Right this moment, most functions can ship a whole bunch of requests for a single web page.
For instance, my Twitter dwelling web page sends round 300 requests, and an Amazon
product particulars web page sends round 600 requests. A few of them are for static
property (JavaScript, CSS, font information, icons, and so forth.), however there are nonetheless
round 100 requests for async knowledge fetching – both for timelines, buddies,
or product suggestions, in addition to analytics occasions. That’s fairly a
lot.
The primary motive a web page could comprise so many requests is to enhance
efficiency and person expertise, particularly to make the appliance really feel
sooner to the top customers. The period of clean pages taking 5 seconds to load is
lengthy gone. In trendy internet functions, customers sometimes see a primary web page with
model and different components in lower than a second, with further items
loading progressively.
Take the Amazon product element web page for example. The navigation and prime
bar seem nearly instantly, adopted by the product photos, transient, and
descriptions. Then, as you scroll, “Sponsored” content material, scores,
suggestions, view histories, and extra seem.Typically, a person solely desires a
fast look or to match merchandise (and verify availability), making
sections like “Clients who purchased this merchandise additionally purchased” much less crucial and
appropriate for loading through separate requests.
Breaking down the content material into smaller items and loading them in
parallel is an efficient technique, however it’s removed from sufficient in massive
functions. There are lots of different facets to think about in relation to
fetch knowledge accurately and effectively. Knowledge fetching is a chellenging, not
solely as a result of the character of async programming would not match our linear mindset,
and there are such a lot of components may cause a community name to fail, but in addition
there are too many not-obvious circumstances to think about below the hood (knowledge
format, safety, cache, token expiry, and so forth.).
On this article, I wish to talk about some frequent issues and
patterns it is best to contemplate in relation to fetching knowledge in your frontend
functions.
We’ll start with the Asynchronous State Handler sample, which decouples
knowledge fetching from the UI, streamlining your utility structure. Subsequent,
we’ll delve into Fallback Markup, enhancing the intuitiveness of your knowledge
fetching logic. To speed up the preliminary knowledge loading course of, we’ll
discover methods for avoiding Request
Waterfall and implementing Parallel Knowledge Fetching. Our dialogue will then cowl Code Splitting to defer
loading non-critical utility elements and Prefetching knowledge based mostly on person
interactions to raise the person expertise.
I consider discussing these ideas by an easy instance is
the most effective strategy. I intention to begin merely after which introduce extra complexity
in a manageable manner. I additionally plan to maintain code snippets, notably for
styling (I am using TailwindCSS for the UI, which can lead to prolonged
snippets in a React part), to a minimal. For these within the
full particulars, I’ve made them obtainable on this
repository.
Developments are additionally occurring on the server aspect, with methods like
Streaming Server-Facet Rendering and Server Elements gaining traction in
numerous frameworks. Moreover, a variety of experimental strategies are
rising. Nonetheless, these matters, whereas probably simply as essential, is likely to be
explored in a future article. For now, this dialogue will focus
solely on front-end knowledge fetching patterns.
It is essential to notice that the methods we’re overlaying will not be
unique to React or any particular frontend framework or library. I’ve
chosen React for illustration functions attributable to my intensive expertise with
it lately. Nonetheless, rules like Code Splitting,
Prefetching are
relevant throughout frameworks like Angular or Vue.js. The examples I am going to share
are frequent eventualities you would possibly encounter in frontend growth, regardless
of the framework you employ.
That stated, let’s dive into the instance we’re going to make use of all through the
article, a Profile display screen of a Single-Web page Utility. It is a typical
utility you may need used earlier than, or no less than the situation is typical.
We have to fetch knowledge from server aspect after which at frontend to construct the UI
dynamically with JavaScript.
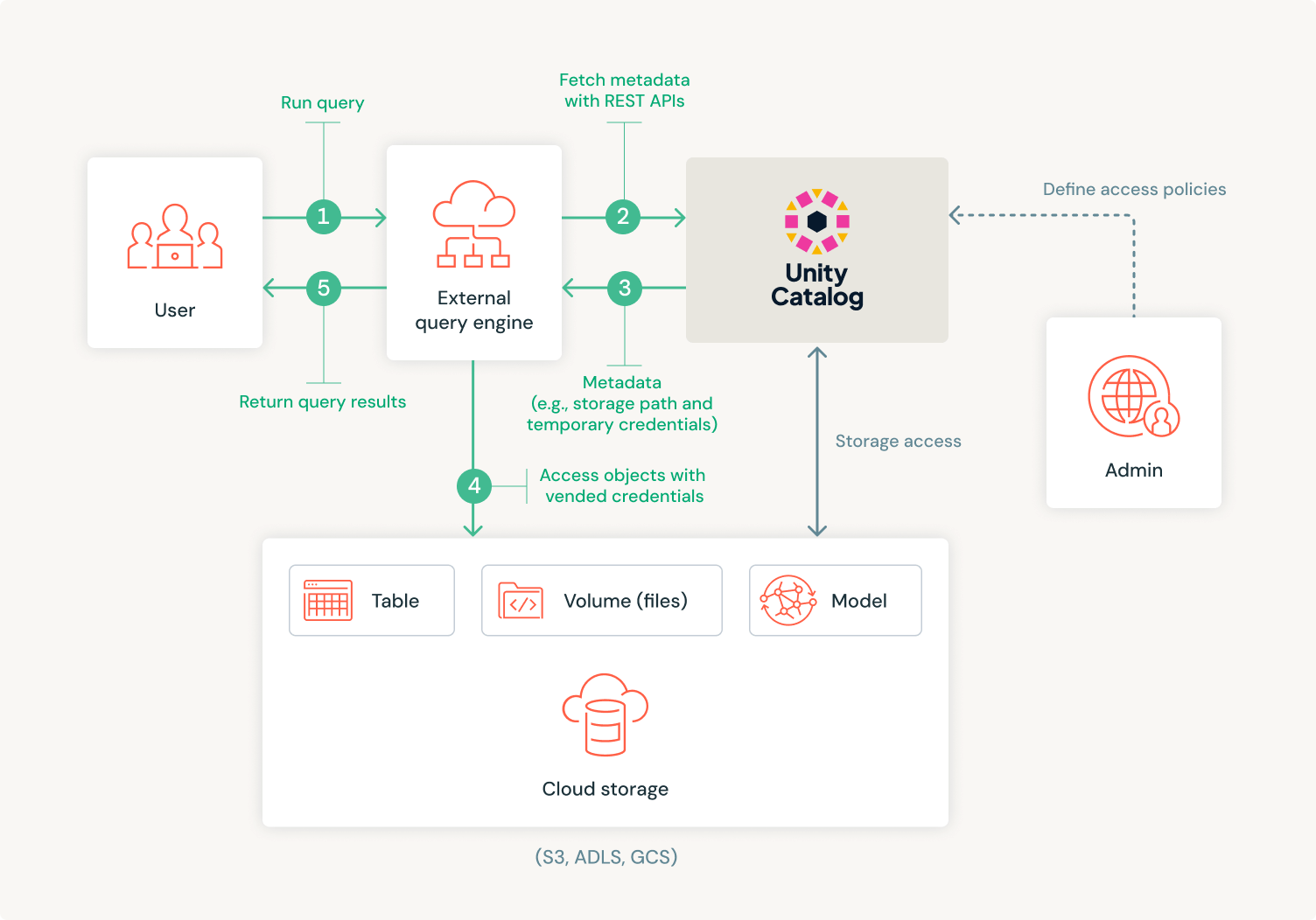
Introducing the appliance
To start with, on Profile we’ll present the person’s transient (together with
identify, avatar, and a brief description), after which we additionally wish to present
their connections (just like followers on Twitter or LinkedIn
connections). We’ll must fetch person and their connections knowledge from
distant service, after which assembling these knowledge with UI on the display screen.
Determine 1: Profile display screen
The information are from two separate API calls, the person transient API
/customers/ returns person transient for a given person id, which is an easy
object described as follows:
{
"id": "u1",
"identify": "Juntao Qiu",
"bio": "Developer, Educator, Creator",
"pursuits": [
"Technology",
"Outdoors",
"Travel"
]
}
And the pal API /customers/ endpoint returns an inventory of
buddies for a given person, every listing merchandise within the response is identical as
the above person knowledge. The rationale we’ve two endpoints as a substitute of returning
a buddies part of the person API is that there are circumstances the place one
might have too many buddies (say 1,000), however most individuals do not have many.
This in-balance knowledge construction could be fairly difficult, particularly after we
must paginate. The purpose right here is that there are circumstances we have to deal
with a number of community requests.
A short introduction to related React ideas
As this text leverages React as an instance numerous patterns, I do
not assume you realize a lot about React. Moderately than anticipating you to spend so much
of time looking for the appropriate elements within the React documentation, I’ll
briefly introduce these ideas we’ll make the most of all through this
article. If you happen to already perceive what React parts are, and the
use of the
useState and useEffect hooks, chances are you’ll
use this hyperlink to skip forward to the following
part.
For these searching for a extra thorough tutorial, the new React documentation is a superb
useful resource.
What’s a React Part?
In React, parts are the basic constructing blocks. To place it
merely, a React part is a operate that returns a bit of UI,
which could be as simple as a fraction of HTML. Contemplate the
creation of a part that renders a navigation bar:
import React from 'react';
operate Navigation() {
return (
);
}
At first look, the combination of JavaScript with HTML tags may appear
unusual (it is referred to as JSX, a syntax extension to JavaScript. For these
utilizing TypeScript, an analogous syntax referred to as TSX is used). To make this
code purposeful, a compiler is required to translate the JSX into legitimate
JavaScript code. After being compiled by Babel,
the code would roughly translate to the next:
operate Navigation() {
return React.createElement(
"nav",
null,
React.createElement(
"ol",
null,
React.createElement("li", null, "House"),
React.createElement("li", null, "Blogs"),
React.createElement("li", null, "Books")
)
);
}
Word right here the translated code has a operate referred to as
React.createElement, which is a foundational operate in
React for creating components. JSX written in React parts is compiled
all the way down to React.createElement calls behind the scenes.
The essential syntax of React.createElement is:
React.createElement(sort, [props], [...children])
sort: A string (e.g., ‘div’, ‘span’) indicating the kind of
DOM node to create, or a React part (class or purposeful) for
extra refined buildings.props: An object containing properties handed to the
component or part, together with occasion handlers, kinds, and attributes
likeclassNameandid.kids: These elective arguments could be further
React.createElementcalls, strings, numbers, or any combine
thereof, representing the component’s kids.
As an illustration, a easy component could be created with
React.createElement as follows:
React.createElement('div', { className: 'greeting' }, 'Howdy, world!');
That is analogous to the JSX model:
Howdy, world!
Beneath the floor, React invokes the native DOM API (e.g.,
doc.createElement(“ol”)) to generate DOM components as obligatory.
You’ll be able to then assemble your customized parts right into a tree, just like
HTML code:
import React from 'react';
import Navigation from './Navigation.tsx';
import Content material from './Content material.tsx';
import Sidebar from './Sidebar.tsx';
import ProductList from './ProductList.tsx';
operate App() {
return
;
}
Finally, your utility requires a root node to mount to, at
which level React assumes management and manages subsequent renders and
re-renders:
import ReactDOM from "react-dom/consumer";
import App from "./App.tsx";
const root = ReactDOM.createRoot(doc.getElementById('root'));
root.render(
Producing Dynamic Content material with JSX
The preliminary instance demonstrates an easy use case, however
let’s discover how we are able to create content material dynamically. As an illustration, how
can we generate an inventory of knowledge dynamically? In React, as illustrated
earlier, a part is essentially a operate, enabling us to go
parameters to it.
import React from 'react';
operate Navigation({ nav }) {
return (
);
}
On this modified Navigation part, we anticipate the
parameter to be an array of strings. We make the most of the map
operate to iterate over every merchandise, remodeling them into
components. The curly braces {} signify
that the enclosed JavaScript expression ought to be evaluated and
rendered. For these curious in regards to the compiled model of this dynamic
content material dealing with:
operate Navigation(props) {
var nav = props.nav;
return React.createElement(
"nav",
null,
React.createElement(
"ol",
null,
nav.map(operate(merchandise) {
return React.createElement("li", { key: merchandise }, merchandise);
})
)
);
}
As an alternative of invoking Navigation as an everyday operate,
using JSX syntax renders the part invocation extra akin to
writing markup, enhancing readability:
// As an alternative of this Navigation(["Home", "Blogs", "Books"]) // We do that
Components in React can receive diverse data, known as props, to
modify their behavior, much like passing arguments into a function (the
distinction lies in using JSX syntax, making the code more familiar and
readable to those with HTML knowledge, which aligns well with the skill
set of most frontend developers).
import React from 'react';
import Checkbox from './Checkbox';
import BookList from './BookList';
function App() {
let showNewOnly = false; // This flag's value is typically set based on specific logic.
const filteredBooks = showNewOnly
? booksData.filter(book => book.isNewPublished)
: booksData;
return (
Show New Published Books Only
);
}
In this illustrative code snippet (non-functional but intended to
demonstrate the concept), we manipulate the BookList
component’s displayed content by passing it an array of books. Depending
on the showNewOnly flag, this array is either all available
books or only those that are newly published, showcasing how props can
be used to dynamically adjust component output.
Managing Internal State Between Renders: useState
Building user interfaces (UI) often transcends the generation of
static HTML. Components frequently need to “remember” certain states and
respond to user interactions dynamically. For instance, when a user
clicks an “Add” button in a Product component, it’s necessary to update
the ShoppingCart component to reflect both the total price and the
updated item list.
In the previous code snippet, attempting to set the
showNewOnly variable to true within an event
handler does not achieve the desired effect:
function App () {
let showNewOnly = false;
const handleCheckboxChange = () => {
showNewOnly = true; // this doesn't work
};
const filteredBooks = showNewOnly
? booksData.filter(book => book.isNewPublished)
: booksData;
return (
Show New Published Books Only
);
};
This approach falls short because local variables inside a function
component do not persist between renders. When React re-renders this
component, it does so from scratch, disregarding any changes made to
local variables since these do not trigger re-renders. React remains
unaware of the need to update the component to reflect new data.
This limitation underscores the necessity for React’s
state. Specifically, functional components leverage the
useState hook to remember states across renders. Revisiting
the App example, we can effectively remember the
showNewOnly state as follows:
import React, { useState } from 'react';
import Checkbox from './Checkbox';
import BookList from './BookList';
function App () {
const [showNewOnly, setShowNewOnly] = useState(false);
const handleCheckboxChange = () => {
setShowNewOnly(!showNewOnly);
};
const filteredBooks = showNewOnly
? booksData.filter(e-book => e-book.isNewPublished)
: booksData;
return (
Present New Printed Books Solely
);
};
The useState hook is a cornerstone of React’s Hooks system,
launched to allow purposeful parts to handle inner state. It
introduces state to purposeful parts, encapsulated by the next
syntax:
const [state, setState] = useState(initialState);
initialState: This argument is the preliminary
worth of the state variable. It may be a easy worth like a quantity,
string, boolean, or a extra complicated object or array. The
initialStateis simply used throughout the first render to
initialize the state.- Return Worth:
useStatereturns an array with
two components. The primary component is the present state worth, and the
second component is a operate that enables updating this worth. Through the use of
array destructuring, we assign names to those returned objects,
sometimesstateandsetState, although you’ll be able to
select any legitimate variable names. state: Represents the present worth of the
state. It is the worth that can be used within the part’s UI and
logic.setState: A operate to replace the state. This operate
accepts a brand new state worth or a operate that produces a brand new state based mostly
on the earlier state. When referred to as, it schedules an replace to the
part’s state and triggers a re-render to replicate the modifications.
React treats state as a snapshot; updating it would not alter the
current state variable however as a substitute triggers a re-render. Throughout this
re-render, React acknowledges the up to date state, guaranteeing the
BookList part receives the right knowledge, thereby
reflecting the up to date e-book listing to the person. This snapshot-like
conduct of state facilitates the dynamic and responsive nature of React
parts, enabling them to react intuitively to person interactions and
different modifications.
Managing Facet Results: useEffect
Earlier than diving deeper into our dialogue, it is essential to handle the
idea of unwanted side effects. Unwanted side effects are operations that work together with
the surface world from the React ecosystem. Frequent examples embody
fetching knowledge from a distant server or dynamically manipulating the DOM,
reminiscent of altering the web page title.
React is primarily involved with rendering knowledge to the DOM and does
not inherently deal with knowledge fetching or direct DOM manipulation. To
facilitate these unwanted side effects, React supplies the useEffect
hook. This hook permits the execution of unwanted side effects after React has
accomplished its rendering course of. If these unwanted side effects lead to knowledge
modifications, React schedules a re-render to replicate these updates.
The useEffect Hook accepts two arguments:
- A operate containing the aspect impact logic.
- An elective dependency array specifying when the aspect impact ought to be
re-invoked.
Omitting the second argument causes the aspect impact to run after
each render. Offering an empty array [] signifies that your impact
doesn’t rely on any values from props or state, thus not needing to
re-run. Together with particular values within the array means the aspect impact
solely re-executes if these values change.
When coping with asynchronous knowledge fetching, the workflow inside
useEffect entails initiating a community request. As soon as the info is
retrieved, it’s captured through the useState hook, updating the
part’s inner state and preserving the fetched knowledge throughout
renders. React, recognizing the state replace, undertakes one other render
cycle to include the brand new knowledge.
Here is a sensible instance about knowledge fetching and state
administration:
import { useEffect, useState } from "react";
sort Person = {
id: string;
identify: string;
};
const UserSection = ({ id }) => {
const [user, setUser] = useState();
useEffect(() => {
const fetchUser = async () => {
const response = await fetch(`/api/customers/${id}`);
const jsonData = await response.json();
setUser(jsonData);
};
fetchUser();
}, tag:martinfowler.com,2024-05-21:Utilizing-markup-for-fallbacks-when-fetching-data);
return
{person?.identify}
;
};
Within the code snippet above, inside useEffect, an
asynchronous operate fetchUser is outlined after which
instantly invoked. This sample is important as a result of
useEffect doesn’t straight help async capabilities as its
callback. The async operate is outlined to make use of await for
the fetch operation, guaranteeing that the code execution waits for the
response after which processes the JSON knowledge. As soon as the info is on the market,
it updates the part’s state through setUser.
The dependency array tag:martinfowler.com,2024-05-21:Utilizing-markup-for-fallbacks-when-fetching-data on the finish of the
useEffect name ensures that the impact runs once more provided that
id modifications, which prevents pointless community requests on
each render and fetches new person knowledge when the id prop
updates.
This strategy to dealing with asynchronous knowledge fetching inside
useEffect is a normal observe in React growth, providing a
structured and environment friendly approach to combine async operations into the
React part lifecycle.
As well as, in sensible functions, managing completely different states
reminiscent of loading, error, and knowledge presentation is crucial too (we’ll
see it the way it works within the following part). For instance, contemplate
implementing standing indicators inside a Person part to replicate
loading, error, or knowledge states, enhancing the person expertise by
offering suggestions throughout knowledge fetching operations.

Determine 2: Completely different statuses of a
part
This overview provides only a fast glimpse into the ideas utilized
all through this text. For a deeper dive into further ideas and
patterns, I like to recommend exploring the new React
documentation or consulting different on-line sources.
With this basis, it is best to now be geared up to affix me as we delve
into the info fetching patterns mentioned herein.
Implement the Profile part
Let’s create the Profile part to make a request and
render the end result. In typical React functions, this knowledge fetching is
dealt with inside a useEffect block. Here is an instance of how
this is likely to be carried out:
import { useEffect, useState } from "react";
const Profile = ({ id }: { id: string }) => {
const [user, setUser] = useState();
useEffect(() => {
const fetchUser = async () => {
const response = await fetch(`/api/customers/${id}`);
const jsonData = await response.json();
setUser(jsonData);
};
fetchUser();
}, tag:martinfowler.com,2024-05-21:Utilizing-markup-for-fallbacks-when-fetching-data);
return (
This preliminary strategy assumes community requests full
instantaneously, which is usually not the case. Actual-world eventualities require
dealing with various community situations, together with delays and failures. To
handle these successfully, we incorporate loading and error states into our
part. This addition permits us to offer suggestions to the person throughout
knowledge fetching, reminiscent of displaying a loading indicator or a skeleton display screen
if the info is delayed, and dealing with errors after they happen.
Right here’s how the improved part appears with added loading and error
administration:
import { useEffect, useState } from "react";
import { get } from "../utils.ts";
import sort { Person } from "../varieties.ts";
const Profile = ({ id }: { id: string }) => {
const [loading, setLoading] = useState(false);
const [error, setError] = useState();
const [user, setUser] = useState();
useEffect(() => {
const fetchUser = async () => {
attempt {
setLoading(true);
const knowledge = await get(`/customers/${id}`);
setUser(knowledge);
} catch (e) {
setError(e as Error);
} lastly {
setLoading(false);
}
};
fetchUser();
}, tag:martinfowler.com,2024-05-21:Utilizing-markup-for-fallbacks-when-fetching-data);
if (loading || !person) {
return Loading...
;
}
return (
{person &&
Now in Profile part, we provoke states for loading,
errors, and person knowledge with useState. Utilizing
useEffect, we fetch person knowledge based mostly on id,
toggling loading standing and dealing with errors accordingly. Upon profitable
knowledge retrieval, we replace the person state, else show a loading
indicator.
The get operate, as demonstrated under, simplifies
fetching knowledge from a selected endpoint by appending the endpoint to a
predefined base URL. It checks the response’s success standing and both
returns the parsed JSON knowledge or throws an error for unsuccessful requests,
streamlining error dealing with and knowledge retrieval in our utility. Word
it is pure TypeScript code and can be utilized in different non-React elements of the
utility.
const baseurl = "https://icodeit.com.au/api/v2"; async operate get(url: string): Promise { const response = await fetch(`${baseurl}${url}`); if (!response.okay) { throw new Error("Community response was not okay"); } return await response.json() as Promise ; }
React will attempt to render the part initially, however as the info
person isn’t obtainable, it returns “loading…” in a
div. Then the useEffect is invoked, and the
request is kicked off. As soon as sooner or later, the response returns, React
re-renders the Profile part with person
fulfilled, so now you can see the person part with identify, avatar, and
title.
If we visualize the timeline of the above code, you will notice
the next sequence. The browser firstly downloads the HTML web page, and
then when it encounters script tags and magnificence tags, it would cease and
obtain these information, after which parse them to kind the ultimate web page. Word
that this can be a comparatively difficult course of, and I’m oversimplifying
right here, however the primary concept of the sequence is appropriate.
Determine 3: Fetching person
knowledge
So React can begin to render solely when the JS are parsed and executed,
after which it finds the useEffect for knowledge fetching; it has to attend till
the info is on the market for a re-render.
Now within the browser, we are able to see a “loading…” when the appliance
begins, after which after a number of seconds (we are able to simulate such case by add
some delay within the API endpoints) the person transient part exhibits up when knowledge
is loaded.
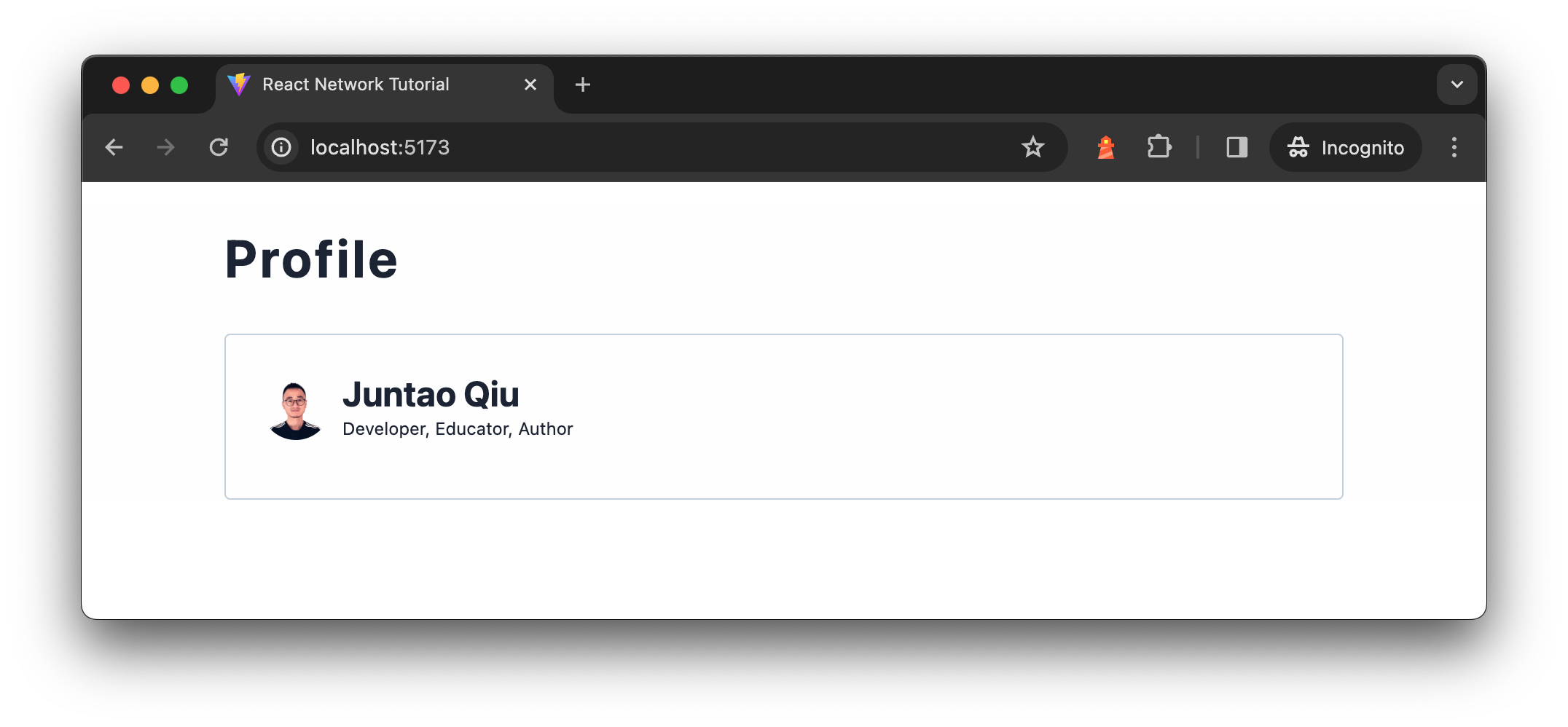
Determine 4: Person transient part
This code construction (in useEffect to set off request, and replace states
like loading and error correspondingly) is
broadly used throughout React codebases. In functions of standard dimension, it is
frequent to seek out quite a few cases of such similar data-fetching logic
dispersed all through numerous parts.
Asynchronous State Handler
Wrap asynchronous queries with meta-queries for the state of the
question.
Distant calls could be gradual, and it is important to not let the UI freeze
whereas these calls are being made. Subsequently, we deal with them asynchronously
and use indicators to point out {that a} course of is underway, which makes the
person expertise higher – figuring out that one thing is occurring.
Moreover, distant calls would possibly fail attributable to connection points,
requiring clear communication of those failures to the person. Subsequently,
it is best to encapsulate every distant name inside a handler module that
manages outcomes, progress updates, and errors. This module permits the UI
to entry metadata in regards to the standing of the decision, enabling it to show
various info or choices if the anticipated outcomes fail to
materialize.
A easy implementation could possibly be a operate getAsyncStates that
returns these metadata, it takes a URL as its parameter and returns an
object containing info important for managing asynchronous
operations. This setup permits us to appropriately reply to completely different
states of a community request, whether or not it is in progress, efficiently
resolved, or has encountered an error.
const { loading, error, knowledge } = getAsyncStates(url);
if (loading) {
// Show a loading spinner
}
if (error) {
// Show an error message
}
// Proceed to render utilizing the info
The belief right here is that getAsyncStates initiates the
community request mechanically upon being referred to as. Nonetheless, this may not
at all times align with the caller’s wants. To supply extra management, we are able to additionally
expose a fetch operate throughout the returned object, permitting
the initiation of the request at a extra acceptable time, in accordance with the
caller’s discretion. Moreover, a refetch operate might
be offered to allow the caller to re-initiate the request as wanted,
reminiscent of after an error or when up to date knowledge is required. The
fetch and refetch capabilities could be similar in
implementation, or refetch would possibly embody logic to verify for
cached outcomes and solely re-fetch knowledge if obligatory.
const { loading, error, knowledge, fetch, refetch } = getAsyncStates(url);
const onInit = () => {
fetch();
};
const onRefreshClicked = () => {
refetch();
};
if (loading) {
// Show a loading spinner
}
if (error) {
// Show an error message
}
// Proceed to render utilizing the info
This sample supplies a flexible strategy to dealing with asynchronous
requests, giving builders the pliability to set off knowledge fetching
explicitly and handle the UI’s response to loading, error, and success
states successfully. By decoupling the fetching logic from its initiation,
functions can adapt extra dynamically to person interactions and different
runtime situations, enhancing the person expertise and utility
reliability.
Implementing Asynchronous State Handler in React with hooks
The sample could be carried out in numerous frontend libraries. For
occasion, we might distill this strategy right into a customized Hook in a React
utility for the Profile part:
import { useEffect, useState } from "react";
import { get } from "../utils.ts";
const useUser = (id: string) => {
const [loading, setLoading] = useState(false);
const [error, setError] = useState();
const [user, setUser] = useState();
useEffect(() => {
const fetchUser = async () => {
attempt {
setLoading(true);
const knowledge = await get(`/customers/${id}`);
setUser(knowledge);
} catch (e) {
setError(e as Error);
} lastly {
setLoading(false);
}
};
fetchUser();
}, tag:martinfowler.com,2024-05-21:Utilizing-markup-for-fallbacks-when-fetching-data);
return {
loading,
error,
person,
};
};
Please observe that within the customized Hook, we have no JSX code –
which means it’s very UI free however sharable stateful logic. And the
useUser launch knowledge mechanically when referred to as. Throughout the Profile
part, leveraging the useUser Hook simplifies its logic:
import { useUser } from './useUser.ts';
import UserBrief from './UserBrief.tsx';
const Profile = ({ id }: { id: string }) => {
const { loading, error, person } = useUser(id);
if (loading || !person) {
return Loading...
;
}
if (error) {
return One thing went improper...
;
}
return (
{person &&
Generalizing Parameter Utilization
In most functions, fetching several types of knowledge—from person
particulars on a homepage to product lists in search outcomes and
suggestions beneath them—is a standard requirement. Writing separate
fetch capabilities for every sort of knowledge could be tedious and troublesome to
keep. A greater strategy is to summary this performance right into a
generic, reusable hook that may deal with numerous knowledge varieties
effectively.
Contemplate treating distant API endpoints as providers, and use a generic
useService hook that accepts a URL as a parameter whereas managing all
the metadata related to an asynchronous request:
import { get } from "../utils.ts";
operate useService(url: string) {
const [loading, setLoading] = useState(false);
const [error, setError] = useState();
const [data, setData] = useState();
const fetch = async () => {
attempt {
setLoading(true);
const knowledge = await get(url);
setData(knowledge);
} catch (e) {
setError(e as Error);
} lastly {
setLoading(false);
}
};
return {
loading,
error,
knowledge,
fetch,
};
}
This hook abstracts the info fetching course of, making it simpler to
combine into any part that should retrieve knowledge from a distant
supply. It additionally centralizes frequent error dealing with eventualities, reminiscent of
treating particular errors otherwise:
import { useService } from './useService.ts';
const {
loading,
error,
knowledge: person,
fetch: fetchUser,
} = useService(`/customers/${id}`);
Through the use of useService, we are able to simplify how parts fetch and deal with
knowledge, making the codebase cleaner and extra maintainable.
Variation of the sample
A variation of the useUser can be expose the
fetchUsers operate, and it doesn’t set off the info
fetching itself:
import { useState } from "react";
const useUser = (id: string) => {
// outline the states
const fetchUser = async () => {
attempt {
setLoading(true);
const knowledge = await get(`/customers/${id}`);
setUser(knowledge);
} catch (e) {
setError(e as Error);
} lastly {
setLoading(false);
}
};
return {
loading,
error,
person,
fetchUser,
};
};
After which on the calling website, Profile part use
useEffect to fetch the info and render completely different
states.
const Profile = ({ id }: { id: string }) => {
const { loading, error, person, fetchUser } = useUser(id);
useEffect(() => {
fetchUser();
}, []);
// render correspondingly
};
The benefit of this division is the flexibility to reuse these stateful
logics throughout completely different parts. As an illustration, one other part
needing the identical knowledge (a person API name with a person ID) can merely import
the useUser Hook and make the most of its states. Completely different UI
parts would possibly select to work together with these states in numerous methods,
maybe utilizing various loading indicators (a smaller spinner that
matches to the calling part) or error messages, but the basic
logic of fetching knowledge stays constant and shared.
When to make use of it
Separating knowledge fetching logic from UI parts can typically
introduce pointless complexity, notably in smaller functions.
Conserving this logic built-in throughout the part, just like the
css-in-js strategy, simplifies navigation and is less complicated for some
builders to handle. In my article, Modularizing
React Functions with Established UI Patterns, I explored
numerous ranges of complexity in utility buildings. For functions
which might be restricted in scope — with just some pages and a number of other knowledge
fetching operations — it is usually sensible and likewise beneficial to
keep knowledge fetching inside the UI parts.
Nonetheless, as your utility scales and the event staff grows,
this technique could result in inefficiencies. Deep part bushes can gradual
down your utility (we are going to see examples in addition to learn how to handle
them within the following sections) and generate redundant boilerplate code.
Introducing an Asynchronous State Handler can mitigate these points by
decoupling knowledge fetching from UI rendering, enhancing each efficiency
and maintainability.
It’s essential to steadiness simplicity with structured approaches as your
undertaking evolves. This ensures your growth practices stay
efficient and conscious of the appliance’s wants, sustaining optimum
efficiency and developer effectivity whatever the undertaking
scale.
Implement the Pals listing
Now let’s take a look on the second part of the Profile – the pal
listing. We are able to create a separate part Pals and fetch knowledge in it
(through the use of a useService customized hook we outlined above), and the logic is
fairly just like what we see above within the Profile part.
const Pals = ({ id }: { id: string }) => {
const { loading, error, knowledge: buddies } = useService(`/customers/${id}/buddies`);
// loading & error dealing with...
return (
Pals
{buddies.map((person) => (
// render person listing
))}
);
};
After which within the Profile part, we are able to use Pals as an everyday
part, and go in id as a prop:
const Profile = ({ id }: { id: string }) => {
//...
return (
{person &&
The code works effective, and it appears fairly clear and readable,
UserBrief renders a person object handed in, whereas
Pals handle its personal knowledge fetching and rendering logic
altogether. If we visualize the part tree, it could be one thing like
this:
Determine 5: Part construction
Each the Profile and Pals have logic for
knowledge fetching, loading checks, and error dealing with. Since there are two
separate knowledge fetching calls, and if we have a look at the request timeline, we
will discover one thing attention-grabbing.
Determine 6: Request waterfall
The Pals part will not provoke knowledge fetching till the person
state is about. That is known as the Fetch-On-Render strategy,
the place the preliminary rendering is paused as a result of the info is not obtainable,
requiring React to attend for the info to be retrieved from the server
aspect.
This ready interval is considerably inefficient, contemplating that whereas
React’s rendering course of solely takes a number of milliseconds, knowledge fetching can
take considerably longer, usually seconds. Consequently, the Pals
part spends most of its time idle, ready for knowledge. This situation
results in a standard problem often called the Request Waterfall, a frequent
prevalence in frontend functions that contain a number of knowledge fetching
operations.
Parallel Knowledge Fetching
Run distant knowledge fetches in parallel to reduce wait time
Think about after we construct a bigger utility {that a} part that
requires knowledge could be deeply nested within the part tree, to make the
matter worse these parts are developed by completely different groups, it’s exhausting
to see whom we’re blocking.
Determine 7: Request waterfall
Request Waterfalls can degrade person
expertise, one thing we intention to keep away from. Analyzing the info, we see that the
person API and buddies API are impartial and could be fetched in parallel.
Initiating these parallel requests turns into crucial for utility
efficiency.
One strategy is to centralize knowledge fetching at a better stage, close to the
root. Early within the utility’s lifecycle, we begin all knowledge fetches
concurrently. Elements depending on this knowledge wait just for the
slowest request, sometimes leading to sooner general load instances.
We might use the Promise API Promise.all to ship
each requests for the person’s primary info and their buddies listing.
Promise.all is a JavaScript technique that enables for the
concurrent execution of a number of guarantees. It takes an array of guarantees
as enter and returns a single Promise that resolves when the entire enter
guarantees have resolved, offering their outcomes as an array. If any of the
guarantees fail, Promise.all instantly rejects with the
motive of the primary promise that rejects.
As an illustration, on the utility’s root, we are able to outline a complete
knowledge mannequin:
sort ProfileState = {
person: Person;
buddies: Person[];
};
const getProfileData = async (id: string) =>
Promise.all([
get(`/users/${id}`),
get(`/users/${id}/friends`),
]);
const App = () => {
// fetch knowledge on the very begining of the appliance launch
const onInit = () => {
const [user, friends] = await getProfileData(id);
}
// render the sub tree correspondingly
}
Implementing Parallel Knowledge Fetching in React
Upon utility launch, knowledge fetching begins, abstracting the
fetching course of from subcomponents. For instance, in Profile part,
each UserBrief and Pals are presentational parts that react to
the handed knowledge. This manner we might develop these part individually
(including kinds for various states, for instance). These presentational
parts usually are straightforward to check and modify as we’ve separate the
knowledge fetching and rendering.
We are able to outline a customized hook useProfileData that facilitates
parallel fetching of knowledge associated to a person and their buddies through the use of
Promise.all. This technique permits simultaneous requests, optimizing the
loading course of and structuring the info right into a predefined format recognized
as ProfileData.
Right here’s a breakdown of the hook implementation:
import { useCallback, useEffect, useState } from "react";
sort ProfileData = {
person: Person;
buddies: Person[];
};
const useProfileData = (id: string) => {
const [loading, setLoading] = useState(false);
const [error, setError] = useState(undefined);
const [profileState, setProfileState] = useState();
const fetchProfileState = useCallback(async () => {
attempt {
setLoading(true);
const [user, friends] = await Promise.all([
get(`/users/${id}`),
get(`/users/${id}/friends`),
]);
setProfileState({ person, buddies });
} catch (e) {
setError(e as Error);
} lastly {
setLoading(false);
}
}, tag:martinfowler.com,2024-05-21:Utilizing-markup-for-fallbacks-when-fetching-data);
return {
loading,
error,
profileState,
fetchProfileState,
};
};
This hook supplies the Profile part with the
obligatory knowledge states (loading, error,
profileState) together with a fetchProfileState
operate, enabling the part to provoke the fetch operation as
wanted. Word right here we use useCallback hook to wrap the async
operate for knowledge fetching. The useCallback hook in React is used to
memoize capabilities, guaranteeing that the identical operate occasion is
maintained throughout part re-renders until its dependencies change.
Just like the useEffect, it accepts the operate and a dependency
array, the operate will solely be recreated if any of those dependencies
change, thereby avoiding unintended conduct in React’s rendering
cycle.
The Profile part makes use of this hook and controls the info fetching
timing through useEffect:
const Profile = ({ id }: { id: string }) => {
const { loading, error, profileState, fetchProfileState } = useProfileData(id);
useEffect(() => {
fetchProfileState();
}, [fetchProfileState]);
if (loading) {
return Loading...
;
}
if (error) {
return One thing went improper...
;
}
return (
{profileState && (
This strategy is also referred to as Fetch-Then-Render, suggesting that the intention
is to provoke requests as early as potential throughout web page load.
Subsequently, the fetched knowledge is utilized to drive React’s rendering of
the appliance, bypassing the necessity to handle knowledge fetching amidst the
rendering course of. This technique simplifies the rendering course of,
making the code simpler to check and modify.
And the part construction, if visualized, can be just like the
following illustration
Determine 8: Part construction after refactoring
And the timeline is way shorter than the earlier one as we ship two
requests in parallel. The Pals part can render in a number of
milliseconds as when it begins to render, the info is already prepared and
handed in.
Determine 9: Parallel requests
Word that the longest wait time relies on the slowest community
request, which is way sooner than the sequential ones. And if we might
ship as many of those impartial requests on the similar time at an higher
stage of the part tree, a greater person expertise could be
anticipated.
As functions broaden, managing an growing variety of requests at
root stage turns into difficult. That is notably true for parts
distant from the basis, the place passing down knowledge turns into cumbersome. One
strategy is to retailer all knowledge globally, accessible through capabilities (like
Redux or the React Context API), avoiding deep prop drilling.
When to make use of it
Working queries in parallel is beneficial at any time when such queries could also be
gradual and do not considerably intervene with every others’ efficiency.
That is often the case with distant queries. Even when the distant
machine’s I/O and computation is quick, there’s at all times potential latency
points within the distant calls. The primary drawback for parallel queries
is setting them up with some sort of asynchronous mechanism, which can be
troublesome in some language environments.
The primary motive to not use parallel knowledge fetching is after we do not
know what knowledge must be fetched till we have already fetched some
knowledge. Sure eventualities require sequential knowledge fetching attributable to
dependencies between requests. As an illustration, contemplate a situation on a
Profile web page the place producing a customized suggestion feed
relies on first buying the person’s pursuits from a person API.
Here is an instance response from the person API that features
pursuits:
{
"id": "u1",
"identify": "Juntao Qiu",
"bio": "Developer, Educator, Creator",
"pursuits": [
"Technology",
"Outdoors",
"Travel"
]
}
In such circumstances, the advice feed can solely be fetched after
receiving the person’s pursuits from the preliminary API name. This
sequential dependency prevents us from using parallel fetching, as
the second request depends on knowledge obtained from the primary.
Given these constraints, it turns into essential to debate various
methods in asynchronous knowledge administration. One such technique is
Fallback Markup. This strategy permits builders to specify what
knowledge is required and the way it ought to be fetched in a manner that clearly
defines dependencies, making it simpler to handle complicated knowledge
relationships in an utility.
One other instance of when arallel Knowledge Fetching shouldn’t be relevant is
that in eventualities involving person interactions that require real-time
knowledge validation.
Contemplate the case of an inventory the place every merchandise has an “Approve” context
menu. When a person clicks on the “Approve” possibility for an merchandise, a dropdown
menu seems providing selections to both “Approve” or “Reject.” If this
merchandise’s approval standing could possibly be modified by one other admin concurrently,
then the menu choices should replicate probably the most present state to keep away from
conflicting actions.

Determine 10: The approval listing that require in-time
states
To deal with this, a service name is initiated every time the context
menu is activated. This service fetches the most recent standing of the merchandise,
guaranteeing that the dropdown is constructed with probably the most correct and
present choices obtainable at that second. Consequently, these requests
can’t be made in parallel with different data-fetching actions for the reason that
dropdown’s contents rely fully on the real-time standing fetched from
the server.
Fallback Markup
Specify fallback shows within the web page markup
This sample leverages abstractions offered by frameworks or libraries
to deal with the info retrieval course of, together with managing states like
loading, success, and error, behind the scenes. It permits builders to
give attention to the construction and presentation of knowledge of their functions,
selling cleaner and extra maintainable code.
Let’s take one other have a look at the Pals part within the above
part. It has to take care of three completely different states and register the
callback in useEffect, setting the flag accurately on the proper time,
prepare the completely different UI for various states:
const Pals = ({ id }: { id: string }) => {
//...
const {
loading,
error,
knowledge: buddies,
fetch: fetchFriends,
} = useService(`/customers/${id}/buddies`);
useEffect(() => {
fetchFriends();
}, []);
if (loading) {
// present loading indicator
}
if (error) {
// present error message part
}
// present the acutal pal listing
};
You’ll discover that inside a part we’ve to take care of
completely different states, even we extract customized Hook to cut back the noise in a
part, we nonetheless must pay good consideration to dealing with
loading and error inside a part. These
boilerplate code could be cumbersome and distracting, usually cluttering the
readability of our codebase.
If we consider declarative API, like how we construct our UI with JSX, the
code could be written within the following method that lets you give attention to
what the part is doing – not learn how to do it:
}> }>
Within the above code snippet, the intention is easy and clear: when an
error happens, ErrorMessage is displayed. Whereas the operation is in
progress, Loading is proven. As soon as the operation completes with out errors,
the Pals part is rendered.
And the code snippet above is fairly similiar to what already be
carried out in a number of libraries (together with React and Vue.js). For instance,
the brand new Suspense in React permits builders to extra successfully handle
asynchronous operations inside their parts, bettering the dealing with of
loading states, error states, and the orchestration of concurrent
duties.
Implementing Fallback Markup in React with Suspense
Suspense in React is a mechanism for effectively dealing with
asynchronous operations, reminiscent of knowledge fetching or useful resource loading, in a
declarative method. By wrapping parts in a Suspense boundary,
builders can specify fallback content material to show whereas ready for the
part’s knowledge dependencies to be fulfilled, streamlining the person
expertise throughout loading states.
Whereas with the Suspense API, within the Pals you describe what you
wish to get after which render:
import useSWR from "swr";
import { get } from "../utils.ts";
operate Pals({ id }: { id: string }) {
const { knowledge: customers } = useSWR("/api/profile", () => get(`/customers/${id}/buddies`), {
suspense: true,
});
return (
Pals
{buddies.map((person) => (
);
}
And declaratively while you use the Pals, you employ
Suspense boundary to wrap across the Pals
part:
}>
Suspense manages the asynchronous loading of the
Pals part, displaying a FriendsSkeleton
placeholder till the part’s knowledge dependencies are
resolved. This setup ensures that the person interface stays responsive
and informative throughout knowledge fetching, bettering the general person
expertise.
Use the sample in Vue.js
It is price noting that Vue.js can be exploring an analogous
experimental sample, the place you’ll be able to make use of Fallback Markup utilizing:
Loading...
Upon the primary render,
its default content material behind the scenes. Ought to it encounter any
asynchronous dependencies throughout this section, it transitions right into a
pending state, the place the fallback content material is displayed as a substitute. As soon as all
the asynchronous dependencies are efficiently loaded,
initially supposed for show (the default slot content material) is
rendered.
Deciding Placement for the Loading Part
It’s possible you’ll marvel the place to position the FriendsSkeleton
part and who ought to handle it. Sometimes, with out utilizing Fallback
Markup, this resolution is easy and dealt with straight throughout the
part that manages the info fetching:
const Pals = ({ id }: { id: string }) => {
// Knowledge fetching logic right here...
if (loading) {
// Show loading indicator
}
if (error) {
// Show error message part
}
// Render the precise pal listing
};
On this setup, the logic for displaying loading indicators or error
messages is of course located throughout the Pals part. Nonetheless,
adopting Fallback Markup shifts this accountability to the
part’s shopper:
}>
In real-world functions, the optimum strategy to dealing with loading
experiences relies upon considerably on the specified person interplay and
the construction of the appliance. As an illustration, a hierarchical loading
strategy the place a mother or father part ceases to point out a loading indicator
whereas its kids parts proceed can disrupt the person expertise.
Thus, it is essential to fastidiously contemplate at what stage throughout the
part hierarchy the loading indicators or skeleton placeholders
ought to be displayed.
Consider Pals and FriendsSkeleton as two
distinct part states—one representing the presence of knowledge, and the
different, the absence. This idea is considerably analogous to utilizing a Particular Case sample in object-oriented
programming, the place FriendsSkeleton serves because the ‘null’
state dealing with for the Pals part.
The secret’s to find out the granularity with which you wish to
show loading indicators and to take care of consistency in these
selections throughout your utility. Doing so helps obtain a smoother and
extra predictable person expertise.
When to make use of it
Utilizing Fallback Markup in your UI simplifies code by enhancing its readability
and maintainability. This sample is especially efficient when using
customary parts for numerous states reminiscent of loading, errors, skeletons, and
empty views throughout your utility. It reduces redundancy and cleans up
boilerplate code, permitting parts to focus solely on rendering and
performance.
Fallback Markup, reminiscent of React’s Suspense, standardizes the dealing with of
asynchronous loading, guaranteeing a constant person expertise. It additionally improves
utility efficiency by optimizing useful resource loading and rendering, which is
particularly helpful in complicated functions with deep part bushes.
Nonetheless, the effectiveness of Fallback Markup relies on the capabilities of
the framework you might be utilizing. For instance, React’s implementation of Suspense for
knowledge fetching nonetheless requires third-party libraries, and Vue’s help for
related options is experimental. Furthermore, whereas Fallback Markup can cut back
complexity in managing state throughout parts, it could introduce overhead in
easier functions the place managing state straight inside parts might
suffice. Moreover, this sample could restrict detailed management over loading and
error states—conditions the place completely different error varieties want distinct dealing with would possibly
not be as simply managed with a generic fallback strategy.
Introducing UserDetailCard part
Let’s say we’d like a characteristic that when customers hover on prime of a Pal,
we present a popup to allow them to see extra particulars about that person.
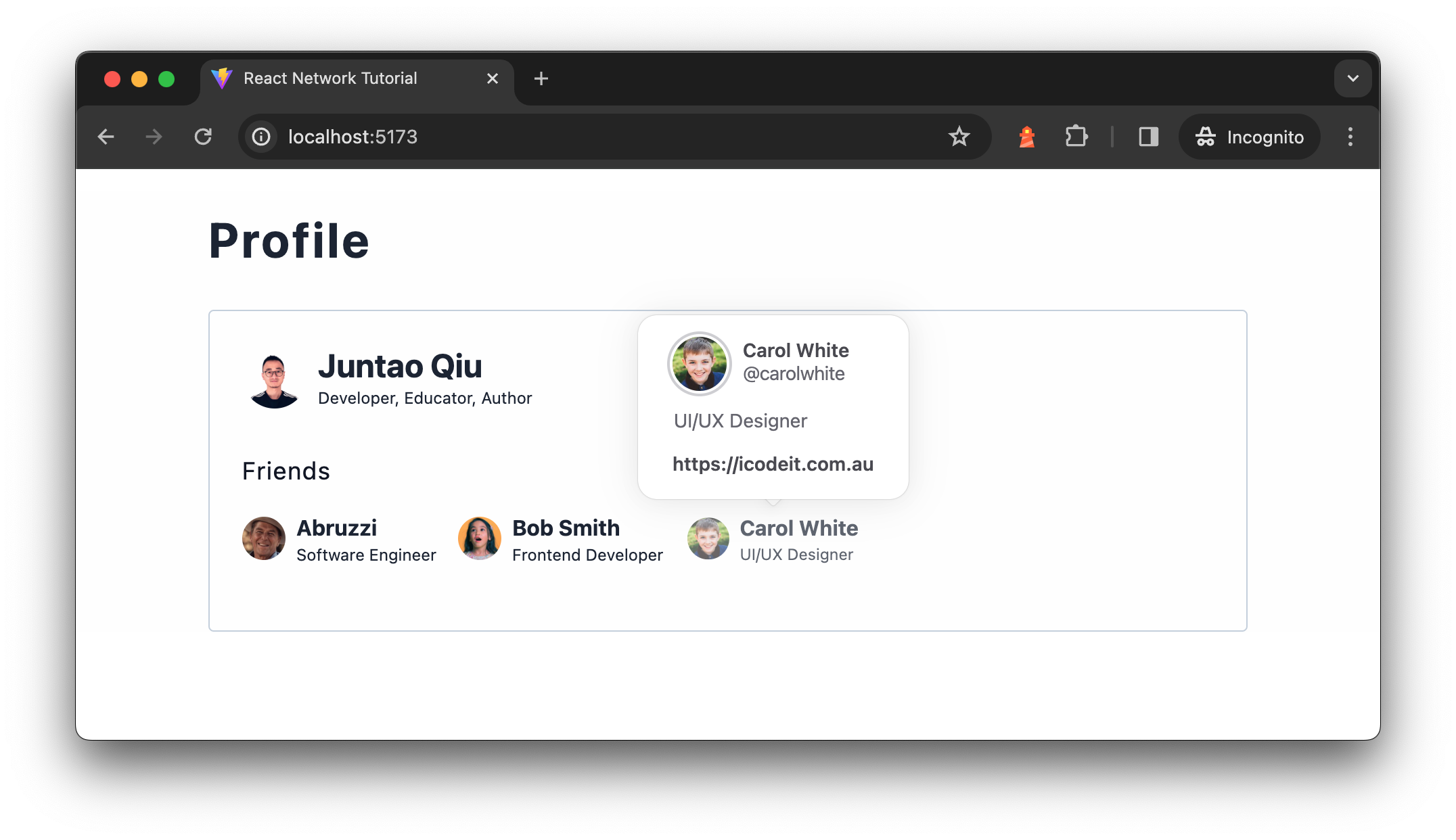
Determine 11: Exhibiting person element
card part when hover
When the popup exhibits up, we have to ship one other service name to get
the person particulars (like their homepage and variety of connections, and so forth.). We
might want to replace the Pal part ((the one we use to
render every merchandise within the Pals listing) ) to one thing just like the
following.
import { Popover, PopoverContent, PopoverTrigger } from "@nextui-org/react";
import { UserBrief } from "./person.tsx";
import UserDetailCard from "./user-detail-card.tsx";
export const Pal = ({ person }: { person: Person }) => {
return (
);
};
The UserDetailCard, is fairly just like the
Profile part, it sends a request to load knowledge after which
renders the end result as soon as it will get the response.
export operate UserDetailCard({ id }: { id: string }) {
const { loading, error, element } = useUserDetail(id);
if (loading || !element) {
return Loading...
;
}
return (
{/* render the person element*/}
);
}
We’re utilizing Popover and the supporting parts from
nextui, which supplies a variety of stunning and out-of-box
parts for constructing trendy UI. The one drawback right here, nonetheless, is that
the package deal itself is comparatively large, additionally not everybody makes use of the characteristic
(hover and present particulars), so loading that further massive package deal for everybody
isn’t very best – it could be higher to load the UserDetailCard
on demand – at any time when it’s required.
Determine 12: Part construction with
UserDetailCard
Code Splitting
Divide code into separate modules and dynamically load them as
wanted.
Code Splitting addresses the difficulty of huge bundle sizes in internet
functions by dividing the bundle into smaller chunks which might be loaded as
wanted, relatively than . This improves preliminary load time and
efficiency, particularly essential for giant functions or these with
many routes.
This optimization is usually carried out at construct time, the place complicated
or sizable modules are segregated into distinct bundles. These are then
dynamically loaded, both in response to person interactions or
preemptively, in a way that doesn’t hinder the crucial rendering path
of the appliance.
Leveraging the Dynamic Import Operator
The dynamic import operator in JavaScript streamlines the method of
loading modules. Although it could resemble a operate name in your code,
reminiscent of import(“./user-detail-card.tsx”), it is essential to
acknowledge that import is definitely a key phrase, not a
operate. This operator permits the asynchronous and dynamic loading of
JavaScript modules.
With dynamic import, you’ll be able to load a module on demand. For instance, we
solely load a module when a button is clicked:
button.addEventListener("click on", (e) => {
import("/modules/some-useful-module.js")
.then((module) => {
module.doSomethingInteresting();
})
.catch(error => {
console.error("Did not load the module:", error);
});
});
The module shouldn’t be loaded throughout the preliminary web page load. As an alternative, the
import() name is positioned inside an occasion listener so it solely
be loaded when, and if, the person interacts with that button.
You should utilize dynamic import operator in React and libraries like
Vue.js. React simplifies the code splitting and lazy load by the
React.lazy and Suspense APIs. By wrapping the
import assertion with React.lazy, and subsequently wrapping
the part, as an example, UserDetailCard, with
Suspense, React defers the part rendering till the
required module is loaded. Throughout this loading section, a fallback UI is
offered, seamlessly transitioning to the precise part upon load
completion.
import React, { Suspense } from "react";
import { Popover, PopoverContent, PopoverTrigger } from "@nextui-org/react";
import { UserBrief } from "./person.tsx";
const UserDetailCard = React.lazy(() => import("./user-detail-card.tsx"));
export const Pal = ({ person }: { person: Person }) => {
return (
Loading...
This snippet defines a Pal part displaying person
particulars inside a popover from Subsequent UI, which seems upon interplay.
It leverages React.lazy for code splitting, loading the
UserDetailCard part solely when wanted. This
lazy-loading, mixed with Suspense, enhances efficiency
by splitting the bundle and displaying a fallback throughout the load.
If we visualize the above code, it renders within the following
sequence.
Word that when the person hovers and we obtain
the JavaScript bundle, there can be some further time for the browser to
parse the JavaScript. As soon as that a part of the work is completed, we are able to get the
person particulars by calling /customers/ API.
Finally, we are able to use that knowledge to render the content material of the popup
UserDetailCard.
Prefetching
Prefetch knowledge earlier than it could be wanted to cut back latency whether it is.
Prefetching includes loading sources or knowledge forward of their precise
want, aiming to lower wait instances throughout subsequent operations. This
method is especially helpful in eventualities the place person actions can
be predicted, reminiscent of navigating to a unique web page or displaying a modal
dialog that requires distant knowledge.
In observe, prefetching could be
carried out utilizing the native HTML tag with a
rel=”preload” attribute, or programmatically through the
fetch API to load knowledge or sources upfront. For knowledge that
is predetermined, the only strategy is to make use of the
tag throughout the HTML :
With this setup, the requests for bootstrap.js and person API are despatched
as quickly because the HTML is parsed, considerably sooner than when different
scripts are processed. The browser will then cache the info, guaranteeing it
is prepared when your utility initializes.
Nonetheless, it is usually not potential to know the exact URLs forward of
time, requiring a extra dynamic strategy to prefetching. That is sometimes
managed programmatically, usually by occasion handlers that set off
prefetching based mostly on person interactions or different situations.
For instance, attaching a mouseover occasion listener to a button can
set off the prefetching of knowledge. This technique permits the info to be fetched
and saved, maybe in an area state or cache, prepared for rapid use
when the precise part or content material requiring the info is interacted with
or rendered. This proactive loading minimizes latency and enhances the
person expertise by having knowledge prepared forward of time.
doc.getElementById('button').addEventListener('mouseover', () => {
fetch(`/person/${person.id}/particulars`)
.then(response => response.json())
.then(knowledge => {
sessionStorage.setItem('userDetails', JSON.stringify(knowledge));
})
.catch(error => console.error(error));
});
And within the place that wants the info to render, it reads from
sessionStorage when obtainable, in any other case displaying a loading indicator.
Usually the person experiense can be a lot sooner.
Implementing Prefetching in React
For instance, we are able to use preload from the
swr package deal (the operate identify is a bit deceptive, however it
is performing a prefetch right here), after which register an
onMouseEnter occasion to the set off part of
Popover,
import { preload } from "swr";
import { getUserDetail } from "../api.ts";
const UserDetailCard = React.lazy(() => import("./user-detail-card.tsx"));
export const Pal = ({ person }: { person: Person }) => {
const handleMouseEnter = () => {
preload(`/person/${person.id}/particulars`, () => getUserDetail(person.id));
};
return (
Loading...}>
);
};
That manner, the popup itself can have a lot much less time to render, which
brings a greater person expertise.
Determine 14: Dynamic load with prefetch
in parallel
So when a person hovers on a Pal, we obtain the
corresponding JavaScript bundle in addition to obtain the info wanted to
render the UserDetailCard, and by the point UserDetailCard
renders, it sees the present knowledge and renders instantly.
Determine 15: Part construction with
dynamic load
As the info fetching and loading is shifted to Pal
part, and for UserDetailCard, it reads from the native
cache maintained by swr.
import useSWR from "swr";
export operate UserDetailCard({ id }: { id: string }) {
const { knowledge: element, isLoading: loading } = useSWR(
`/person/${id}/particulars`,
() => getUserDetail(id)
);
if (loading || !element) {
return Loading...
;
}
return (
{/* render the person element*/}
);
}
This part makes use of the useSWR hook for knowledge fetching,
making the UserDetailCard dynamically load person particulars
based mostly on the given id. useSWR provides environment friendly
knowledge fetching with caching, revalidation, and computerized error dealing with.
The part shows a loading state till the info is fetched. As soon as
the info is on the market, it proceeds to render the person particulars.
In abstract, we have already explored crucial knowledge fetching methods:
Asynchronous State Handler , Parallel Knowledge Fetching ,
Fallback Markup , Code Splitting and Prefetching . Elevating requests for parallel execution
enhances effectivity, although it is not at all times simple, particularly
when coping with parts developed by completely different groups with out full
visibility. Code splitting permits for the dynamic loading of
non-critical sources based mostly on person interplay, like clicks or hovers,
using prefetching to parallelize useful resource loading.
When to make use of it
Contemplate making use of prefetching while you discover that the preliminary load time of
your utility is changing into gradual, or there are various options that are not
instantly obligatory on the preliminary display screen however could possibly be wanted shortly after.
Prefetching is especially helpful for sources which might be triggered by person
interactions, reminiscent of mouse-overs or clicks. Whereas the browser is busy fetching
different sources, reminiscent of JavaScript bundles or property, prefetching can load
further knowledge upfront, thus getting ready for when the person really must
see the content material. By loading sources throughout idle instances, prefetching makes use of the
community extra effectively, spreading the load over time relatively than inflicting spikes
in demand.
It’s clever to comply with a basic guideline: do not implement complicated patterns like
prefetching till they’re clearly wanted. This is likely to be the case if efficiency
points change into obvious, particularly throughout preliminary masses, or if a major
portion of your customers entry the app from cellular units, which usually have
much less bandwidth and slower JavaScript engines. Additionally, contemplate that there are different
efficiency optimization techniques reminiscent of caching at numerous ranges, utilizing CDNs
for static property, and guaranteeing property are compressed. These strategies can improve
efficiency with easier configurations and with out further coding. The
effectiveness of prefetching depends on precisely predicting person actions.
Incorrect assumptions can result in ineffective prefetching and even degrade the
person expertise by delaying the loading of really wanted sources.