
{kind=link}
Introduction
Laying out knowledge is likely one of the oldest issues in computing.
For over 15 years, for the reason that creation of Hadoop and Hive, partitioning has been the usual technique to bodily manage knowledge for processing and evaluation. Nevertheless, at the moment’s Lakehouses serve brokers, real-time pipelines, and question patterns that shift quicker than any human can re-partition for.
Liquid Clustering is the trendy commonplace and prospects are working it at each scale, together with dozens with petabyte scale tables in manufacturing. On this weblog, we’ll cowl why Liquid Clustering wins within the Lakehouse. Alongside the best way, we’ll debunk 8 frequent knowledge format myths, stroll by means of 3 success tales of groups changing partitioned tables to Liquid Clustering, preview what’s coming subsequent, and present learn how to get began.
Why Liquid Clustering wins within the trendy lakehouse
Hive-style partitioning forces customers to commit, at table-creation time, to a bodily group of knowledge that manifests within the file construction. Decide a column with too excessive cardinality and also you get billions of tiny recordsdata. Decide the fallacious column and queries could get slower, not quicker. Both manner, you’re caught rewriting the desk. It’s frequent to get fallacious: in our evaluation, Hive-style partitioning results in over-partitioning and small-file issues in additional than 75% of circumstances.
Liquid treats clustering keys as enter that the engine makes use of to information optimum file group. Keys could be modified at any time, or intelligently chosen by means of Computerized Liquid Clustering. Cardinality isn’t a constraint, and the format can evolve over time with out pointless rewrites.
The advantages of Liquid Clustering all derive from the above precept: higher skew dealing with, row-level concurrency, no small-file issues, multi-dimensional clustering, and decrease write amplification.
In 2026, the format ought to be an implementation element of the desk, with each engine that reads or writes benefitting from it. That is more and more vital as brokers enter the Lakehouse, producing and consuming extra knowledge than ever. People and brokers want forgiving interfaces, freed from the potential side-effects of Hive-style partitioning.
Debunking 8 frequent knowledge format myths
Liquid Clustering grew to become Usually Accessible in 2024. Since then, we’ve iterated on it continuous with prospects working it at scale. In that point, some frequent myths about Liquid Clustering and partitioning have persevered, and at the moment we wish to debunk them.
Fable #1: Partitioning is quicker as a result of it could possibly prune directories as a substitute of recordsdata
The parable goes: With partitioning, Spark or different engines can prune complete directories with out opening any recordsdata within them.
Actuality: Listing-pruning doesn’t exist on trendy open desk codecs like Delta and Iceberg. Delta, for instance, makes use of a transaction log to trace each knowledge file together with per-column statistics, and pruning occurs towards these statistics, not the listing construction. The engine by no means lists directories to plan a question. It reads the transaction log, evaluates filters towards statistics, and skips recordsdata that don’t match. Liquid Clustering makes use of the identical mechanism. Whether or not your knowledge lives in `date=x/hour=y/` or a flat listing of clustered recordsdata, the engine prunes at file granularity. There isn’t any directory-level shortcut to lose.
Fable #2: Partitioning is best when filtering on a low-cardinality column
The parable goes: For a column with a small variety of distinct values, partitioning offers you excellent knowledge separation and good file sizes.
Actuality: Liquid Clustering mechanically detects when to use low-cardinality optimizations. For instance, should you cluster by (date, user_id), and date has low cardinality, the system goals for every file to include rows from solely a single date. Larger-cardinality columns, like user_id, are then mechanically used for finer-grained sorting inside every date’s recordsdata, with out having to depend on different sorting strategies like Z-Ordering.
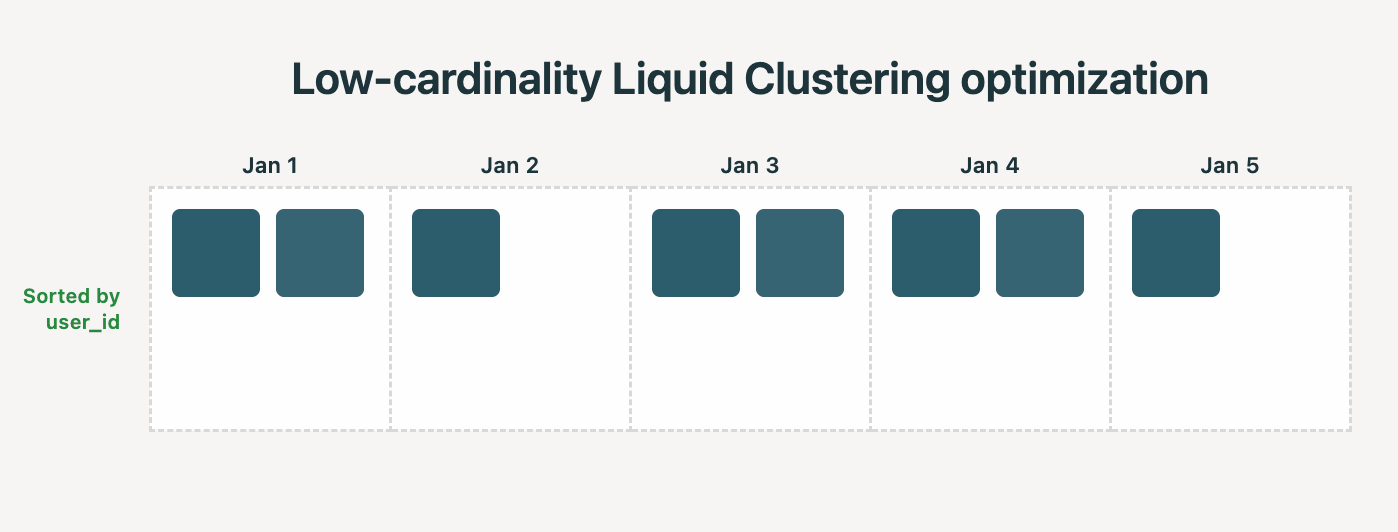
We noticed the next enhancements whereas benchmarking this Liquid optimization on a real-world knowledge warehousing benchmark: 35% decrease time for clustering and 22% quicker question occasions.
Moreover, Liquid Clustering is designed to be higher than partitioning when clustering on a high-cardinality column, because it all the time tries to create recordsdata of an excellent dimension.
Fable #3: Liquid Clustering doesn’t assist metadata-only operations
The parable goes: Metadata-only operations are uniquely supported by partitioning. A DELETE aligned with partition boundaries solely updates the desk’s metadata, and aggregates on partition columns could be computed with out scanning recordsdata. Liquid Clustering can’t do the identical.
Actuality: Liquid Clustering additionally helps metadata-only operations together with DELETEs, COUNT, DISTINCT, and GROUP BY queries. The engine makes use of the identical per-file min/max stats it makes use of for knowledge skipping to find out when a question’s reply could be computed from metadata alone. In our benchmarks, metadata-only DELETEs on Liquid Clustered tables ran ~90% quicker than full-rewrite DELETEs. Different metadata-only mixture queries noticed as much as 27x speedups.
Fable #4: Liquid Clustering doesn’t work properly at petabyte scale
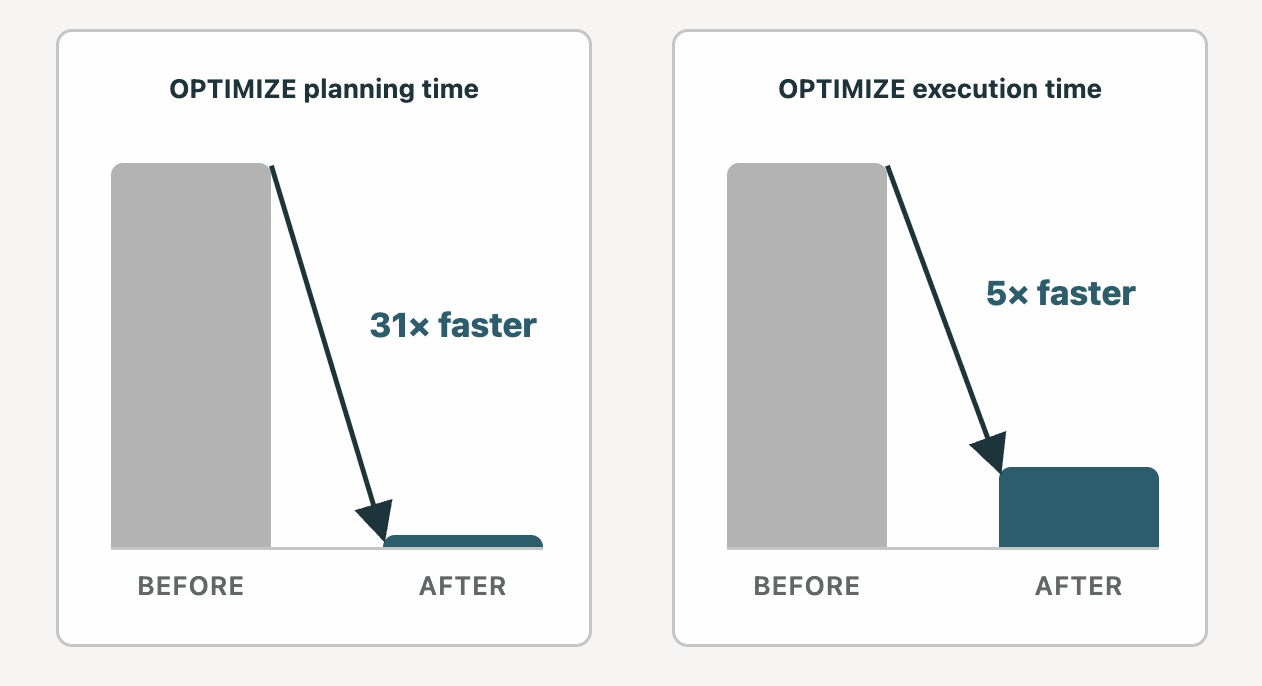
The parable goes: OPTIMIZE on a PB-size desk can run for hours, and the price of upkeep is just too excessive.
Actuality: We’ve made a variety of vital enhancements to OPTIMIZE, and dozens of shoppers now have PB-scale Liquid Clustered tables in manufacturing. Two years in the past, planning, the primary section of OPTIMIZE, may take as much as 12 hours on a ten PB Liquid desk in some circumstances. We’ve spent the time since lowering planning time right down to 23 minutes. Execution, the second section of OPTIMIZE, acquired 5x quicker on a Medium DBSQL cluster.
Fable #5: Liquid Clustering solely advantages a subset of readers
The parable goes: Liquid Clustering is barely useful for Databricks readers to UC managed Delta tables.
Actuality: Liquid Clustering is a write-side optimization. It’s how the engine organizes recordsdata for environment friendly knowledge skipping. The output is commonplace Parquet recordsdata with min/max stats, written into open desk codecs like Delta/Iceberg. Any suitable reader (e.g. open-source Apache Spark, DuckDB, and so on.) can use these stats to skip recordsdata. Liquid Clustering is accessible on each exterior / managed and Delta / Iceberg tables, and the profit is relevant whatever the reader.
Fable #6: Partitioning is critical for concurrent ETL
The parable goes: Concurrent ETL wants write boundaries. With out partitioning, two writers updating the identical desk danger colliding, and Delta/Iceberg concurrency management forces certainly one of them to retry or fail. Partition and provides every author its personal slice of the desk, so two pipelines by no means contact the identical recordsdata.
Actuality: Working at partition granularity was a workaround for an older concurrency mannequin. In contrast to partitioning which solely has file-level concurrency, Liquid gives row-level concurrency. Two writers updating completely different rows not battle, even when these rows reside in the identical file. This removes one of many essential causes groups partitioned tables: sustaining write boundaries to keep away from serialization. With Liquid Clustering, ETL can simply function concurrently towards the identical desk.
Fable #7: Z-Ordering makes up for partitioning’s shortcomings
The parable goes: Partitioning handles the partition column’s filters, and Z-Ordering handles the remaining. By working OPTIMIZE ZORDER BY, the engine kinds knowledge for optimum skipping on filters that don’t align with the partition scheme.
Actuality: Z-Ordering doesn’t save partitioning. In actual fact, it has its personal structural issues.
- The primary is poor clustering high quality. Z-Order doesn’t keep a real ordering throughout the desk. Values for a similar column can get unfold throughout many recordsdata, so per-file min/max ranges are wider and queries skip fewer recordsdata than they’d with Liquid.
- The second is pointless rewrites. Z-Order must be rerun periodically as new knowledge lands, and every rerun rewrites giant quantities of outdated, probably already-clustered knowledge to revive clustering high quality. With steady ingestion, the price of preserving knowledge well-clustered with Z-Order grows together with the desk.
Liquid clusters incrementally, together with at write time, so the format stays optimum with out pointless rewrites.
Fable #8: Partitioning is critical for selective knowledge overwrites
The parable goes: With the ability to selectively overwrite knowledge is barely obtainable by means of Dynamic Partition Overwrites.
Actuality: Selective overwrites work on Liquid tables natively. Databricks helps REPLACE USING and REPLACE ON, two SQL syntaxes for selectively overwriting knowledge on any knowledge format: Liquid Clustered, partitioned, or plain unclustered tables. In contrast to Dynamic Partition Overwrite which requires a Spark config, REPLACE USING and REPLACE ON can be utilized on any compute: basic clusters, SQL warehouses, and Serverless. The operation is atomic and matches on any column you select.
Success tales: migrating from partitioning to Liquid Clustering
7.7x question speedup on Arctic Wolf’s 3.8 PB safety telemetry desk
Arctic Wolf runs a 3.8+ PB safety telemetry desk ingesting 1+ trillion occasions per day, the place risk hunters rely on contemporary knowledge to detect energetic assaults.
After migrating from partitioning to Liquid Clustering on Unity Catalog managed tables with Predictive Optimization, Arctic Wolf noticed:
- 90-day queries drop from 51 seconds to six.6 seconds
- File depend dropped from 4M to 2M
- Knowledge freshness improved from hours to minutes
Learn and write enhancements on important CDC tables for Bolt
Bolt just lately tried Liquid Conversion (at the moment in Personal Preview), which converts partitioned tables to Liquid in-place utilizing ALTER TABLE .. REPLACE PARTITIONED BY WITH CLUSTER BY. They noticed the next learn and write advantages on a TB-scale CDC desk after changing to Liquid Clustering:
- Write throughput (rows/sec) elevated by 138%
- Learn occasions have been diminished by as much as 63%, with a median of 21% discount throughout 9 consultant queries
Liquid Clustering dramatically diminished the work that every write was doing, growing our throughput considerably on our most crucial CDC desk. Reads additionally improved throughout the board. The most effective factor was: we ran the conversion from partitioning alongside reside ingestion with zero downtime. With this, Liquid Clustering supplied us precisely the sort of efficiency and reliability we wanted at platform scale. — Marcin, a senior platform engineer at Bolt
5.9x speedup in question time on a petabyte-scale inner workload
We run a 1.1 PB desk internally that is queried hundreds of occasions a day, largely by engineers working manufacturing investigations and observability dashboards. Initially it was partitioned by date and hour, assuming time-range scans would dominate. Nevertheless, that assumption turned out to be incomplete. Whereas time-range scans have been frequent, the desk was additionally regularly queried by supply and id, forcing the engine to scan each file within the related date and hour partitions to discover a handful of rows.
Including supply and id as partitions wasn’t viable, as a result of there have been too many distinct values. This might have created billions of tiny recordsdata. Liquid Clustering eliminated the trade-off, permitting clustering on time and the extra identifier columns concurrently, whereas sustaining good file sizes.
| Structure | |
|---|---|
| Earlier than | Partitioned by date, hour |
| After | Clustered by date, hour, supply, id |
Benchmarks confirmed huge enhancements throughout 16 consultant manufacturing queries:
| Metric | Earlier than (partitioned) | After (Liquid) | Enhancements |
|---|---|---|---|
| Wall Clock Time | 406s | 70s | 5.9x speedup |
| Bytes Learn | 3.5 TB | 0.48 TB | 86% fewer bytes learn |
The desk itself acquired smaller too. Whole dimension dropped from 1.1 PB to 0.8 PB, a 27% discount with no change within the underlying knowledge. Higher-clustered recordsdata compress extra effectively, and the small-file tax that comes with over-partitioning disappears.
What’s coming subsequent for Liquid Clustering
Optimizing Liquid-to-Liquid joins: as much as 51% quicker with 87% much less shuffle
Immediately, becoming a member of Liquid tables on their clustering columns can require a full knowledge shuffle, even when the info is already organized by these columns. Co-clustered joins (now in Personal Preview) take away that shuffle mechanically. On a real-world knowledge warehousing benchmark, a Liquid-to-Liquid be part of ran ~51% quicker (28 minutes → 14 minutes) and shuffled 87% much less knowledge (1.2 TiB → 150 GiB) than the identical question with out the optimization.
Straightforward Liquid Conversion of partitioned tables
Earlier than, changing a partitioned desk to Liquid Clustering required a full desk rewrite and downstream breaking modifications with REPLACE TABLE or a cutover with twin writes and deliberate downtime. We’re introducing a brand new command (now in Personal Preview) that makes this conversion simpler, minimizing each downtime and rewrites.
Getting began with Liquid Clustering
Create a desk with Liquid Clustering:
Or, should you’re utilizing UC managed tables with Predictive Optimization, use Computerized Liquid Clustering to intelligently choose clustering keys primarily based in your workload and question patterns:
Liquid Clustering is the format for the trendy Lakehouse. Attempt it in your subsequent desk, or attain out to your account group at the moment to strive the Personal Previews for partitioned-to-Liquid Conversion and Co-Clustered joins!
Don’t neglect to catch us at DAIS!