
{kind=link}
With the launch of real-time mode (RTM) in Apache Spark 4.1, Structured Streaming now delivers millisecond-level latency. In a latest weblog publish, we confirmed how RTM can outperform Flink for a lot of low latency characteristic engineering workloads (see beneath).
On this weblog, we’ll focus on the architectural modifications that enabled Structured Streaming to help each high-throughput ETL workloads in addition to extremely low-latency workloads.
Apache Spark RTM is quicker than Flink for characteristic engineering use circumstances.
The throughput vs. latency dilemma
Up till now, selecting a streaming engine meant making a trade-off by choosing techniques like Apache Spark for prime throughput ETL workloads, or techniques like Apache Flink for low latency workloads. The 2 techniques have very completely different semantics and efficiency traits. That modifications with RTM in Structured Streaming. With the introduction of RTM, Apache Spark can now deal with each excessive throughput and extremely low-latency use circumstances. This implies it’s now doable to select a single engine with no new studying curve and keep away from managing two utterly completely different techniques.
Microbatch structure delivers excessive throughput
Spark Structured Streaming makes use of a microbatch structure: the streaming system receives enter knowledge and divides it into discrete batches known as epochs based mostly on knowledge availability and most batch measurement configurations. The Spark engine applies the enterprise logic by transformations like venture, filter, and aggregation. The outcomes are output as a steady stream of batches. Structured Streaming excels in high-throughput processing due to this microbatch structure: since a number of data are processed collectively, the mounted overheads are amortized and vectorized execution can additional enhance throughput. These batches are executed in parallel whereas protecting {hardware} utilization excessive. Microbatch mode dynamically allocates activity slots throughout a number of streams which moreover helps with excessive utilization and throughput. Spark’s foundational innovation of lineage based mostly fault tolerance ensures that these streams are processed with robust exactly-once ensures.
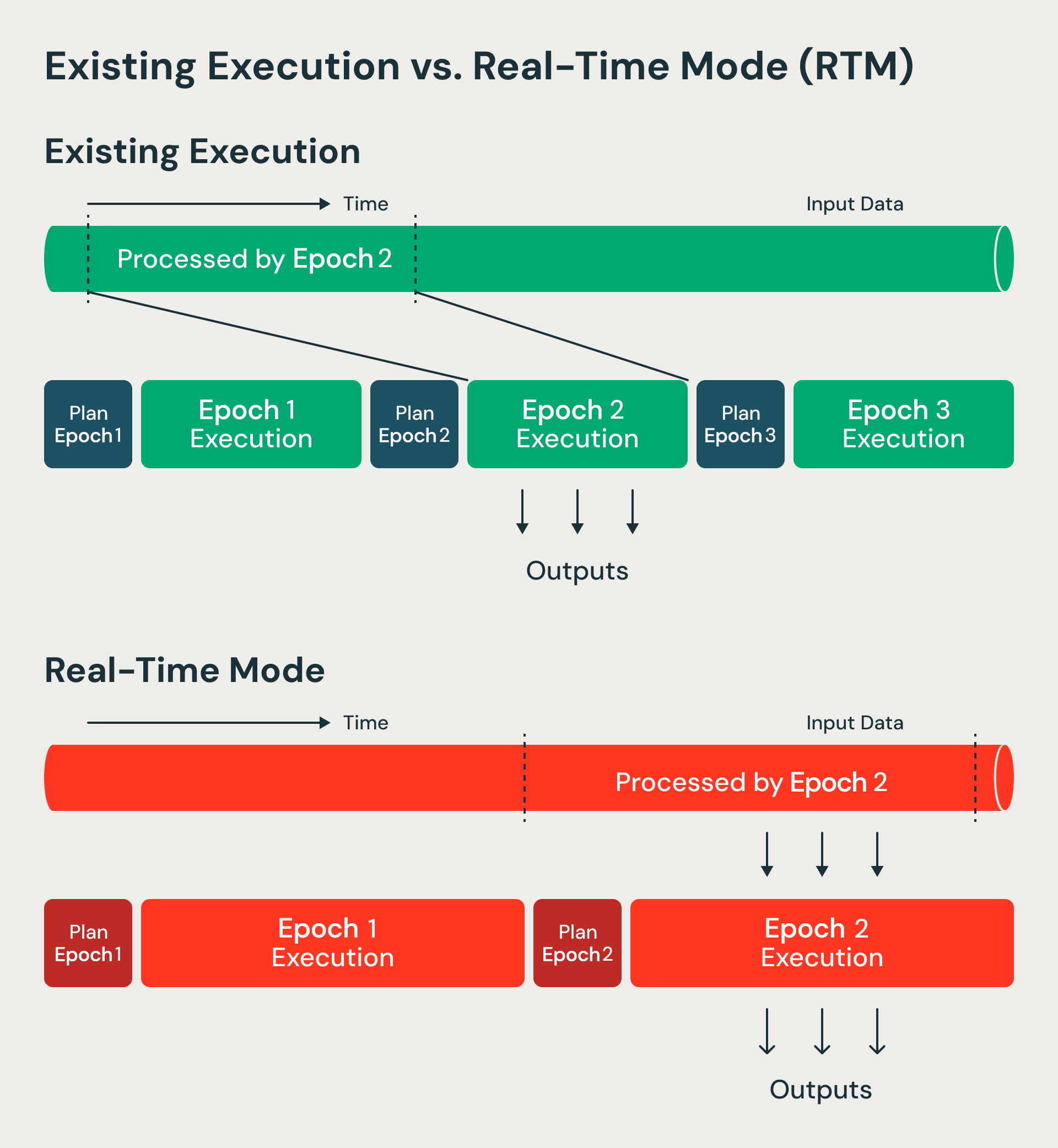
RTM processes knowledge in a non-blocking method in comparison with microbatch mode.
Threading the low-latency needle
Whereas Structured Streaming is superb at dealing with seconds-level ETL and ingestion workloads, many operational use circumstances demand millisecond-level latency. Fraud detection in monetary transactions, real-time insights within the journey business, or analyzing telemetry knowledge from related automobiles are all examples the place clients want solutions in milliseconds.
Architectural problem: Why smaller batches do not work
The plain resolution might sound easy: simply make the batches smaller. If we course of one file at a time, we must always get real-time efficiency. Sadly, it is not that easy.
Every microbatch in Structured Streaming carries mounted prices that dominate execution time when processing small quantities of knowledge. The system writes log recordsdata to sturdy object storage earlier than and after every micro-batch execution. On high of that, state updates for every stateful question must be uploaded to object storage on the finish of a microbatch as properly.These are crucial steps for guaranteeing consistency semantics however can add tons of of milliseconds if not seconds to the execution time. Even when we conceal a few of these latencies, the latency of planning every batch, logical and bodily planning overhead, activity serialization, and scheduling are exhausting to cut back. As you possibly can think about, shrinking batch sizes rapidly hits a wall. The determine beneath reveals when microbatches turn out to be too small (leftmost bar), mounted microbatch processing prices dominate execution and improve finish to finish latency.
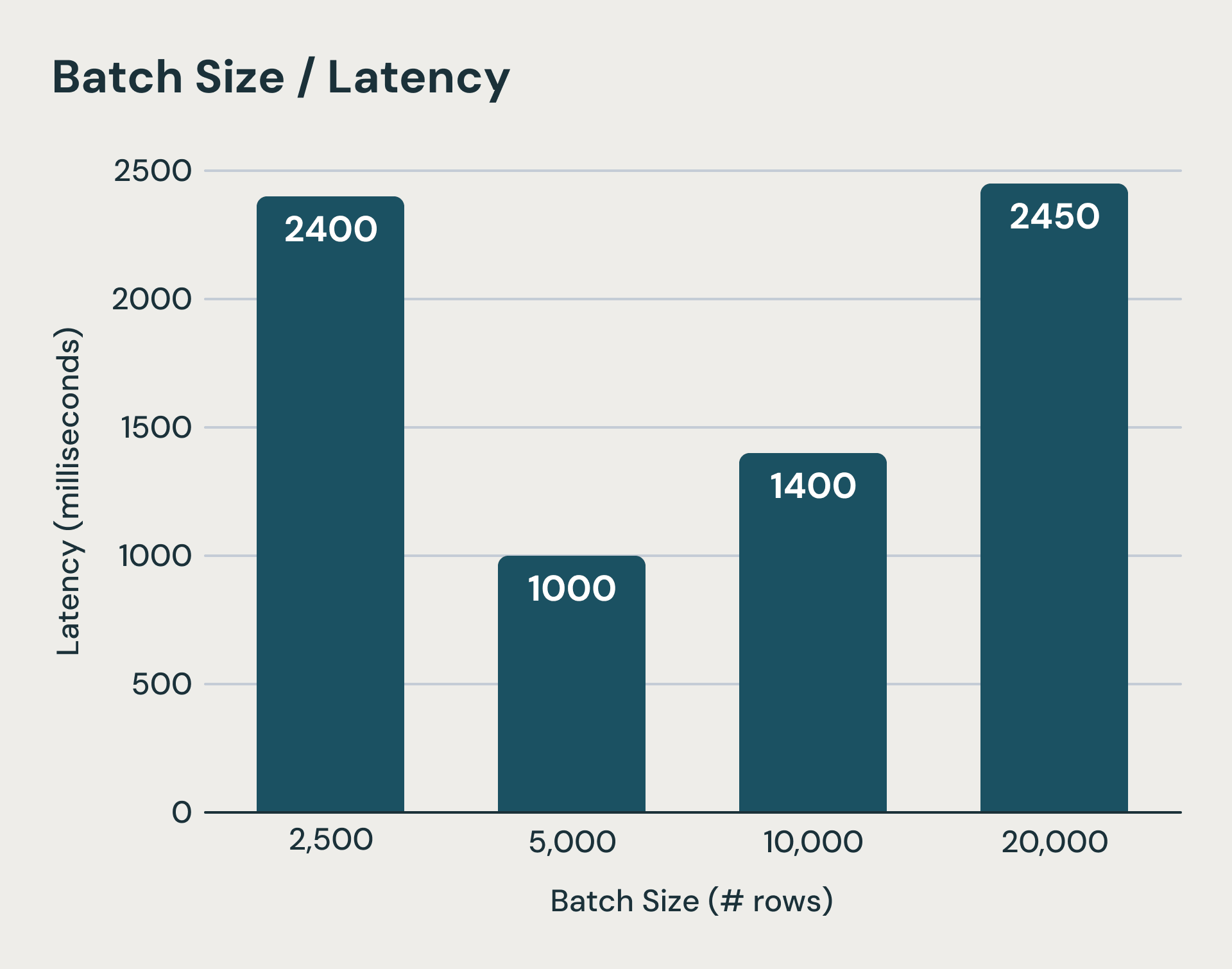
Past a threshold, decrease batch sizes can improve latency as a consequence of mounted overheads
This offered us with an architectural problem: we need to retain the associated fee and fault tolerance benefits of the micro-batch structure whereas reaching low latency that one expects from fashions that course of record-at-a-time (corresponding to Apache Storm and Apache Flink). Our key perception is that we are able to evolve the microbatch structure to help real-time workloads. We continued utilizing lots of the core microbatch structure options corresponding to checkpointing for fault tolerance. Nevertheless, we eradicated the steps the place knowledge used to attend and was leading to excessive latency. We focus on these modifications beneath.
Our resolution: a hybrid execution mannequin
Right here is how we improved Structured Streaming’s latency:
1. Longer period epochs with steady knowledge stream
Microbatch mode processes batches of knowledge known as epochs. Epoch boundaries are determined upfront utilizing begin and finish offsets. Actual-time mode as a substitute processes longer period epochs however modifies how knowledge flows inside every epoch. Information now streams repeatedly by completely different levels and operators with out blocking. Since epochs are of longer period, the overheads of checkpointing and boundaries is amortized. At epoch boundaries, we nonetheless use boundaries for restoration bookkeeping and activity rescheduling—sustaining the advantages that make micro-batch architectures resilient and environment friendly. We primarily advanced the micro-batch in Structured Streaming right into a checkpoint interval.
2. Concurrent processing levels
Within the Structured Streaming structure, processing levels executed sequentially—reducers waited for mappers to finish, creating pointless delays. We made these levels concurrent within the real-time mode. Now the Spark driver requests supply offsets and schedules mappers, however reducers can begin processing shuffle recordsdata as quickly as they turn out to be out there, somewhat than ready for all mappers to complete. This transformation dramatically reduces end-to-end latency. The RTM determine beneath reveals that the 2 levels run concurrently, and stage 2 begins processing rows as quickly as they’re processed by stage 1.
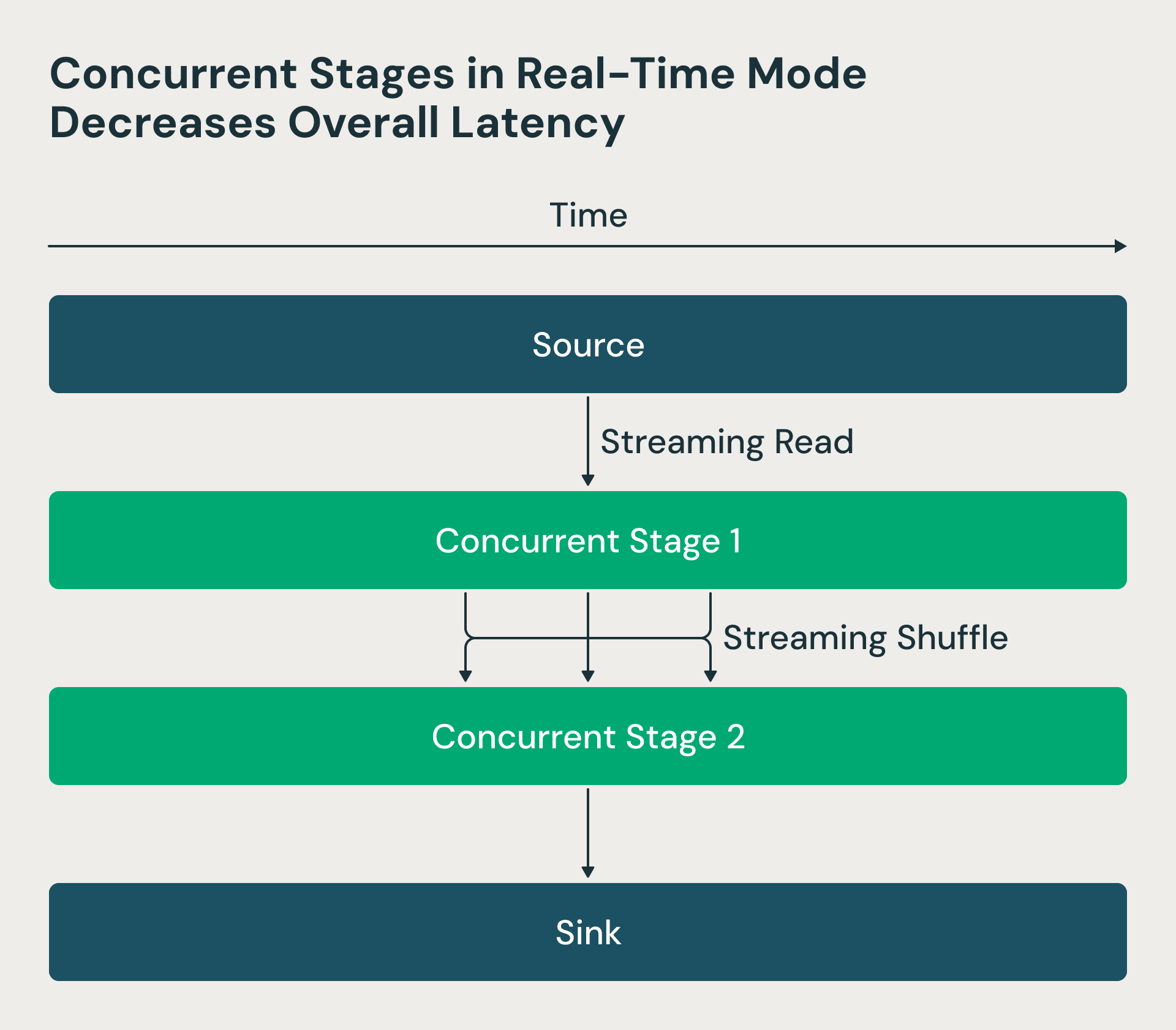
Actual-time mode makes use of concurrent levels which decreases latency
3. Non-blocking operators
We restructured key operators like shuffle, which had been designed for batch execution with substantial buffering. In batch mode, a group-by aggregation would buffer all data, carry out pre-aggregation, and emit outcomes solely on the finish. For real-time processing, we modified these operators to attenuate buffering and produce outcomes repeatedly, permitting knowledge to stream by the pipeline with out pointless waits.
Abstract
By utilizing longer period epochs with steady knowledge stream, concurrent processing levels, and non-blocking operators, we now have generalized Apache Spark Structured Streaming engine to deal with each excessive throughput and extremely low-latency streaming use circumstances. This hybrid method now removes the necessity to decide on between streaming engines. Customers solely have to study Apache Spark and there’s no have to study one other framework devoted for extremely low-latency streaming.
Actual-time mode is already in manufacturing at Databricks and utilized by a number of clients from leading edge finance corporations to journey websites. Our clients are capable of obtain millisecond latency for his or her use circumstances.
Whereas this is a crucial leap in Spark’s capabilities, we’re persevering with so as to add new streaming options. In case your group is searching for options for real-time workloads, take Apache Spark Structured Streaming for a spin!
Discover technical assets
To go deeper into the engineering behind RTM, watch this on-demand session led by our subject material consultants. They are going to walkthrough the design and implementation of Actual-Time Mode.
Or evaluate the Actual-Time Mode technical information on the best way to get began. You’ll discover every thing it’s essential to allow real-time processing on your streaming workloads.