
{kind=link}
Amazon OpenSearch Service clusters provide a wealth of operational metrics accessible by way of CloudWatch and the Amazon OpenSearch Service console to help efficient efficiency monitoring and alert creation. But, pinpointing resiliency and efficiency challenges inside your cluster can show daunting. The method of figuring out resource-intensive queries or understanding efficiency degradation traits could be time-consuming.
To deal with these challenges, we launched Cluster insights, which presents a unified dashboard delivering curated insights together with actionable mitigation steps. The dashboard shows detailed metrics on the node, index, and shard ranges, coupled with a concise abstract of safety and resiliency greatest practices to uphold peak resiliency and availability.
This weblog will information you thru establishing and utilizing Cluster Insights, together with key options and metrics. By the conclusion, you’ll perceive how you can use Cluster insights to acknowledge and deal with efficiency and resiliency points inside your OpenSearch Service clusters.
Getting Began with Cluster insights
Cluster insights is obtainable at no extra value to OpenSearch Service customers working OpenSearch model 2.17 or later. Accessing Cluster insights requires admin-level permissions in your OpenSearch area. Cluster insights is obtainable solely by way of the OpenSearch UI. OpenSearch UI presents help to a number of knowledge sources, zero downtime upgrades in your dashboard expertise, and curated workspaces for efficient crew collaborations. You first must affiliate a knowledge supply (your clusters) with an OpenSearch UI software. Detailed steps are described within the consumer information. Your OpenSearch UI console expertise will seem like following screenshots.
To entry Cluster insights utilizing the OpenSearch UI software:
- Within the Amazon OpenSearch Service console, navigate to OpenSearch UI (Dashboards) and select the Software URL to entry your OpenSearch UI software.
- OpenSearch UI software, select the settings icon on the left-bottom nook, then select Knowledge administration.
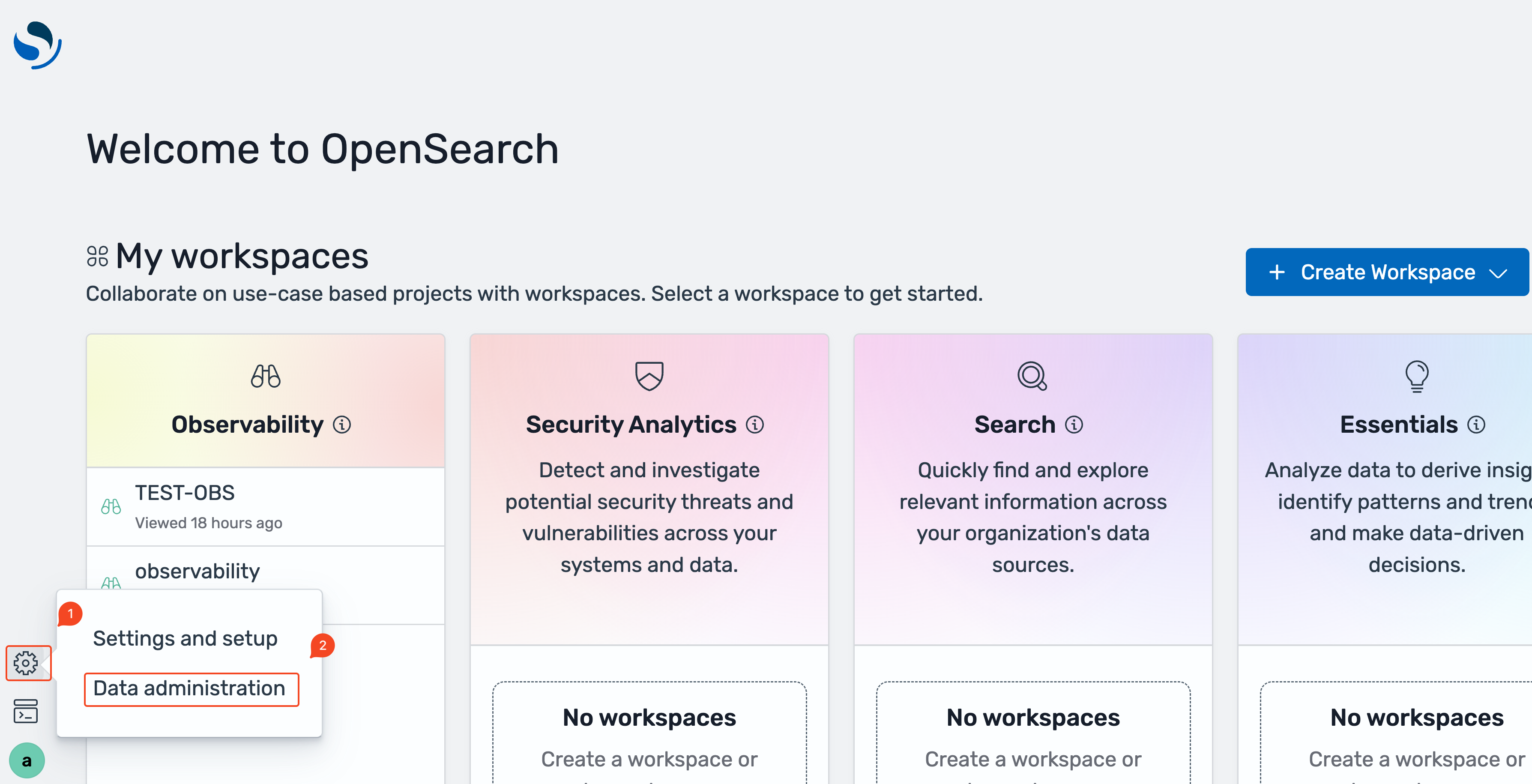
- On the Knowledge administration overview web page, or below Handle knowledge within the left navigation, choose Cluster insights.
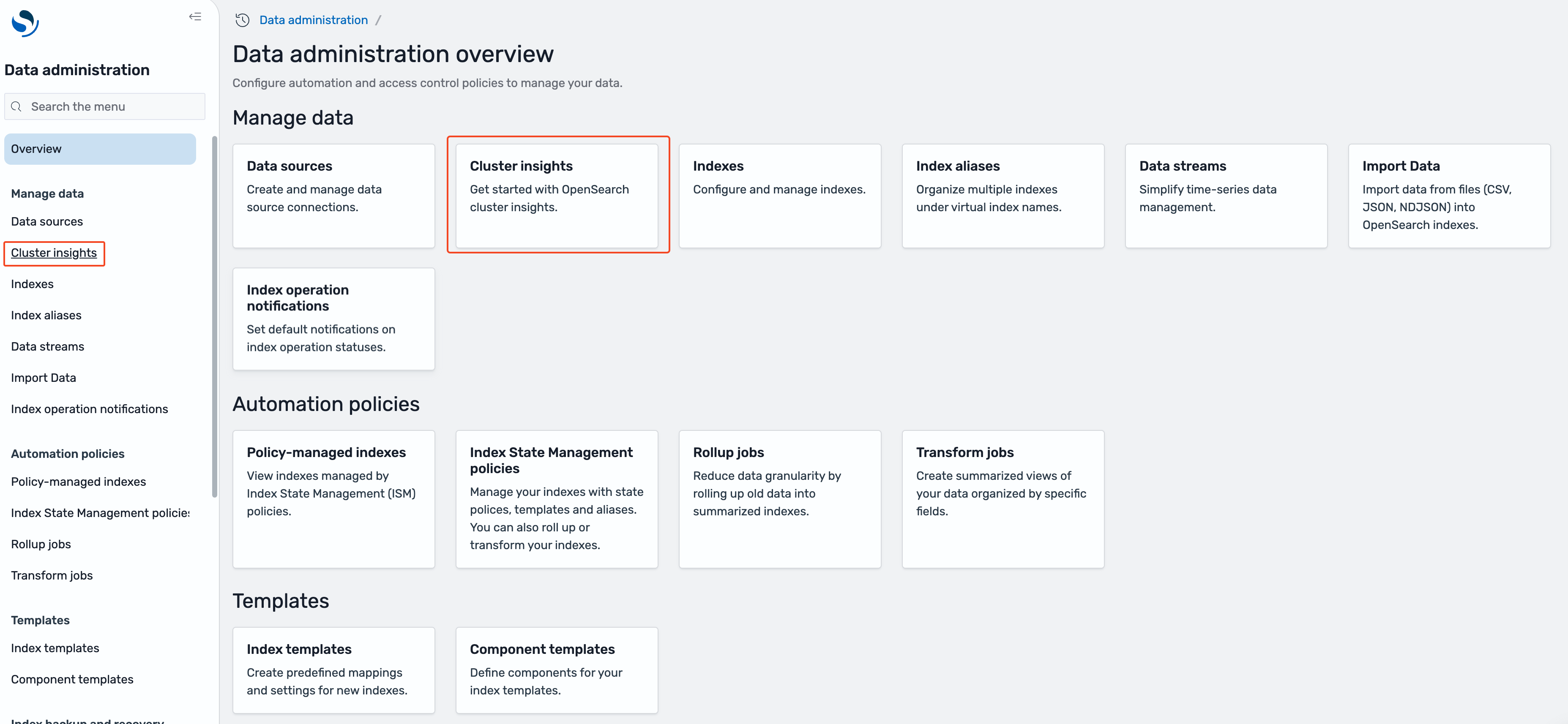
Cluster insights overview
The Cluster insights – Overview acts as a touchdown web page to point out well being and insights for all linked OpenSearch domains. It’s organized into 5 sections:
- Present cluster standing – Shows cluster well being standing (Inexperienced, Yellow, and Pink) in a donut chart.
- Insights pattern – Tracks problem patterns over the previous 30 days, serving to you establish rising issues and monitor decision progress. This pattern evaluation turns into notably beneficial when monitoring the impression of operational modifications or troubleshooting recurring points.
- Present open insights – Reveals the depend and severity breakdown of at present energetic insights throughout your clusters.
- OpenSearch service clusters – Lists all domains with their very important statistics corresponding to well being standing, insights depend, nodes, shards, and energetic queries.
- Prime insights by severity – Prioritizes points that want speedy consideration. Every perception comes with a transparent description and particular suggestions, remodeling advanced monitoring knowledge into actionable duties. This prioritized view helps groups can deal with crucial points first, whether or not they’re addressing shard dimension issues, disk house points, or efficiency bottlenecks.
Collectively, these sections present a complete view of your OpenSearch Service infrastructure so you possibly can assess cluster well being, establish traits, and take motion on crucial points from a single dashboard.
Cluster well being
If you select a selected cluster from the OpenSearch domains on the Cluster insights – Overview web page, you will note cluster-specific particulars together with well being standing, energetic insights, and efficiency metrics. The overview part shows cluster well being together with important metrics together with depend of shards, nodes, indices, and a complete doc dimension. You may also evaluate the configuration greatest practices adopted by area throughout resiliency and safety areas.
The decrease part comprises a desk of actionable insights that presents an in depth view of present points. This desk mirrors the insights from the touchdown web page however focuses particularly on points affecting the chosen cluster. You may observe high-severity points corresponding to low disk house and shard depend issues, in addition to medium-severity considerations which will impression cluster efficiency.
Every perception entry serves as an interactive aspect – deciding on any problem reveals an in-depth evaluation full with root trigger identification and particular remediation steps. The desk consists of necessary metadata corresponding to era timestamps, severity ranges, advice counts, and present standing, so customers can prioritize and deal with points successfully.
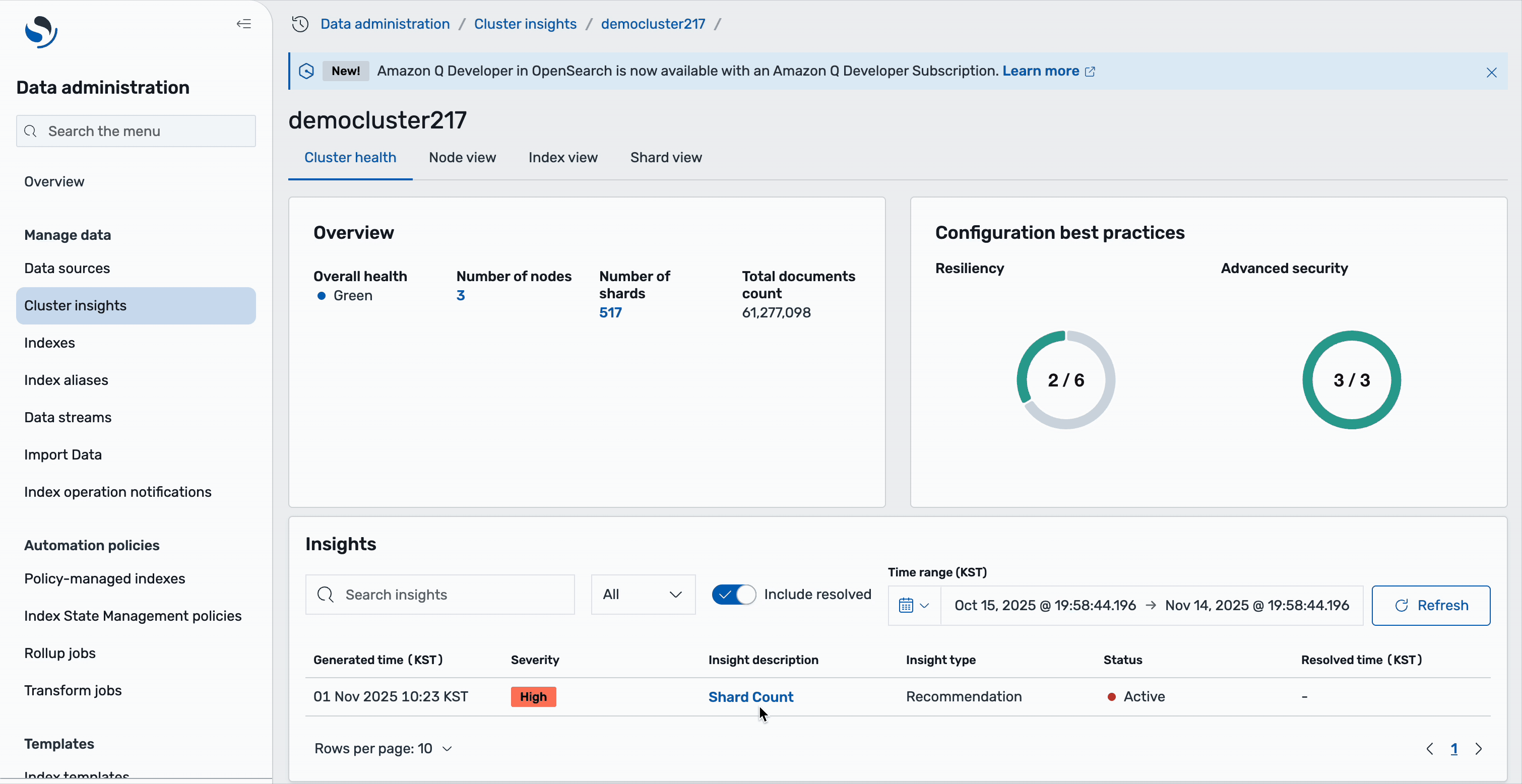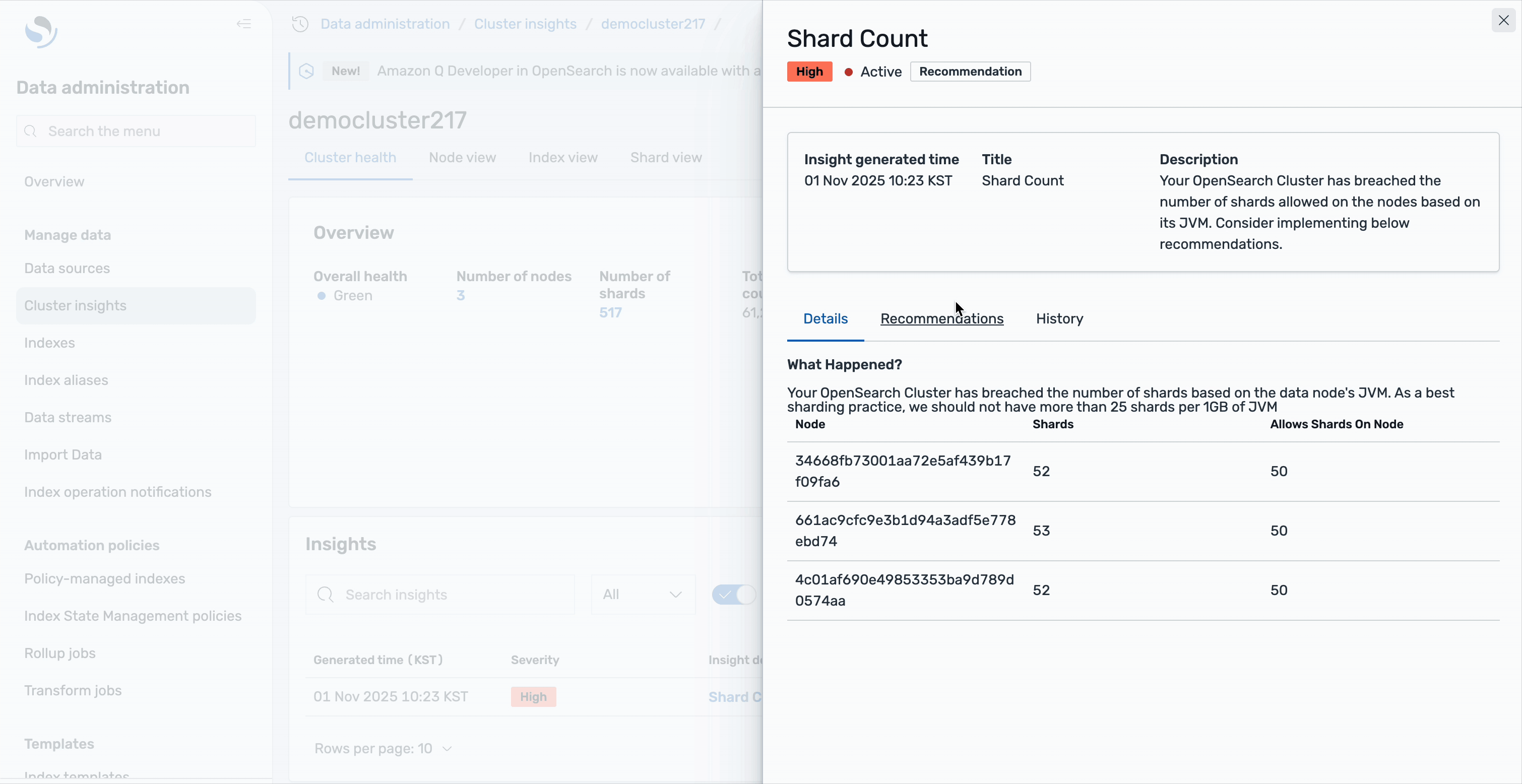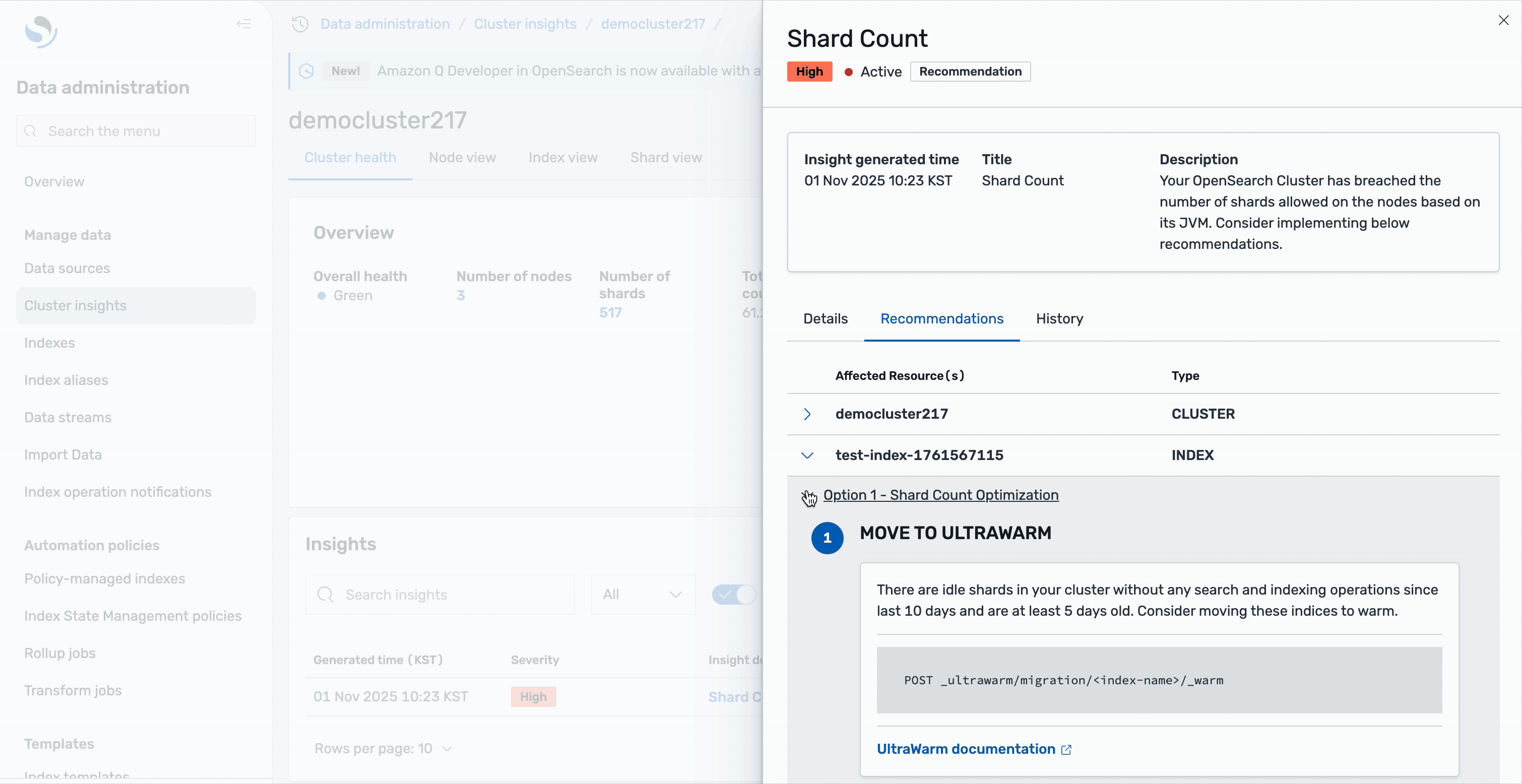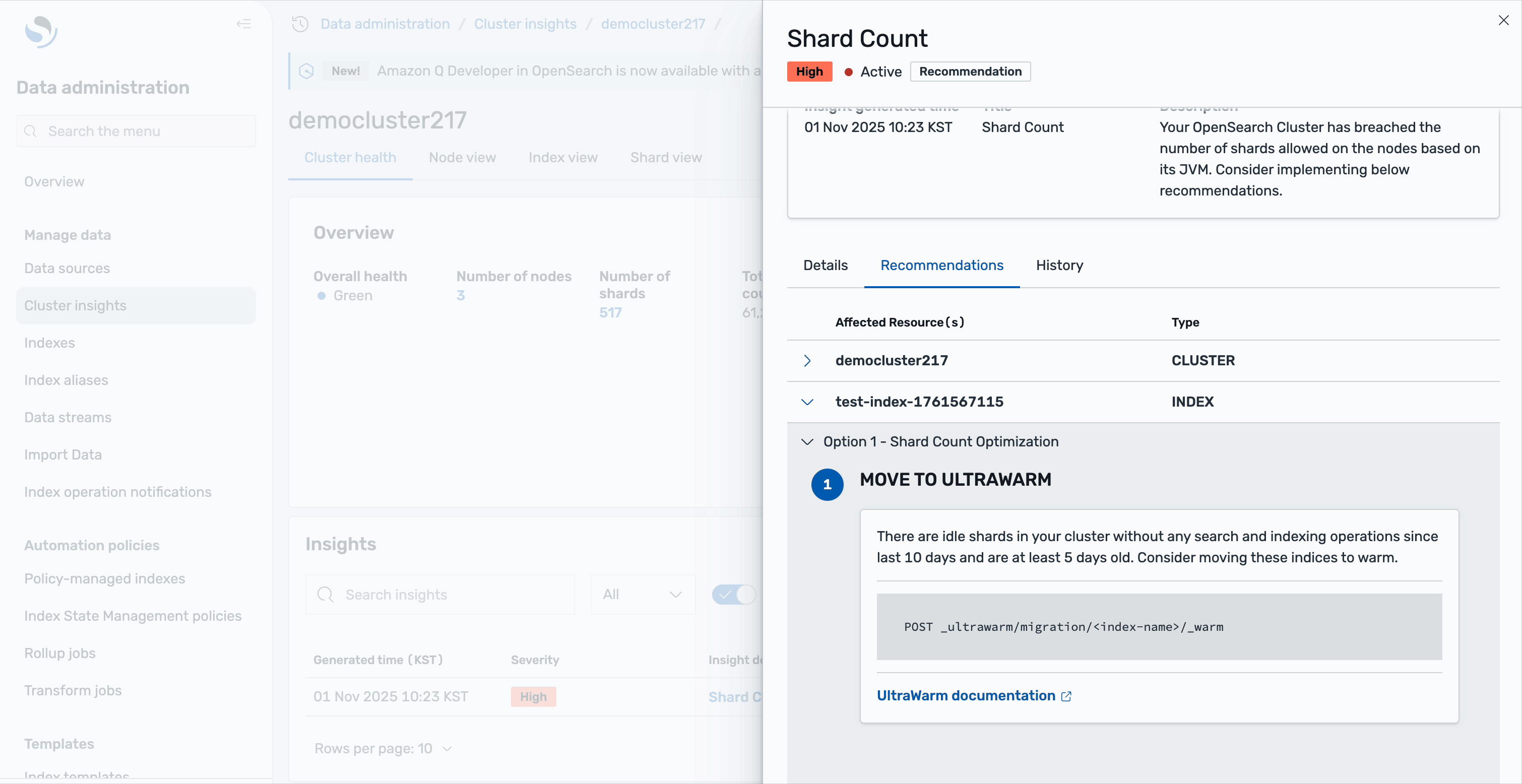
Perception particulars
Each perception presents detailed evaluation and actionable suggestions. Take the Shard Depend perception for example: deciding on it reveals a complete breakdown of the problem. You’ll see that your OpenSearch cluster has breached the variety of shards allowed on the nodes based mostly on its JVM heap dimension, together with an in depth checklist of affected sources.

The detailed view features a useful resource map that exactly identifies every impacted node and index, displaying crucial info corresponding to node IDs, shard counts, and the indices contributing to the problem.
The suggestions are organized into two ranges: cluster-level suggestions deal with general structure enhancements, corresponding to scaling your cluster or adjusting world shard allocation settings. Index-level suggestions present particular actions for particular person indices—for instance, you may see solutions to maneuver idle shards to UltraWarm storage. These are shards with none search or indexing operations for the final 10 days and are no less than 5 days outdated, making them supreme candidates for heat storage to scale back the energetic shard depend. All of this steering is obtainable immediately inside the Cluster insights interface, eliminating the necessity to change between totally different instruments or consoles.
Node, Index, Shard, and Question view
Subsequent to cluster well being, you possibly can evaluate Node, Index, Shard, and Question particulars for a selected cluster. These views current crucial metrics corresponding to useful resource (CPU, reminiscence, disk) utilization, search and index latency.
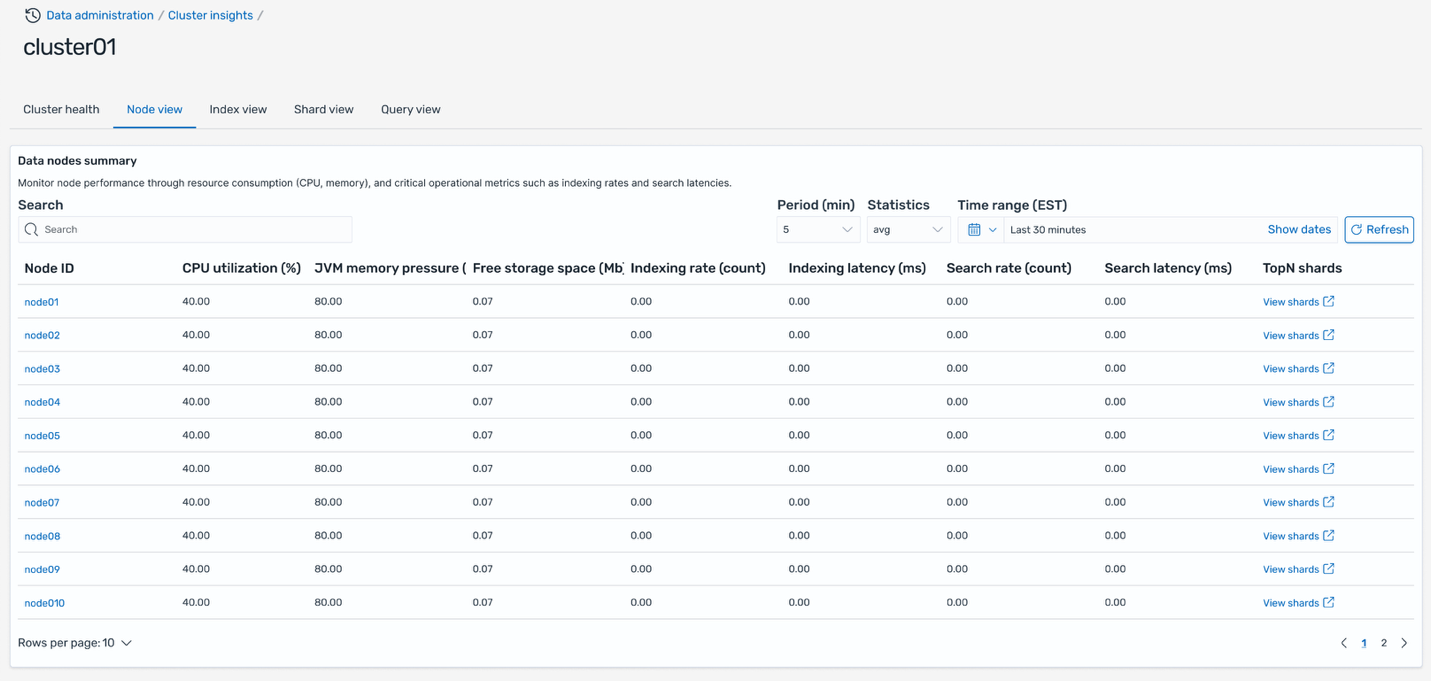
Node view
The Node view tab gives a complete view of particular person node efficiency throughout your cluster. This desk shows crucial metrics for every node together with warmth rating indicating general node well being, useful resource utilization (CPU, reminiscence, disk), search and indexing latency and charges, together with fast hyperlinks to view prime N shards and queries working on every node.
This view helps you establish nodes experiencing excessive useful resource utilization or efficiency degradation. You may drill deeper into every node by clicking on the node ID to view detailed time-based metrics displaying useful resource utilization traits over time. Moreover, you possibly can click on the highest N shards hyperlink to navigate on to the Shard View, robotically filtered to point out solely the shards working on the chosen node, permitting you to pinpoint which particular shards are contributing to efficiency points.
Index view
The Index view tab reveals efficiency metrics aggregated on the index degree. For every index, you possibly can monitor doc depend and storage dimension, search latency and charge, indexing latency and charge, and entry prime N queries affecting the index. This attitude is effective for understanding which indices are driving cluster load and figuring out optimization alternatives on the index configuration degree.

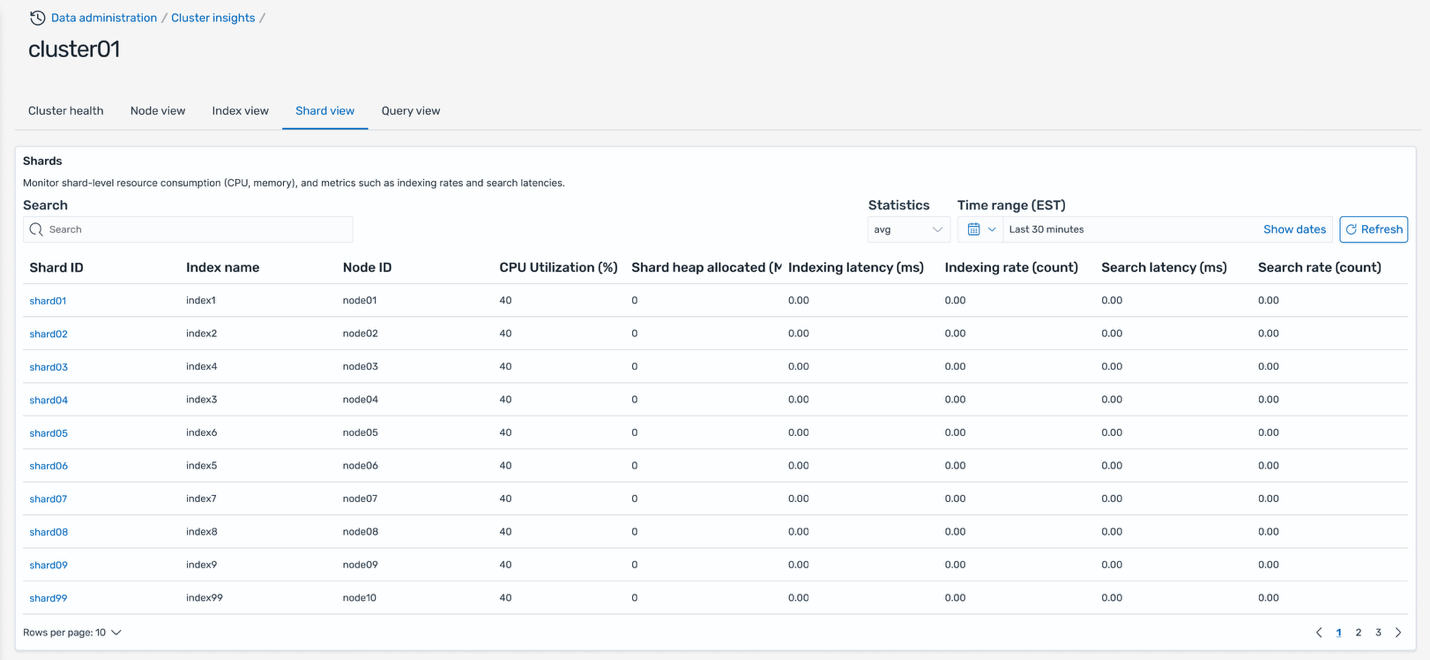
Shard view
The Shard view tab presents essentially the most granular view of cluster efficiency by displaying metrics for particular person shards. Every row reveals shard ID and its assigned node, index affiliation and useful resource stress metrics (CPU, reminiscence), together with search and indexing latency per shard. This detailed view lets you pinpoint particular shards inflicting efficiency points, establish shard placement imbalances, and take focused remediation actions.
Question view
The Question view on the Cluster insights web page solves presents stay dashboards that break down execution stats, CPU and reminiscence utilization, and completion progress for each question. This helps monitor which queries are driving the largest useful resource consumption (the Prime-N queries). With intuitive donut charts and scoreboards displaying distribution by node, index, and consumer, this interface helps operators to rapidly pinpoint efficiency bottlenecks and heavy workloads, supporting focused optimization and assured scaling choices.
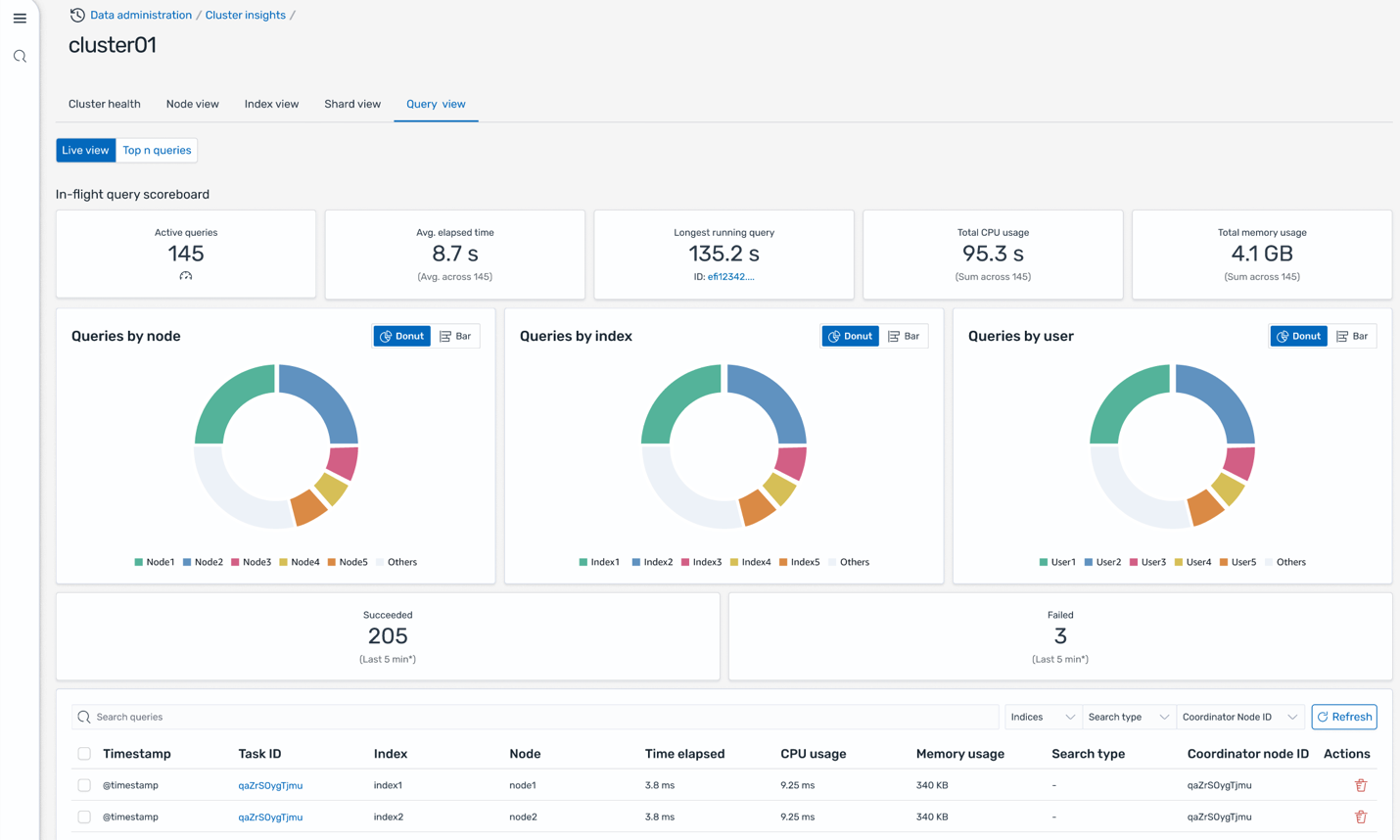
Question insights
Along with Cluster insights, it’s also possible to get Question insights to view the precise queries working and latencies throughout Increase, Question, and Fetch phases that gives beneficial insights for search builders to additional fine-tune their queries.
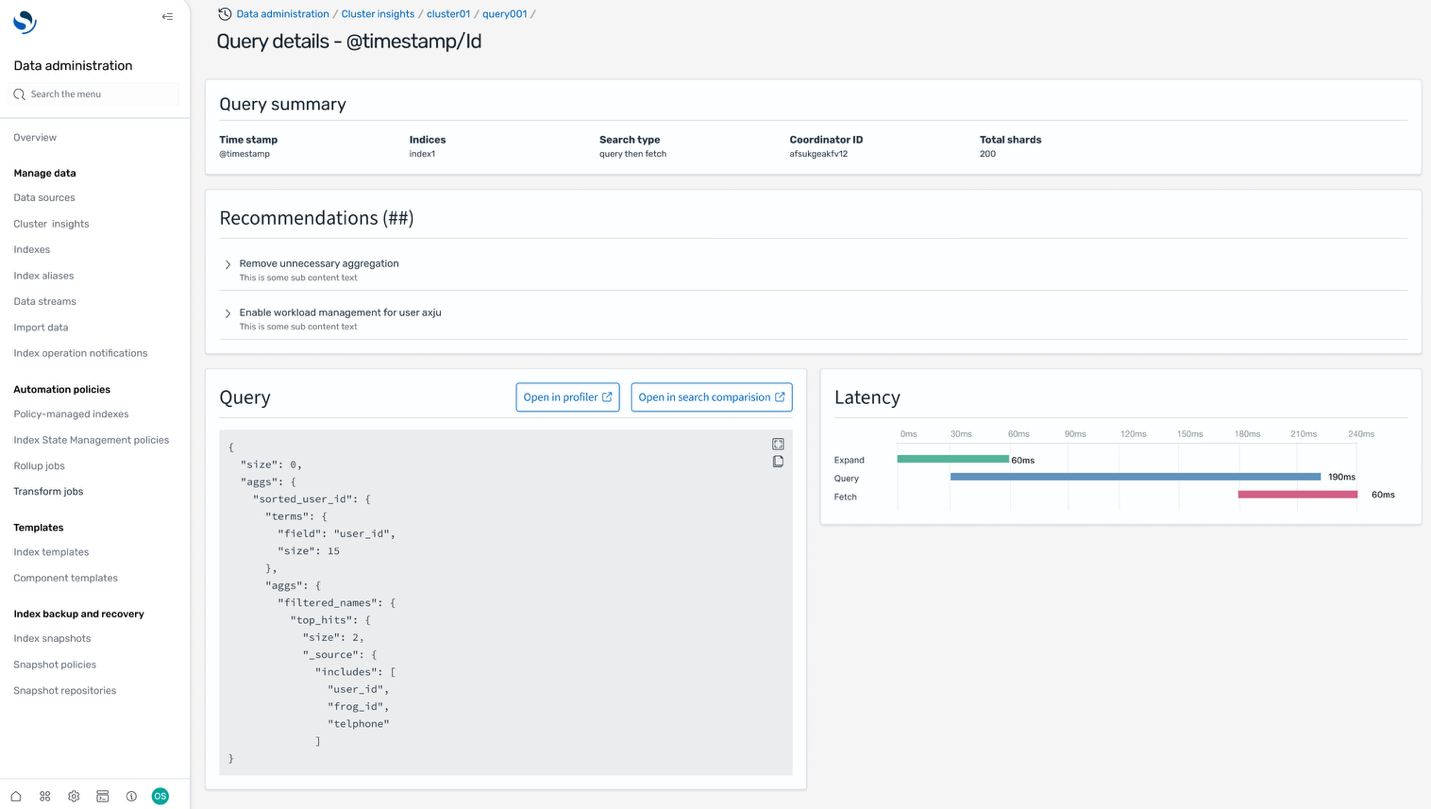
Conclusion
Cluster insights transforms OpenSearch Service cluster administration from reactive troubleshooting to proactive optimization. By offering unified dashboards with warmth rating, and greatest practices throughout stability, resiliency, and safety pillars, it presents visibility into your search infrastructure on the account degree.
The actionable suggestions and step-by-step remediation steering assist customers of all expertise ranges successfully resolve advanced points like shard imbalances and useful resource bottlenecks.
The mixing with Question insights delivers real-time visibility into useful resource consumption patterns in order that groups can establish and optimize performance-critical queries by way of detailed profiling and latency evaluation.
For extra info, see the AWS OpenSearch Service Person Information for extra particulars.
In regards to the authors