
{kind=link}
Processing a whole lot of 1000’s of occasions per second whereas sustaining sub-second latency is a problem many organizations face when constructing real-time data-driven functions. When filter coverage adjustments propagate in as much as quarter-hour, dynamic occasion routing turns into impractical, forcing groups to over-consume occasions and discard over 90% after pricey per-event lookups. Smartsheet, a piece administration resolution serving tens of millions of customers and processing a whole lot of 1000’s of occasions per second to energy options like reside collaboration, workflows, and real-time notifications, confronted precisely this downside.
On this publish, you learn the way Smartsheet constructed a Actual-time Dynamic Filtering (RDF) system on Amazon Managed Service for Apache Flink, slicing messaging prices by over $40,000 per 30 days and enhancing reside collaboration latency by 1.8x.
The problem: Static filter insurance policies in a dynamic world
The Smartsheet event-driven structure publishes a whole lot of 1000’s of occasions per second to an Amazon Easy Notification Service (Amazon SNS) subject. Inner groups subscribe to this subject, sometimes by creating an Amazon Easy Queue Service (Amazon SQS) queue with an related SNS filter coverage outlined by way of infrastructure as code (IaC). These filter insurance policies are sometimes static and specify the forms of occasions a client desires to obtain, reminiscent of “sheet row created,” “sheet row up to date,” or “sheet row deleted.”
Though SNS helps programmatic adjustments to filter insurance policies, the SNS documentation notes that adjustments can take as much as quarter-hour to take impact. This eventual consistency window created a big downside for Smartsheet reside collaboration characteristic.
Reside collaboration requires understanding, in actual time, which sheets have lively collaborators. When a consumer opens a sheet, the system wants to instantly begin receiving occasions for that sheet. Once they shut it, the system ought to cease. With a 15-minute propagation delay on filter coverage adjustments, dynamic per-sheet filtering by way of SNS was impractical.
The workaround was brute power: subscribe to all occasions (a whole lot of 1000’s per second), pull them into an SQS queue, and use compute to verify every occasion towards Amazon DynamoDB to find out whether or not the sheet had lively collaborators. Over 90% of occasions had been discarded after this lookup.
Determine 1: Earlier than RDF — all occasions movement by way of SNS to SQS, with per-event DynamoDB lookups to filter. Over 90% of occasions are discarded after processing.
- Each occasion revealed to the SNS subject is delivered to the SQS queue, no matter whether or not any client wants it.
- The buyer AWS Lambda reads each message from the SQS queue and should consider every one individually.
- For every occasion, the buyer queries DynamoDB to verify whether or not the sheet has lively collaborators. This per-event lookup provides latency and DynamoDB learn prices on the new path.
- After the DynamoDB lookup, over 90% of occasions are discovered to haven’t any lively collaborators and are discarded.
This strategy had three compounding value and efficiency issues:
- SNS-to-SQS knowledge switch prices: roughly $10,000 per 30 days to ship all occasions to the queue
- SQS prices: roughly $30,000 per 30 days to obtain, course of, and delete the total occasion quantity
- DynamoDB prices and latency: per-event lookups to verify collaborator standing added load to DynamoDB and elevated end-to-end knowledge supply latency
The answer: Actual-time Dynamic Filtering with Apache Flink
To resolve this, Smartsheet constructed a system referred to as Actual-time Dynamic Filtering (RDF) on Amazon Managed Service for Apache Flink. The core perception was to maneuver the filtering logic into the stream processing layer itself, utilizing Flink’s KeyedCoProcessFunction, a characteristic that joins and processes a number of streams by a shared key, to keep up dynamic filter insurance policies in Flink state (RocksDB).
The way it works
The RDF Flink utility reads from two streams:
- Filter coverage stream, sourced from Amazon DynamoDB Streams. When a workforce calls the RDF consumer to alter their filter coverage (for instance, “begin receiving occasions for sheet X”), the change is written to a DynamoDB desk and propagated by way of DynamoDB Streams to the Flink utility.
- Knowledge stream, the stream of sheet occasions (creates, updates, deletes) that had been beforehand delivered by way of SNS.
One problem remained: some shoppers want each occasion, no matter sheet. When a client subscribes to all occasions, the system wants each parallel Flink process to find out about it. The workforce solved this utilizing Flink’s broadcast state, which replicates a small set of “subscribe to all the pieces” insurance policies throughout all duties. As a result of solely a handful of shoppers use this mode, the reminiscence overhead stays negligible.
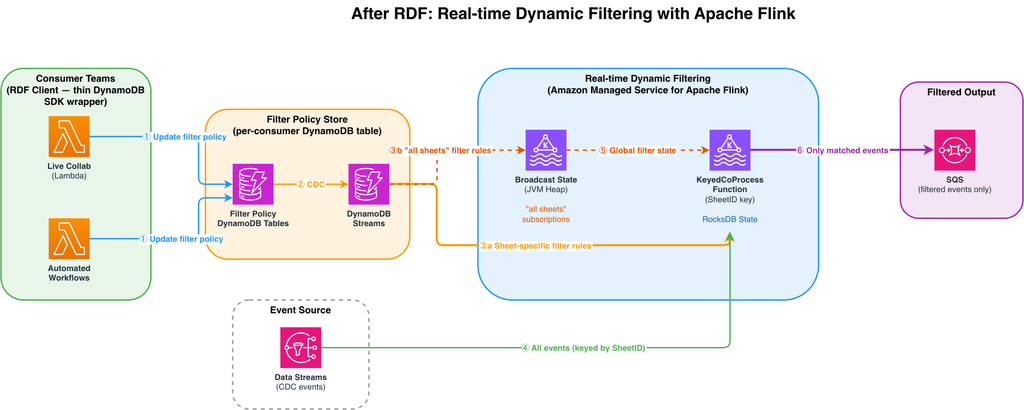
Determine 2: After RDF — client groups replace filter insurance policies by way of consumer libraries. DynamoDB Streams propagates adjustments to the Flink utility, which filters the information stream in actual time utilizing keyed state (RocksDB) for particular sheet subscriptions and broadcast state for “all sheets” subscriptions.
- When a client workforce desires to begin or cease receiving occasions for a selected sheet, it calls the RDF consumer, a skinny wrapper over the DynamoDB SDK. The filter coverage change is written to that client’s devoted DynamoDB desk. Every client has its personal desk, offering remoted permissions and stopping noisy neighbor points.
- DynamoDB Streams captures each filter coverage change as a change knowledge seize (CDC) report and streams it to the Flink utility in actual time.
- Filter coverage data
- Filter coverage data for particular sheets are routed to the
KeyedCoProcessFunction, keyed bySheetID. This makes certain that filter state and occasion knowledge for a similar sheet are co-located in the identical Flink parallel process. State is saved within the RocksDB backend, which makes use of reminiscence when obtainable and spills to disk when obligatory, so the system to scale with out JVM heap constraints. - Filter coverage data the place a client has referred to as
listenToAllEvents()are broadcast to all parallel Flink duties by way of Flink’s broadcast state. As a result of broadcast state lives in JVM heap, it’s used completely for these “all sheets” data (of which there are only a few), maintaining the heap footprint small.
- Filter coverage data for particular sheets are routed to the
- The total stream of CDC occasions flows into the
KeyedCoProcessFunction, partitioned by SheetID. Every parallel process receives solely the occasions for the sheets it’s answerable for and applies the corresponding filter state to resolve whether or not to ahead or drop every occasion. - The published state (containing “all sheets” subscriptions) is made obtainable to all parallel cases of the
KeyedCoProcessFunction, so that customers subscribed to all occasions are by no means filtered out no matter which process processes their occasions. - Solely occasions that match an lively filter coverage are forwarded to the buyer’s SQS queue. The outcome: sub-second filter coverage propagation (p95 ≤1s), elimination of per-event DynamoDB lookups, and over $40,000/month in value financial savings.
Critically, as a result of the filter coverage state is endured in Flink’s RocksDB state backend, the appliance doesn’t have to carry out a DynamoDB lookup for each occasion. Inside 1 second of a filter coverage change, the Flink utility reads the change from the DynamoDB Streams supply, updates its inside state, and begins filtering the information stream accordingly.
Outcomes
The affect of RDF was fast and measurable throughout a number of dimensions:
Value discount
| Value class | Earlier than RDF | After RDF | Month-to-month financial savings |
|---|---|---|---|
| SNS → SQS Knowledge Switch | ~$10K/month | Eradicated | ~$10K |
| SQS Occasion Ingestion | ~$30K/month | ~$2K | ~$28K |
| DynamoDB Collaborator Lookups | Important load | Eradicated (state in Flink) | Included in whole |
| AWS Lambda | ~$12K/month | ~$5K/month | ~$7K |
| Whole | ~$45K/month |
Latency enchancment
- 1.8x enchancment in reside collaboration knowledge supply latency. Customers see adjustments from collaborators quicker than earlier than.
- Filter coverage propagation lowered from as much as quarter-hour to a p95 of below 1 second
In case your structure follows the same fan-out sample the place shoppers discard a big share of occasions after per-event lookups, you can obtain comparable value reductions by transferring filtering into the stream processing layer. The financial savings scale together with your occasion quantity and the share of occasions at present discarded.
Key design selections
A number of architectural decisions had been crucial to the success of this resolution:
- Keyed state with selective broadcast: Particular sheet subscriptions are saved in keyed state utilizing the RocksDB state backend. The system scales to numerous filter insurance policies with out JVM heap constraints. Flink’s broadcast state is used just for the small variety of “all sheets” subscriptions, the place each parallel process wants visibility. As a result of broadcast state is saved in JVM heap, limiting its use to those few data retains the heap footprint manageable.
- DynamoDB Streams because the filter coverage supply: Fairly than constructing a customized management aircraft, the workforce used DynamoDB Streams to propagate filter coverage adjustments. DynamoDB Streams gave the workforce sturdiness, ordering ensures, and a local Flink supply connector integration.
- RocksDB state backend: Persisting filter state in RocksDB eradicated the necessity for exterior lookups on the new path, maintaining per-event processing latency low even because the variety of lively filter insurance policies grows.
- Consumer library abstraction: Publishing inside Golang and Java shoppers lowered the adoption barrier. The consumer is a skinny abstraction on high of the DynamoDB SDK. Every client has its personal devoted DynamoDB desk and corresponding filter stream, which supplies two advantages: it permits fine-grained AWS Identification and Entry Administration (AWS IAM) permissions per consumer, and it mitigates the noisy neighbor downside by isolating every client’s filter coverage visitors. Groups don’t want to know Flink internals. They work together with a easy API to handle their subscriptions.
Subsequent steps
The reside collaboration workforce was the primary adopter of RDF, however the structure was designed as a shared platform. Smartsheet is now increasing RDF to further inside groups, together with workflow automation and notification routing, the place comparable fan-out patterns exist. The workforce can also be exploring computerized scaling insurance policies to optimize Flink cluster prices throughout off-peak hours.
Conclusion
Smartsheet Actual-time Dynamic Filtering system demonstrates how Amazon Managed Service for Apache Flink can resolve issues that transcend stream processing. By combining Flink’s broadcast state sample with CoProcessFunction, Smartsheet changed a pricey and latency-bound SNS/SQS fan-out structure with a sub-second dynamic filtering platform. The outcome: over $40,000 per 30 days in financial savings, 1.8x enchancment in reside collaboration latency, and a reusable platform that a number of groups at the moment are adopting.
If you happen to course of high-volume occasion streams and have to dynamically management which occasions attain particular shoppers, this sample will help you scale back prices and latency, whether or not for reside collaboration, workflow automation, notification routing, or multi-tenant occasion supply.
To be taught extra in regards to the providers used on this publish, go to:
Concerning the authors