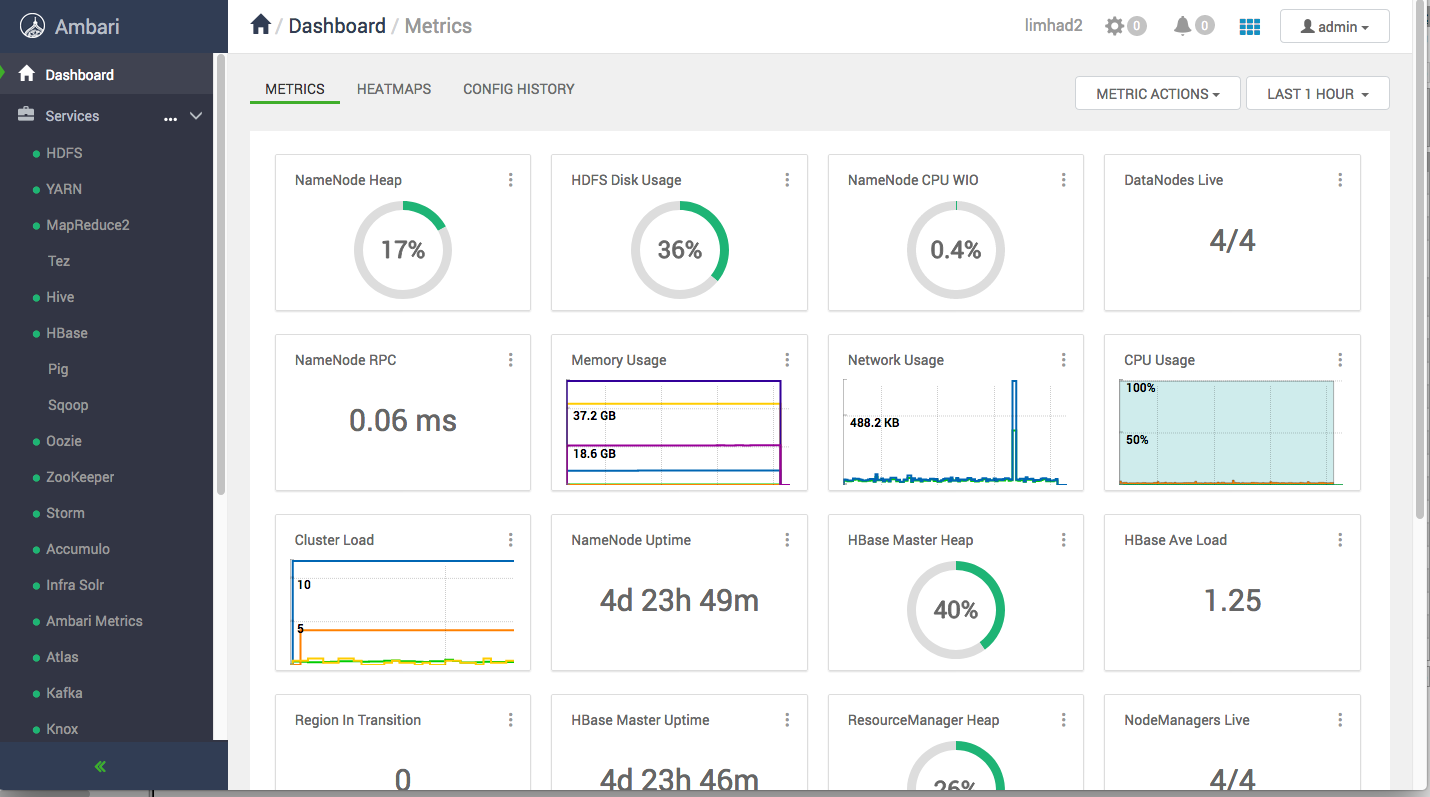
The Ambari Dashboard (Supply: Writer)
The again story
Within the Hadoop world, there have been three massive gamers: Cloudera, Hortonworks, and MapR. Of the three, Hortonworks was usually known as the “Crimson Hat” of the Hadoop world. Lots of their workers had been massive contributors to the open Apache Hadoop ecosystem. Additionally they offered repositories the place RPMs for the varied providers could possibly be freely downloaded. Collectively, these packages had been known as Hortonworks Information Platform or HDP.
As a main creator of the Ambari administration device, Hortonworks offered repositories used as an set up supply for the cluster. The method requires some information of your wants and Hadoop cluster configuration, however generally Ambari may be very environment friendly in creating and managing an open Hadoop cluster (on-prem or within the cloud).
Within the first a part of 2019, Cloudera and Hortonworks merged. Across the identical time, HPE bought MapR.
Someday in 2021, public entry to HDP updates after model 3.1.4 was shut down, making HDP successfully closed supply and requiring a paid subscription from Cloudera. One might nonetheless obtain these packages from the Apache web site, however not in a kind that could possibly be utilized by Ambari.
A lot to the dismay of many directors, this restriction created an orphan ecosystem of open-source Ambari-based clusters and successfully froze these methods at HDP model 3.1.4.
The way in which ahead
In April this 12 months, the Ambari crew launched model 3.0.0 (launch notes) with the next necessary information.
Apache Ambari 3.0.0 represents a big milestone within the mission’s improvement, bringing main enhancements to cluster administration capabilities, consumer expertise, and platform assist.
The largest change is that Ambari now makes use of Apache Bigtop as its default packaging system. This implies a extra sustainable and community-driven method to package deal administration. For those who’re a developer working with Hadoop parts, that is going to make your life a lot simpler!
The shift to Apache Bigtop removes the limitation of the Cloudera HDP subscription wall. The discharge notes additionally state, “The two.7.x collection has reached Finish-of-Life (EOL) and can now not be maintained, as we now not have entry to the HDP packaging supply code.” This alternative is smart as a result of Cloudera ceased mainstream and restricted assist for HDP 3.1 on June 2, 2022.
Essentially the most current launch of BigTop (3.3.0) consists of the next parts that needs to be installable and manageable by means of Ambari.
- alluxio 2.9.3
- bigtop-groovy 2.5.4
- bigtop-jsvc 1.2.4
- bigtop-select 3.3.0
- bigtop-utils 3.3.0
- flink 1.16.2
- hadoop 3.3.6
- hbase 2.4.17
- hive 3.1.3
- kafka 2.8.2
- livy 0.8.0
- phoenix 5.1.3
- ranger 2.4.0
- solr 8.11.2
- spark 3.3.4
- tez 0.10.2
- zeppelin 0.11.0
- zookeeper 3.7.2
The discharge notes for Ambari additionally point out these extra providers and parts
- Alluxio Help: Added assist for Alluxio distributed file system
- Ozone Help: Added Ozone as a file system service
- Livy Help: Added Livy as a person service to the Ambari Bigtop Stack
- Ranger KMS Help: Added Ranger KMS assist
- Ambari Infra Help: Added assist for Ambari Infra in Ambari Server Bigtop Stack
- YARN Timeline Service V2: Added YARN Timeline Service V2 and Registrydns assist
- DFSRouter Help: Added DFSRouter by way of ‘Actions Button’ in HDFS abstract web page
The discharge notes additionally present this compatibility matrix, which covers a variety of working methods and the primary processor architectures.

Ambari compatibility matrix (Supply: Ambari launch notes)
Again on the elephant
Now that Ambari is again on monitor, assist managing open Hadoop ecosystem clusters can proceed. Ambari’s set up and provisioning part manages all wanted dependencies and creates a configuration primarily based on the precise package deal choice. When working Apache massive knowledge clusters, there’s lots of data to handle, and instruments like Ambari assist directors keep away from many points discovered within the complicated interplay of instruments, file methods, and workflow.
Lastly, a particular point out is so as to the Ambari neighborhood for the massive quantity required for this new launch.