
{kind=link}
When builders be a part of a brand new mission or have to work throughout an unfamiliar codebase, data assistants like Databricks Information Assistant assist them rise up to hurry by answering natural-language questions concerning the code. However reply high quality relies upon closely on how the supply code and surrounding context have been ready and added. One key issue is chunking: the way you cut up supply recordsdata into items for indexing and retrieval. Code makes this tough. Should you break a operate mid-body or strip its class context, even a succesful assistant will wrestle to reply questions on it.
We constructed three Information Assistants over our Casper’s Kitchens demo GitHub repository, every utilizing a unique chunking technique, from a easy fixed-size baseline to a structure-aware strategy that parses code into its syntactic elements. The repository simulates a ghost kitchen enterprise on Databricks, utilizing a variety of options together with Lakeflow pipelines, DSPy brokers, and Databricks Asset Bundles (DABs), with documentation in markdown recordsdata and pocket book cells. The cross-file dependencies, blended file codecs, and domain-specific patterns make it the sort of mission the place a succesful data assistant can be an enormous assist.
This submit walks by what makes working with code completely different from working with typical enterprise paperwork, how we deployed every chunking technique as a Databricks Information Assistant, and the way we used MLflow’s analysis framework to check them. Yow will discover all of the code right here.
How Information Assistants Works (and Why Code Is Completely different)
Underneath the hood, data assistants use varied types of retrieval-augmented technology (RAG). They retrieve related chunks of the supply knowledge, typically from a vector search index, and go them to a big language mannequin as context for producing a solution to a consumer question.
Databricks Information Assistant builds on this basis with subtle retrieval strategies together with Instructed Retriever, which contains question decomposition, context-informed re-ranking, and reasoning over doc metadata. These capabilities go a good distance towards dealing with the complexity of real-world codebases, they usually work finest when the underlying chunks protect significant semantic boundaries.
Information assistants are mostly constructed and evaluated over collections of enterprise paperwork, which are likely to circulate linearly, with paragraphs and sections. Code has nested hierarchies: recordsdata comprise lessons, lessons comprise strategies, strategies comprise logic blocks. The semantic unit in code is commonly a whole operate, not a paragraph.
This creates particular challenges, together with:
- Semantic boundaries: Splitting a operate mid-body loses the context wanted to know what it does. A bit containing
deletion_order = ['experiments', 'jobs'...is less useful if it doesn’t show that this variable is insideUCState.clear_all(). - Cross-file dependencies: Code references other code. Understanding one function often requires context from its class, its imports, or related functions.
- Mixed file types: Our codebase has
.pyfiles,.ipynbnotebooks (JSON with code/Markdown cells),.mddocumentation, and.yamlconfiguration, each requiring different parsing approaches.
Because Databricks Knowledge Assistant lets you use your own vector index, you can prepare chunks however you want and just point Knowledge Assistant at the result. This allowed us to compare different approaches to preparing our codebase for RAG and pick the best one.
Chunking Strategies
To see how chunking strategies differ in practice, consider what happens when you ask: “In what order does resource cleanup occur?” The answer lives in a utility class that tracks experiments, jobs, and pipelines. Its logic spans initialization, a deletion order list, and cleanup methods. Here’s how each method works and how it affects the context retrieved about the resource cleanup class, UCState.
Naive Baseline: Fixed-Size Character Chunks
The simplest approach is to split the source files at fixed character intervals with overlap, treating code as plain text. This is not what you would choose for a production-ready RAG system today. It ignores syntax and semantic boundaries, so it fails in exactly the ways code queries care about. But it’s also extremely easy to implement, often “good enough” for quick experiments or doc-heavy repos, and common as a first pass, so it’s a useful baseline.
Here’s what naive chunking produces for a search of deletion_order in our codebase:
The variable name got cut in two (eletion instead of deletion), and the chunk doesn’t include the method name. If someone searches for “UCState deletion order,” this chunk won’t match well. Furthermore, the deletion_order list in the method got cut off.
Language-Aware: LangChain Heuristic Splitters
LangChain’s RecursiveCharacterTextSplitter.from_language() uses language-specific separators (like nclass and ndef for Python) to prefer splitting at logical boundaries. It tries to keep functions intact but still enforces strict size limits. Conceptually, this improves on naive chunking by prioritizing splits at likely semantic boundaries (like def and class) instead of arbitrary character counts, so chunks are more likely to contain complete units of logic.
Here’s what this approach produced for the same search:
The chunk starts at a more natural boundary, but it still lacks context showing which file or function it belongs to, and it cuts off right after the start of a for loop.
AST-Based: Tree-Sitter with Metadata Headers
Abstract syntax tree–based chunking uses a parser like Tree-sitter to understand actual code structure. An AST is a tree representation of code that captures its syntactic structure—how the code is organized according to a language’s grammar rules. Instead of splitting at character boundaries or using heuristic patterns, an AST-based chunking strategy parses the code into a syntax tree and chunks at semantic boundaries, such as functions, classes, or statement blocks. It can also exceed size limits when necessary to keep a complete unit together, rather than splitting mid-function.
We used the ASTChunk Python library to handle the AST-based splitting. The library includes a chunk expansion option that causes each chunk to be prepended with a metadata header showing the file path and class/function hierarchy. This context becomes part of the embedding, helping retrieval match queries to relevant code even when the query terms don’t appear in the chunk body.
Here’s the chunk this approach produced for our query:
The header tells us exactly where this code lives: utils/uc_state/state_manager.py → class UCState: → def clear_all(...). When embedded, this chunk has a stronger semantic connection to queries about “UCState,” “clear_all,” or “deletion order.”
At this stage, we had some intuitions about which methods would likely work best in our Knowledge Assistant. But to know for sure, we needed to perform a systematic evaluation.
Evaluation Setup with MLflow
MLflow’s GenAI evaluation framework provides a complete toolkit for comparing LLMs, agents, and retrieval systems. You give it an evaluation dataset, a predict function, and LLM judges, and it runs each question through your pipeline and scores the results. Here’s how we used it to compare the three chunking methods.
The Evaluation Dataset
We created 46 questions across a diverse set of categories, ranging from broad conceptual topics to detailed queries about the code.
| Category | Count | Example |
|---|---|---|
| Pinpointing specific values | 7 | “What is the exact deletion order in UCState.clear_all()?” |
| Retrieving complete definitions | 8 | “List all fields and validators in the ComplaintResponse model.” |
| Understanding system flows | 6 | “How does the complaint pipeline work end-to-end, from generation to Lakebase sync?” |
| Comparing app implementations | 13 | “How does parse_agent_response differ between complaints-manager and refund-manager?” |
| Comparing frameworks & patterns | 12 | “What ML framework does each agent use? How do their error handling and streaming patterns differ?” |
We deliberately weighted the dataset toward disambiguation questions where the codebase has structurally similar code in different contexts, like two apps with overlapping function names, parallel database schemas, or configuration files that differ in subtle ways. These are the queries that expose chunking weaknesses most clearly. If your chunks lack metadata about where code lives, the retrieval system will struggle to tell the difference between similar classes and functions that exist in different contexts.
The LLM Judges
We used three main LLM judges, each capturing a different aspect of quality:
RetrievalSufficiency(built-in): Do the retrieved chunks contain enough information to answer the question? This is the key metric for comparing chunking strategies because it measures retrieval quality independent of generation.RetrievalGroundedness(built-in): Is the response grounded in the retrieved context, or does it introduce information not present in the chunks?answer_correctness(custom): This custom scorer ranks each answer as correct, partially correct, or incorrect, making it a little more nuanced than a strict yes/no correctness judge. Given the possibility for fragmented or incomplete context, we want to look out for answers that might be missing details or have small inaccuracies.
Running the Evaluation
To keep the comparison fair, all strategies used the same target chunk size (1,000 characters), overlap (200 characters), and embedding model (databricks-gte-large-en). In practice, the final chunk sizes still differ (for example, AST-based chunking may expand to preserve a full semantic unit, while very small files naturally produce small chunks).
For each chunking strategy, we wrote the chunks to a Delta table, created a Vector Search index with managed embeddings (using the databricks-gte-large-en embedding model, as required by Databricks Knowledge Assistant), and attached the index to a Knowledge Assistant endpoint. The docs cover the full setup.
We evaluated each chunking strategy by querying its Knowledge Assistant endpoint directly. MLflow’s to_predict_fn() wraps a serving endpoint as a predict function, and because Knowledge Assistants produce full MLflow traces, including retrieval spans, the built-in judges can inspect both the retrieved chunks and the final response.
The LLM judges call an LLM judge through Databricks Model Serving. We used databricks-claude-opus-4-6:
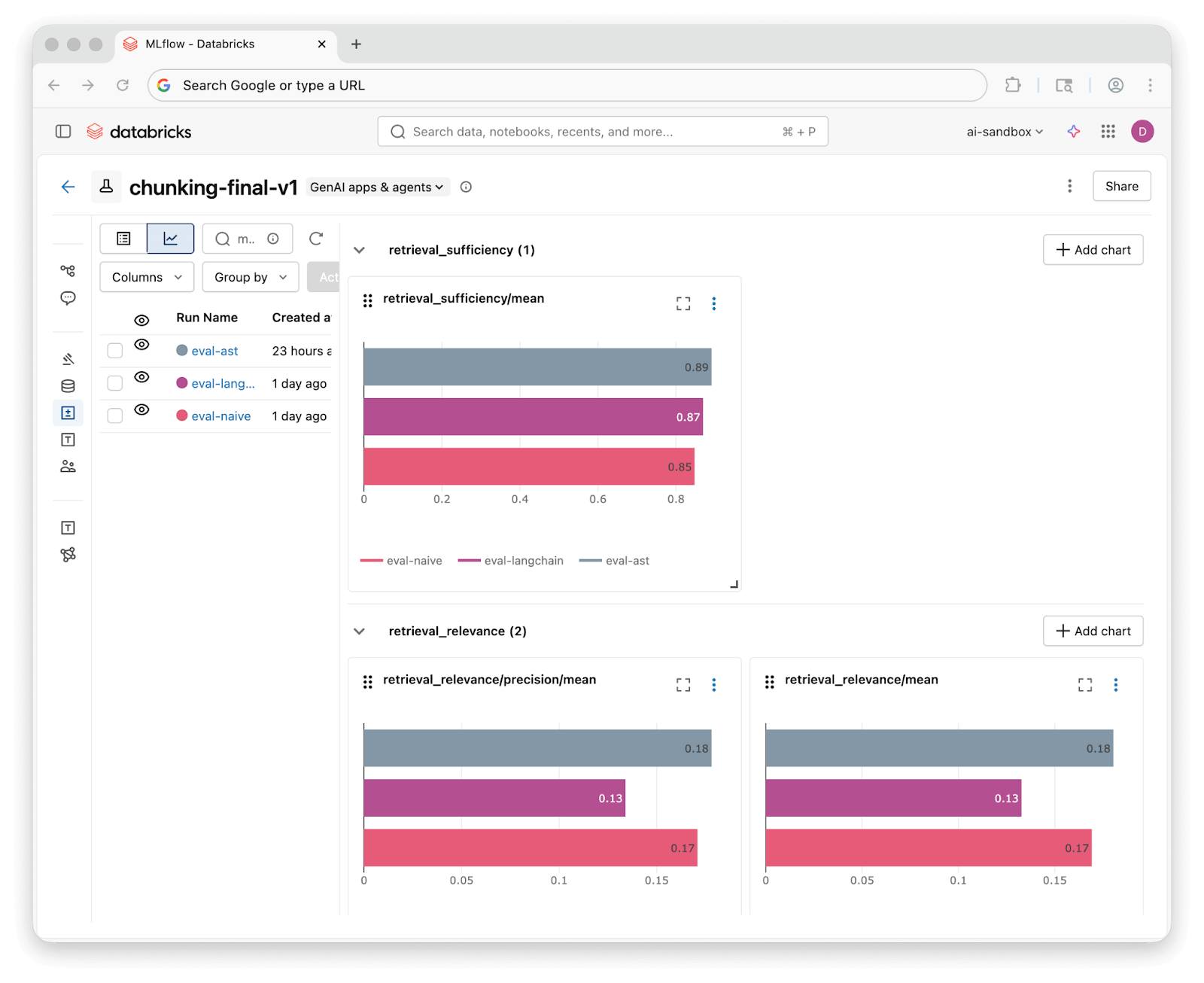
Once evaluation runs complete, MLflow’s experiment UI lets you compare results across all three strategies side by side:
Results and Lessons Learned
We ran all 46 questions through each Knowledge Assistant and scored the results with our three judges. Here’s what we found:
| Judge | Naive | Language-Aware Splitter | AST |
|---|---|---|---|
| Retrieval Sufficiency | 85% | 87% | 89% |
| Retrieval Groundedness | 76% | 72% | 76% |
| Answer Correctness (custom) | 59% fully correct (37% partial) | 61% fully correct (37% partial) | 70% fully correct (28% partial) |
All three strategies achieve 85%+ retrieval sufficiency, meaning Knowledge Assistant’s retrieval techniques find relevant context regardless of how the code was chunked. The differences at the retrieval level are modest.
The custom correctness results tell the more interesting story. AST-based chunking produces a fully correct answer 70% of the time, compared to 59% for Naive and 61% for Language-Aware. All three strategies produce at least a partially correct answer in almost all cases. Better chunks help the knowledge assistant answer questions more completely.
The advantage is concentrated in specific question types. AST-based chunking excelled on disambiguation questions, where structurally similar code exists across modules, due to the prepended metadata (file path, class, function name) providing necessary context. All three strategies were comparable for value lookups and complete definition retrieval.
MLflow traces make it easy to dig into individual questions and see exactly which chunks were retrieved and where answers diverged:
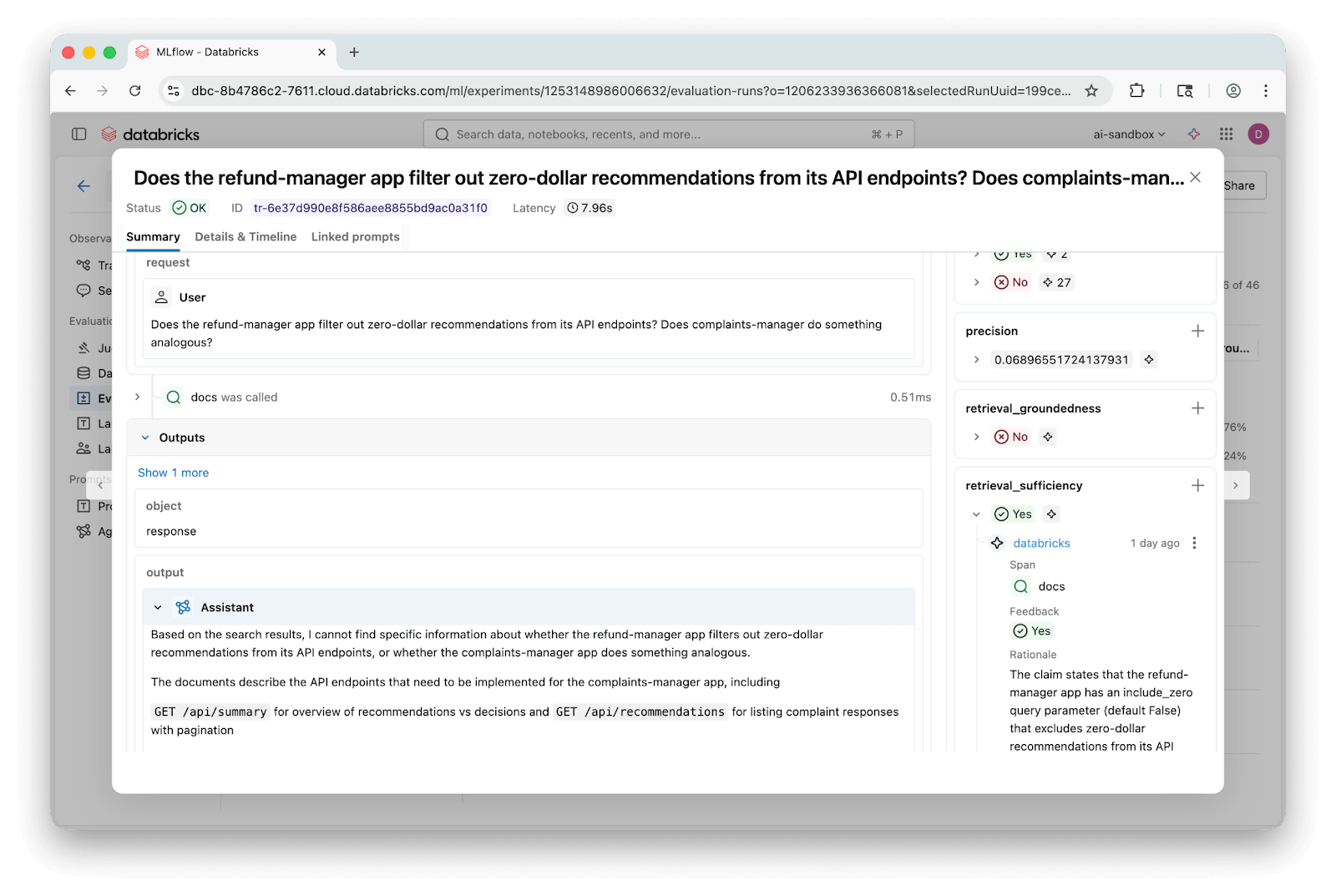
This investigation did leave some questions unanswered: were the improvements we saw using AST-based chunking mostly a consequence of the larger average chunk sizes? How dependent were the results on the choice of model powering the LLM judges? Did our evaluation questions miss major categories real users would ask about?
Lessons Learned
Databricks Knowledge Assistant is highly capable out of the box. Retrieval sufficiency was high across all three strategies, and nearly every question got at least a partially correct answer.
Data prep still matters. AST-based chunking improved groundedness and correctness in this evaluation, particularly for questions that involved disambiguating similar code. Even marginal improvements in retrieval and answer quality compound across a team of developers asking dozens of questions a day.
Custom LLM judges help measure what we really care about. MLflow’s make_judge() API makes it easy to build use case-specific LLM judges. Our custom answer_correctness judge was able to give a more nuanced view on correctness than a simple pass/fail correctness judge.
MLflow traces simplify the evaluation loop. You can investigate individual questions to see exactly which chunks were retrieved and where the answer went wrong. Because traces persist, you can re-score with different judges without re-querying the endpoint.
References
Try It Yourself
You can follow along with this demo in the Casper’s Kitchens repo. Whether you’re evaluating chunking strategies for your own codebase or exploring other RAG improvements, this evaluation framework gives you a reproducible way to compare approaches.
- Create an evaluation dataset with questions and expected answers.
- Implement chunking strategies (or use ours as starting points).
- Set up MLflow LLM judges—start with the built-in options and add custom ones as you find gaps.
- Run evaluations with fresh indexes for each strategy.