
{kind=link}
Databricks operates at a scale the place our inside logs and datasets are always altering—schemas evolve, new columns seem, and knowledge semantics drift. This weblog discusses how we use Databricks at Databricks internally to maintain PII and different delicate knowledge accurately labeled as our platform adjustments.
To do that, we constructed LogSentinel, an LLM-powered knowledge classification system on Databricks that tracks schema evolution, detects labeling drift, and feeds high-quality labels into our governance and safety controls. We use MLflow to trace experiments and monitor efficiency over time, and we’re integrating the perfect concepts from LogSentinel again into the Databricks Information Classification product so clients can profit from the identical method.
Why this System Issues
This method is designed to maneuver three concrete enterprise levers for platform, knowledge and safety groups:
- Shorter compliance cycles: recurring evaluation duties that beforehand took weeks of analyst time are actually accomplished in hours as a result of columns are pre-labeled and pre-triaged earlier than people take a look at them.
- Decrease operational threat: the system constantly detects labeling drift and schema adjustments, so delicate fields are much less more likely to quietly slip via with incorrect or lacking tags.
- Stronger coverage enforcement: dependable labels now straight drive masking, entry management, retention, and residency guidelines, turning what was “best-effort governance” into executable coverage.
In observe, groups can plug new tables into an ordinary pipeline, monitor drift metrics and exceptions, and depend on the system to implement PII and residency constraints with out constructing a bespoke classifier for each area.
System Structure at a Look
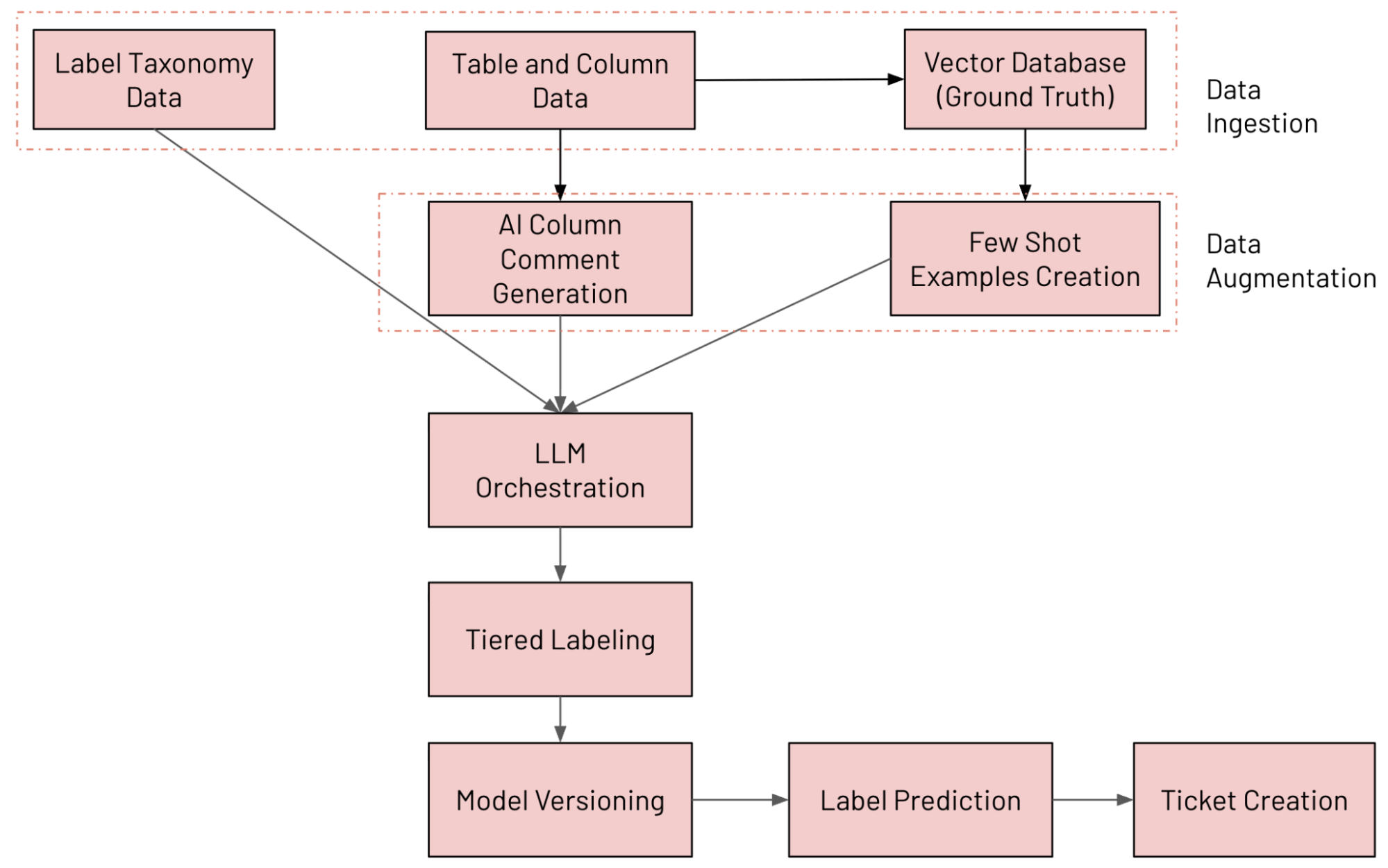
We constructed an LLM-powered column classification system on Databricks that constantly annotates tables utilizing our inside knowledge taxonomy, detects labeling drift, and opens remediation tickets when one thing appears fallacious. The assorted parts concerned within the system are outlined under (tracked and evaluated utilizing MLFlow):
- Information Ingestion: Ingesting numerous knowledge sources (together with Unity Catalog column knowledge, label taxonomy knowledge and floor fact knowledge)
- Information Augmentation: Augmenting knowledge utilizing Databricks Vector Search and AI Remark technology
- LLM Orchestration
- Tiered Labeling System
- Mannequin Versioning: Working a number of fashions in parallel
- Label Prediction: Predicting closing label utilizing Combination of Specialists (MoE) method
- Ticket Creation: Detecting violations and producing JIRA tickets
The tip-to-end workflow is proven within the determine under
{kind=link}
Information Ingestion
For every log sort or dataset to be annotated, we randomly pattern values from each column and ship the next metadata into the system: desk identify, column identify, sort, current remark, and a small pattern of values. To cut back LLM price and enhance throughput, a number of columns from the identical desk are batched collectively in a single request.
Our taxonomy is outlined utilizing Protocol Buffers and presently consists of greater than 100 hierarchical knowledge labels, with room for customized extensions when groups want further classes. This offers governance and platform stakeholders a shared contract for what “PII” and “delicate” imply past a handful of regexes.
Information Augmentation
Two augmentation methods considerably enhance classification high quality:
- AI column remark technology: when feedback are lacking, we use Databricks AI-generated feedback to synthesize concise, human-readable descriptions that assist each the LLM and future desk shoppers.
- Few-shot instance technology: we preserve a floor fact dataset and use each static examples and dynamic examples retrieved by way of Vector Search; for every column, we construct an embedding from identify, sort, remark, and context, then retrieve top-Ok comparable labeled columns to incorporate within the immediate.
Static prompting is finest throughout early levels or when labeled knowledge is proscribed, offering consistency and reproducibility. Dynamic prompting is more practical in mature programs, utilizing vector search to drag comparable examples and adapt to new schemas and knowledge domains in giant, various datasets.
LLM Orchestration
On the core of the system is a light-weight orchestration layer that manages LLM calls at manufacturing scale.
Key capabilities embody:
- Multi-model routing throughout internally hosted LLMs (for instance, Llama, Claude, and GPT-based fashions) with computerized fallback when a mannequin is unavailable.
- Retry logic for transient failures and price limits with exponential backoff.
- Validation hooks that detect empty, invalid, or hallucinated labels and re-run these instances with backup fashions.
- Batch processing that annotates a number of columns directly to optimize token utilization with out dropping context.
Tiered Labeling System
We predict three forms of labels per column:
- Granular labels, drawn from a set of 100+ fine-grained choices that energy masking, redaction, and tight entry controls.
- Hierarchical labels, which mixture associated granular labels into broader classes appropriate for monitoring and reporting.
- Residency labels, which point out whether or not knowledge should stay in-region or can transfer cross-region, straight feeding knowledge motion insurance policies.
To maintain predictions constant and cut back hallucinations, we use a two-stage circulation: a broad classification step assigns a high-level class, then a refinement step picks the precise label inside that class. This mirrors how a human reviewer would first determine “that is workspace knowledge” after which select the precise workspace identifier label.
Mannequin Versioning and Label Prediction
As an alternative of counting on a single “finest” configuration, every mannequin setup is handled as an professional that competes to label a column.
A number of mannequin variations run in parallel with variations in:
- Main and fallback LLM selections.
- Use of generated feedback vs. uncooked metadata.
- Prompting technique (static vs. dynamic few-shot).
- Label granularity and taxonomy subsets.
Every professional produces a label and a confidence rating between 0 and 100. The system then selects the label from the professional with the best confidence, a Combination-of-Specialists type method that improves accuracy and reduces the impression of occasional unhealthy predictions from anyone configuration.
This design makes it protected to experiment: new fashions or immediate methods may be launched, run alongside current ones, and evaluated on each metrics and downstream ticket quantity earlier than turning into the default.
Ticket Creation
The pipeline constantly compares present schema annotations with LLM predictions to floor significant deviations.
Typical instances embody:
- New columns added with none annotations.
- Current annotations that now not match the column’s content material.
- Columns containing delicate values which were labeled as eligible for cross-region motion.
When the system detects a violation, it creates a coverage entry and recordsdata a JIRA ticket for the proudly owning staff with context concerning the desk, column, proposed label, and confidence. This turns knowledge classification points into an ongoing workflow that groups can monitor and resolve in the identical manner they monitor different manufacturing incidents.
Affect and Analysis
The system was evaluated on 2,258 labeled samples, of which 1,010 contained PII and 1,248 had been non-PII. On this dataset, it reached as much as 92% precision and 95% recall for PII detection.
Extra importantly for stakeholders, the deployment produced the operational outcomes that had been wanted:
- Guide evaluation effort dropped from weeks to hours for every large-scale audit cycle as a result of reviewers begin from high-quality steered labels reasonably than uncooked schemas.
- Labeling drift is now detected constantly as schemas evolve, as a substitute of being found throughout an annual evaluation.
- Alerts about delicate knowledge mis-labeled as protected are extra focused, so safety groups can act rapidly as a substitute of triaging noisy rule-based scanners.
- Masking and residency insurance policies are enforced at scale utilizing the identical label taxonomy that powers analytics and reporting.
Precision and recall act as guardrails, however the system is tuned round outcomes resembling evaluation time, drift detection latency, and the amount of actionable tickets produced per week.
Conclusion
By combining taxonomy-driven labeling and an MoE-style analysis framework, we’ve enabled current engineering and governance workflows at Databricks, with experiments and deployments managed utilizing MLflow. It retains labels contemporary as schemas change, makes compliance critiques sooner and extra targeted, and gives the enforcement hooks wanted to use masking and residency guidelines constantly throughout the platform.
Probably the most thrilling a part of this work is integrating our inside learnings straight into the Information Classification product. As we operationalize and validate these methods inside LogSentinel, we incorporate our methods straight in Databricks Information Classification.
The identical sample—ingest metadata and samples, increase context, orchestrate a number of LLMs, and feed predictions into coverage and ticketing programs—may be reused wherever dependable, evolving understanding of information is required. By incorporating these insights inside our core product providing, we’re enabling each group to leverage their knowledge intelligence for compliance and governance with the identical precision and scale we do at Databricks.
Acknowledgements
This mission was made doable via collaboration amongst a number of engineering groups. Due to Anirudh Kondaveeti, Sittichai Jiampojamarn, Zefan Xu, Li Yang, Xiaohui Solar, Dibyendu Karmakar, Chenen Liang, Viswesh Periyasamy, Chengzu Ou, Evion Kim, Matthew Hayes, Benjamin Ebanks, Sudeep Srivastava for his or her assist and contributions.