
{kind=link}
Organizations immediately are utilizing information greater than ever to drive decision-making and innovation. As a result of they work with petabytes of knowledge, they’ve historically gravitated in the direction of two distinct paradigms—information lakes and information warehouses. Whereas every paradigm excels at particular use circumstances, they typically create unintended boundaries between the info property.
Information lakes are sometimes constructed on object storage similar to Amazon Easy Storage Service (Amazon S3), which give flexibility by supporting various information codecs and schema-on-read capabilities. This permits multi-engine entry the place varied processing frameworks (similar to Apache Spark, Trino, and Presto) can question the identical information. Then again, information warehouses (similar to Amazon Redshift) excel in areas similar to ACID (atomicity, consistency, isolation and sturdiness) compliance, efficiency optimization, and simple deployment, making them appropriate for structured and complicated queries. As information volumes develop and analytics wants turn out to be extra advanced, organizations search to bridge these silos and use the strengths of each paradigms. That is the place the idea of lakehouse structure is utilized, providing a unified method to information administration and analytics.
Over time, a number of distinct lakehouse approaches have emerged. On this submit, we present you find out how to consider and select the appropriate lakehouse sample on your wants.
The information lake centric lakehouse method begins with the scalability, cost-effectiveness, and suppleness of a standard information lake constructed on object storage. The objective is so as to add a layer of transactional capabilities and information administration historically present in databases, primarily by open desk codecs (similar to Apache Hudi, Delta Lake, or Apache Iceberg). Whereas open desk codecs have made vital strides by introducing ACID ensures for single-table operations in information lakes, implementing multi-table transactions with advanced referential integrity constraints and joins stays difficult. The elemental nature of querying petabytes of information on object storage, typically by distributed question engines, can lead to sluggish interactive queries at excessive concurrency when in comparison with a extremely optimized, listed, and materialized information warehouse. Open desk codecs introduce compaction and indexing, however the full suite of clever storage optimizations present in extremely mature, proprietary information warehouses remains to be evolving in information lake-centric structure.
The information warehouse centric lakehouse method gives sturdy analytical capabilities however has vital interoperability challenges. Although information warehouses present JAVA Database Connectivity (JDBC) and Open Database Connectivity (ODBC) drivers for exterior entry, the underlying information stays in proprietary codecs, making it troublesome for exterior instruments or providers to instantly entry it with out advanced extract, remodel, and cargo (ETL) or API layers. This will result in information duplication and latency. An information warehouse structure would possibly assist studying open desk codecs, however its means to jot down to them or take part of their transactional layers will be restricted. This restricts true interoperability and may create shadow information silos.
On AWS, you possibly can construct a trendy, open lakehouse structure to realize unified entry to each information warehouses and information lakes. By utilizing this method, you possibly can construct subtle analytics, machine studying (ML), and generative AI purposes whereas sustaining a single supply of reality for his or her information. You don’t have to decide on between a knowledge lake or information warehouse. You should use present investments and protect the strengths of each paradigms whereas eliminating their respective weaknesses. The lakehouse structure on AWS embraces open desk codecs similar to Apache Hudi, Delta Lake, and Apache Iceberg.
You may speed up your lakehouse journey with the subsequent technology of Amazon SageMaker, which delivers an built-in expertise for analytics and AI with unified entry to information. SageMaker is constructed on an open lakehouse structure that’s absolutely suitable with Apache Iceberg. By extending assist for Apache Iceberg REST APIs, SageMaker considerably provides interoperability and accessibility throughout varied Apache Iceberg-compatible question engines and instruments. On the core of this structure is a metadata administration layer constructed on AWS Glue Information Catalog and AWS Lake Formation, which give unified governance and centralized entry management.
Foundations of the Amazon SageMaker lakehouse structure
The lakehouse structure of Amazon SageMaker has 4 predominant parts that work collectively to create a unified information platform.
- Versatile storage to adapt to the workload patterns and necessities
- Technical catalog that serves as a single supply of reality for all metadata
- Built-in permission administration with fine-grained entry management throughout all information property
- Open entry framework constructed on Apache Iceberg REST APIs for common compatibility
Catalogs and permissions
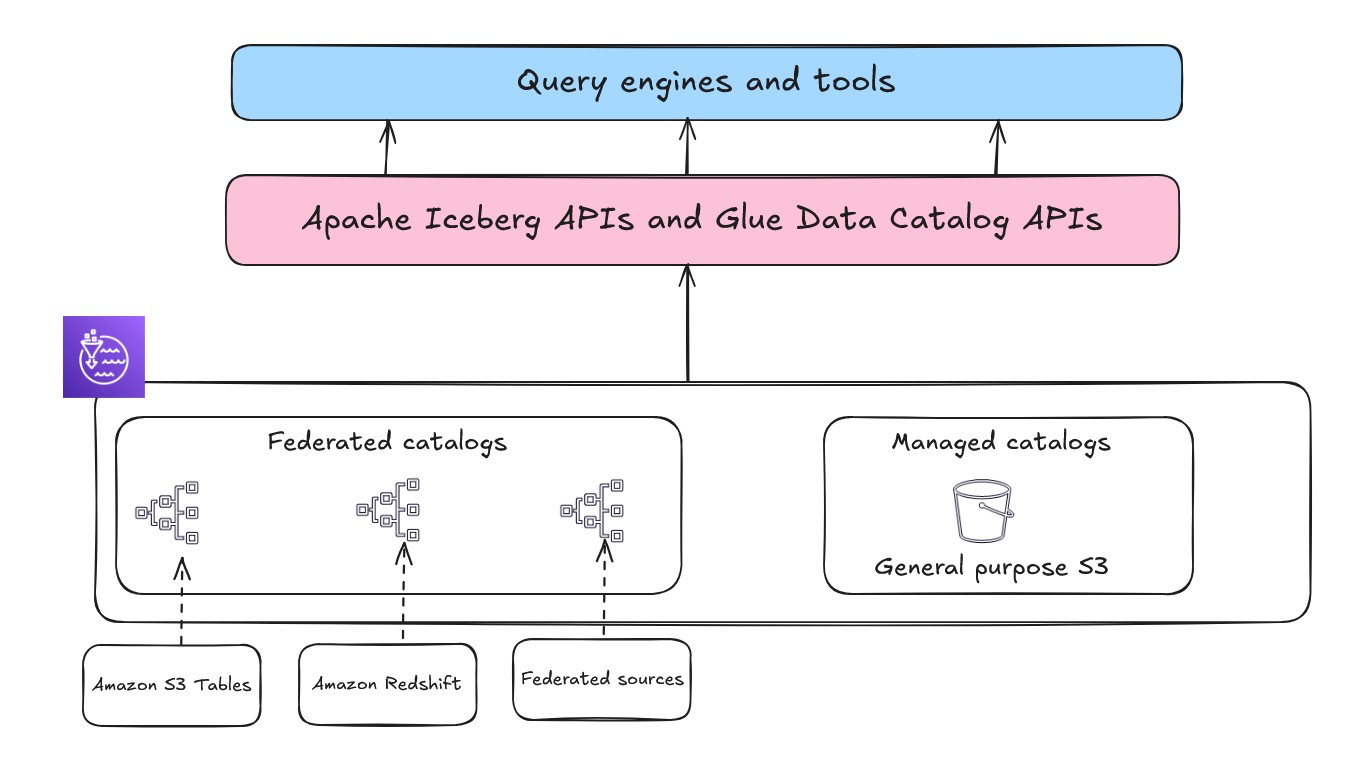
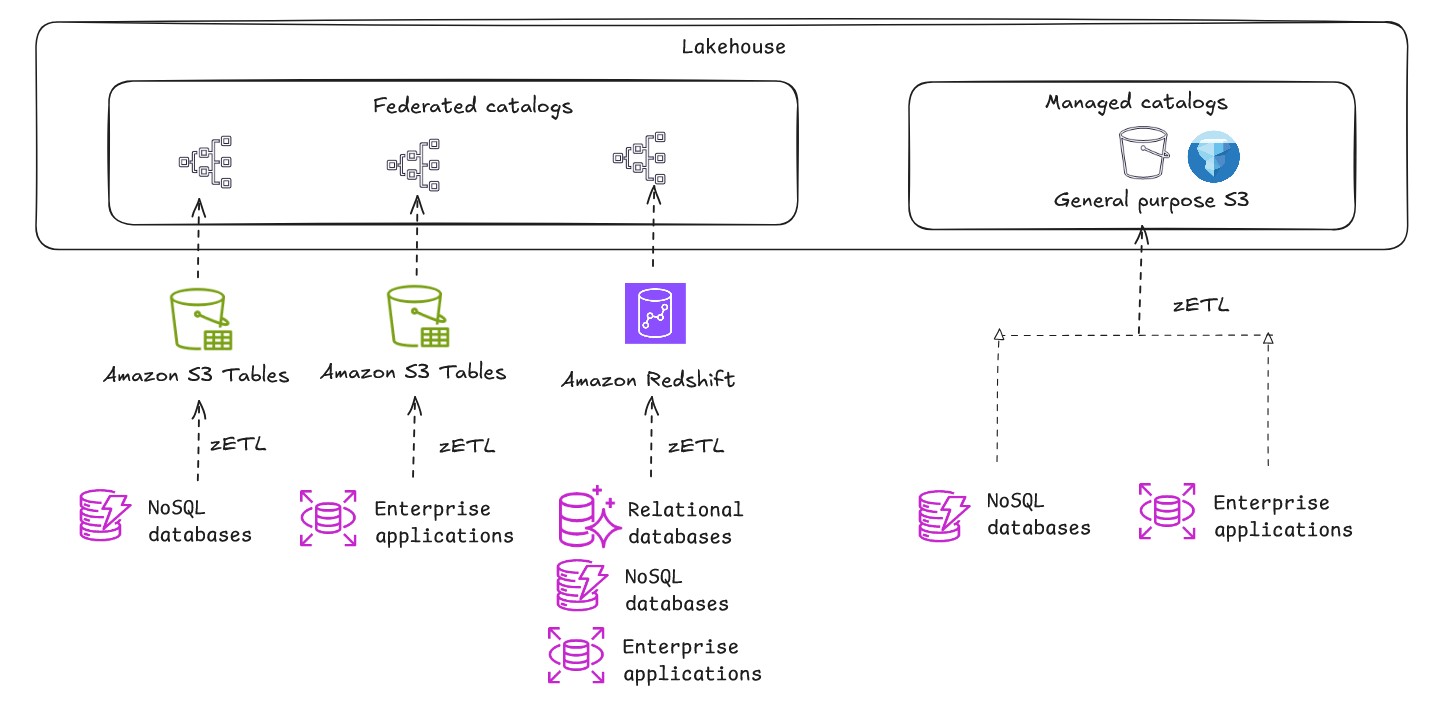
When constructing an open lakehouse, the catalog—your central repository of metadata—is a important element for information discovery and governance. There are two sorts of catalogs within the lakehouse structure of Amazon SageMaker: managed catalogs and federated catalogs.
You should use an AWS Glue crawler to mechanically uncover and register this metadata in Information Catalog. Information Catalog shops the schema and desk metadata of your information property, successfully turning information into logical tables. After your information is cataloged, the subsequent problem is controlling who can entry it. Whilst you may use advanced S3 bucket insurance policies for each folder, this method is troublesome to handle and scale. Lake Formation gives a centralized database-style permissions mannequin on the Information Catalog, supplying you with the pliability to grant or revoke fine-grained entry at row, column, and cell ranges for particular person customers or roles.
Open entry with Apache Iceberg REST APIs
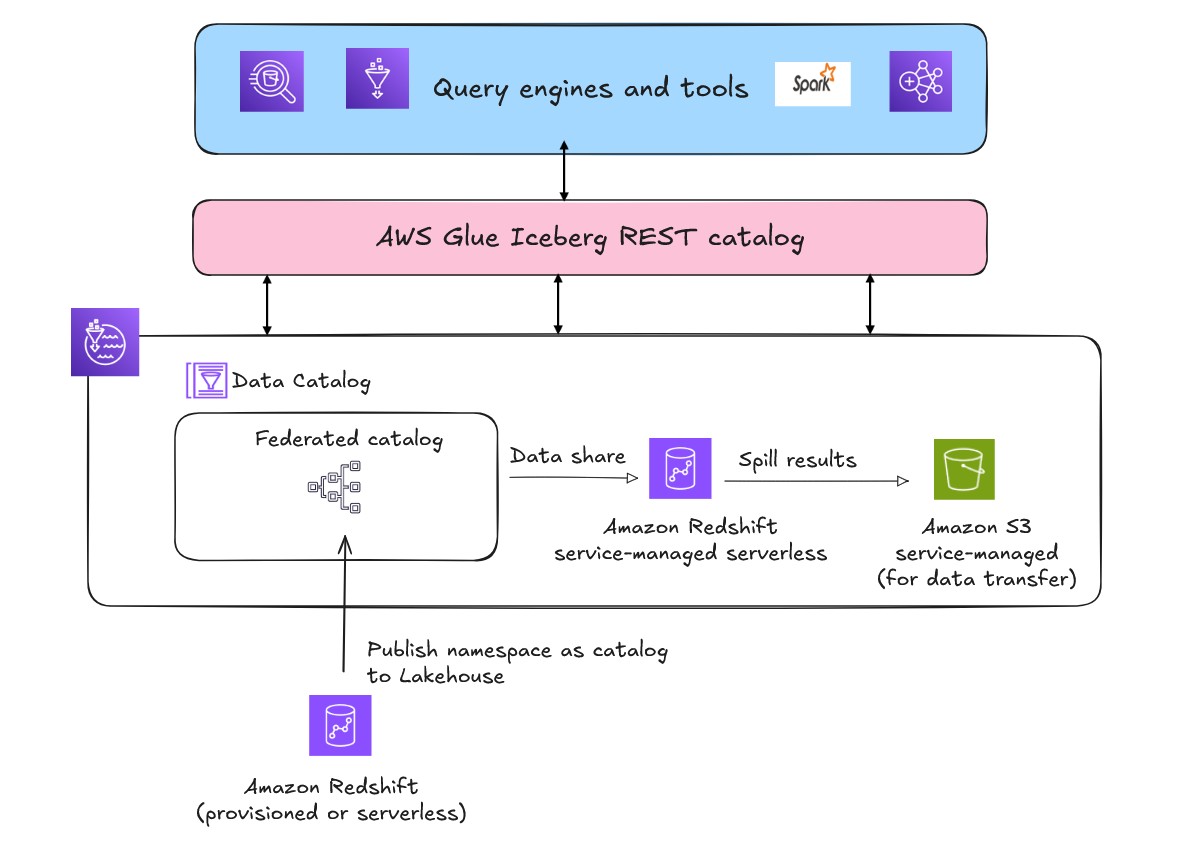
The lakehouse structure described within the previous part and proven within the following determine additionally makes use of the AWS Glue Iceberg REST catalog by the service endpoint, which gives OSS compatibility, enabling elevated interoperability for managing Iceberg desk metadata throughout Spark and different open supply analytics engines. You may select the suitable API primarily based on desk format and use case necessities.
{kind=link}
On this submit, we discover varied lakehouse structure patterns, specializing in find out how to optimally use information lake and information warehouse to create sturdy, scalable, and performance-driven information options.
Bringing information into your lakehouse on AWS
When constructing a lakehouse structure, you possibly can select from three distinct patterns to entry and combine your information, every providing distinctive benefits for various use circumstances.
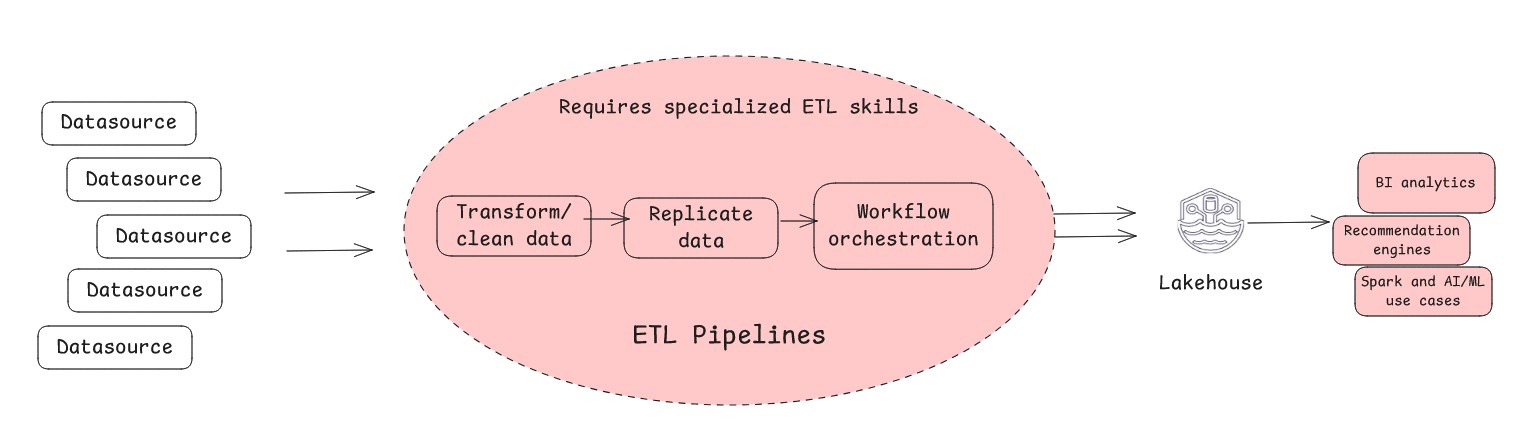
- Conventional ETL is the traditional technique of extracting information, remodeling it and loading it into your lakehouse.
When to make use of it:
-
- You want advanced transformations and require extremely curated and optimized information units for downstream purposes for higher efficiency
- You should carry out historic information migrations
- You want information high quality enforcement and standardization at scale
- You want extremely ruled curated information in a lakehouse
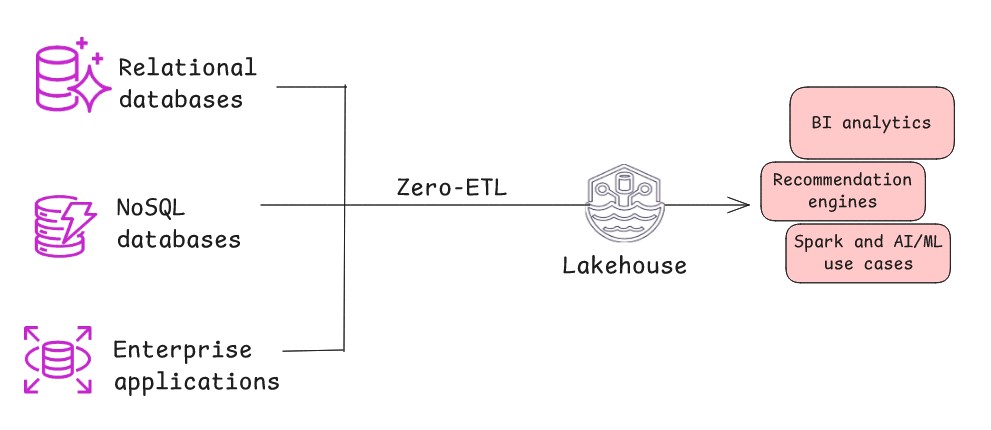
- Zero-ETL is a contemporary architectural sample the place information mechanically and repeatedly replicates from a supply system to lakehouse with minimal or no handbook intervention or customized code. Behind the scenes, the sample makes use of change information seize (CDC) to mechanically stream all new inserts, updates, and deletes from the supply to the goal. This architectural sample is efficient when the supply system maintains a excessive diploma of knowledge cleanliness and construction, minimizing the necessity for heavy pre-load transformations, or when information refinement and aggregation can happen on the goal finish inside lakehouse. Zero-ETL replicates information with minimal delay, and the transformation logic is carried out on the goal finish nearer to the place the insights are generated by shifting it to a extra environment friendly, post-load section.
When to make use of it:
-
- You should scale back operational complexity and acquire versatile management over information replication for each close to real-time and batch use circumstances.
- You want restricted customization. Whereas zero-ETL implies minimal work, some gentle transformations would possibly nonetheless be required on the replicated information.
- You should reduce the necessity for specialised ETL experience.
- You should preserve information freshness with out processing delays and scale back danger of knowledge inconsistencies. Zero-ETL facilitates quicker time-to-insight.
- Information federation (no-movement method) is a technique that permits querying and mixing information from a number of disparate sources with out bodily shifting or copying it right into a single centralized location. This query-in-place method permits the question engine to attach on to the exterior supply methods, delegate and execute queries, and mix outcomes on the fly for presentation to the person. The effectiveness of this structure sample will depend on three key components: community latency between methods, supply system efficiency capabilities, and the question engine’s means to push down predicates to optimize question execution. This no-movement method can considerably scale back information duplication and storage prices whereas offering real-time entry to supply information.
When to make use of it:
-
- You should question the supply system instantly to make use of operational analytics.
- You don’t need to duplicate information to avoid wasting on cupboard space and related prices inside your Lakehouse.
- You’re keen to commerce some question efficiency and governance for quick information availability and one-time evaluation of dwell information.
- You don’t must often question the info.
Understanding the storage layer of your lakehouse on AWS
Now that you just’ve seen alternative ways to get information right into a lakehouse, the subsequent query is the place to retailer the info. As proven within the following determine, you possibly can architect a contemporary open lakehouse on AWS by storing the info in a knowledge lake (Amazon S3 or Amazon S3 Tables) or information warehouse (Redshift Managed Storage), so you possibly can optimize for each flexibility and efficiency primarily based in your particular workload necessities.
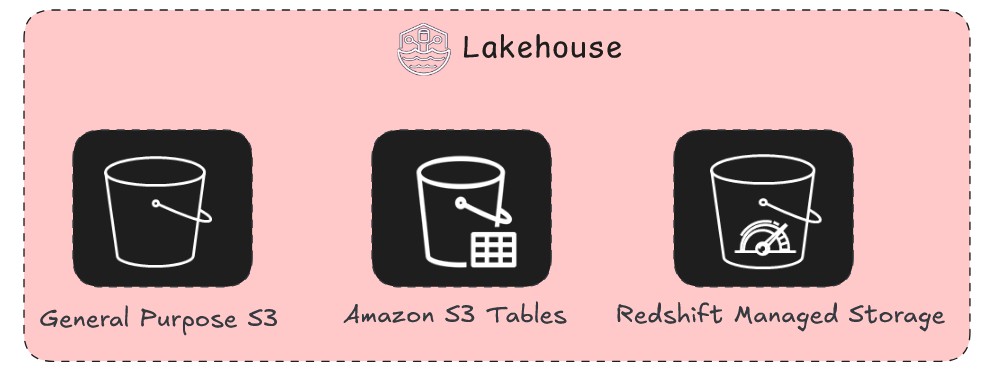
A contemporary lakehouse isn’t a single storage know-how however a strategic mixture of them. The choice of the place and find out how to retailer your information impacts the whole lot from the pace of your dashboards to the effectivity of your ML fashions. You have to take into account not solely the preliminary value of storage but in addition the long-term prices of knowledge retrieval, the latency required by your customers, and the governance vital to keep up a single supply of reality. On this part, we delve into architectural patterns for the info lake and the info warehouse and supply a transparent framework for when to make use of every storage sample. Whereas they’ve traditionally been seen as competing architectures, the fashionable and open lakehouse method makes use of each to create a single, highly effective information platform.
Normal goal S3
A basic goal S3 bucket in Amazon S3 is the usual, foundational bucket kind used for storing objects. It gives flexibility in an effort to retailer your information in its native format and not using a inflexible upfront schema. Due to the power of an S3 bucket to decouple storage from compute, you possibly can retailer the info in a extremely scalable location, whereas a wide range of question engines can entry and course of it independently. This implies that you would be able to select the appropriate software for the job with out having to maneuver or duplicate the info. You may retailer petabytes of knowledge with out ever having to provision or handle storage capability, and its tiered storage lessons present vital value financial savings by mechanically shifting less-frequently accessed information to extra inexpensive storage.
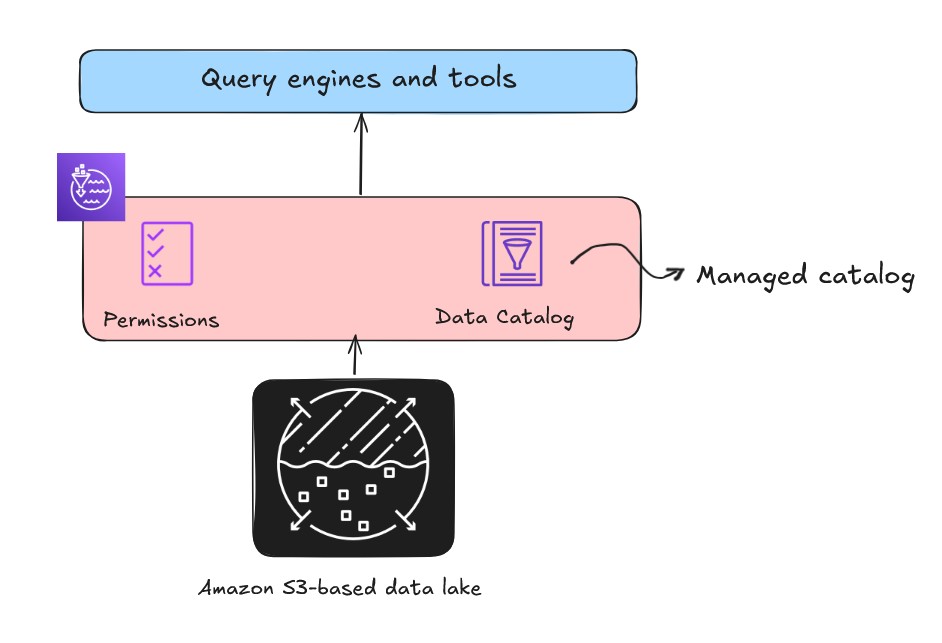
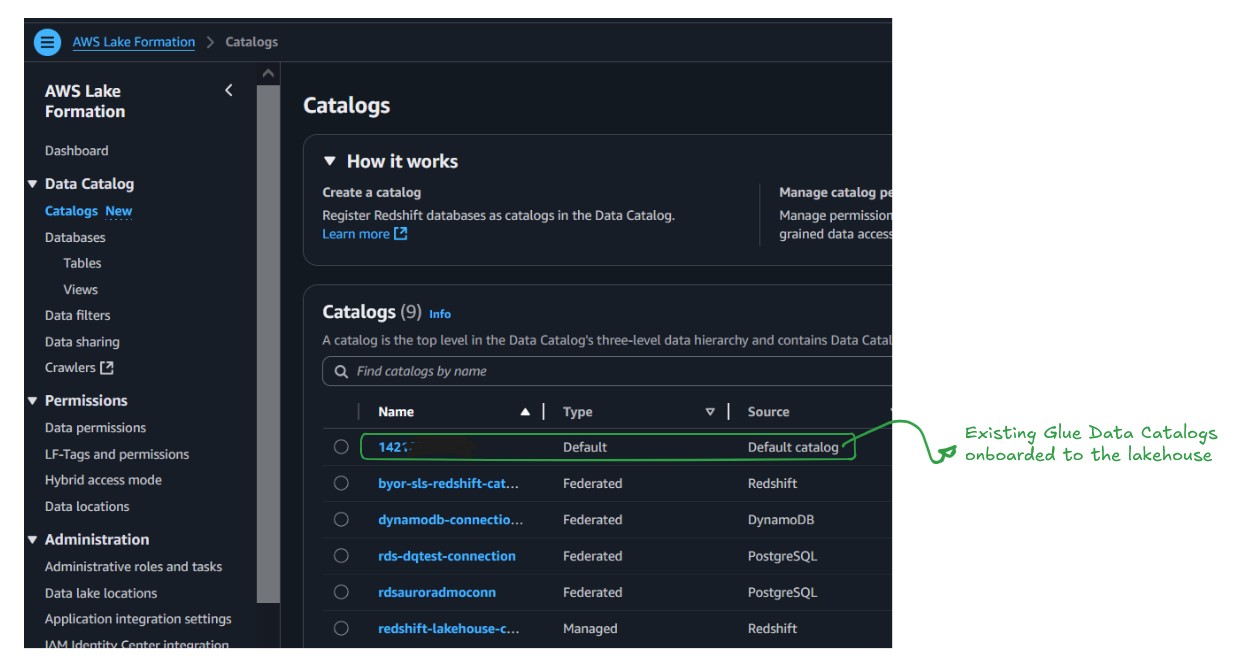
The present Information Catalog capabilities as a managed catalog. It’s recognized by the AWS account quantity, which implies there isn’t a migration wanted for present Information Catalogs; they’re already accessible within the lakehouse and turn out to be the default catalog for the brand new information, as proven within the following determine.
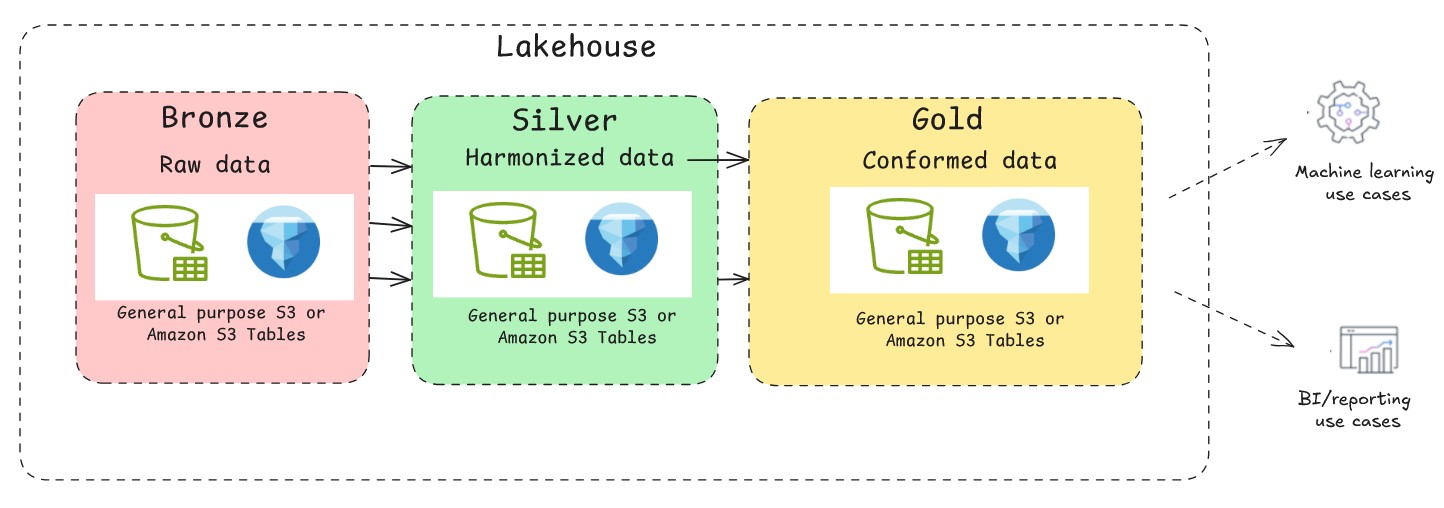
A foundational information lake on basic goal S3 is very environment friendly for append-only workloads. Nonetheless, its file-based nature lacks the transactional ensures of a standard database. That is the place you should use the assist of open-source transactional desk codecs similar to Apache Hudi, Delta Lake, and Apache Iceberg. With these desk codecs, you possibly can implement multi-version concurrency management, permitting a number of readers and writers to function concurrently with out conflicts. They supply snapshot isolation, in order that readers see constant views of knowledge even throughout write operations. A typical medallion structure sample with Apache Iceberg is depicted within the following determine. When constructing a lakehouse on AWS with Apache Iceberg, prospects can select between two major approaches for storing their information on Amazon S3: Normal goal S3 buckets with self-managed Iceberg or utilizing the absolutely managed S3 Tables. Every path has distinct benefits, and the appropriate alternative will depend on your particular wants for management, efficiency, and operational overhead.
Normal goal S3 with Self-managed Iceberg
Utilizing basic goal S3 buckets with self-managed Iceberg is a standard method the place you retailer each information and Iceberg metadata information in customary S3 buckets. With this selection, you preserve full management however are liable for managing the entire Iceberg desk lifecycle, together with important upkeep duties similar to compaction and rubbish assortment.
When to make use of it:
- Most management: This method gives full management over all the information life cycle. You may fine-tune each side of desk upkeep, similar to defining your personal compaction schedules and methods, which will be essential for particular high-performance workloads or to optimize prices.
- Flexibility and customization: It’s very best for organizations with robust in-house information engineering experience that must combine with a wider vary of open-source instruments and customized scripts. You should use Amazon EMR or Apache Spark to handle the desk operations.
- Decrease upfront prices: You pay just for Amazon S3 storage, API requests, and the compute assets you utilize for upkeep. This may be more cost effective for smaller or less-frequent workloads the place steady, automated optimization isn’t vital.
Observe: The question efficiency relies upon fully in your optimization technique. With out steady, scheduled jobs for compaction, efficiency can degrade over time as information will get fragmented. You have to monitor these jobs to make sure environment friendly querying.
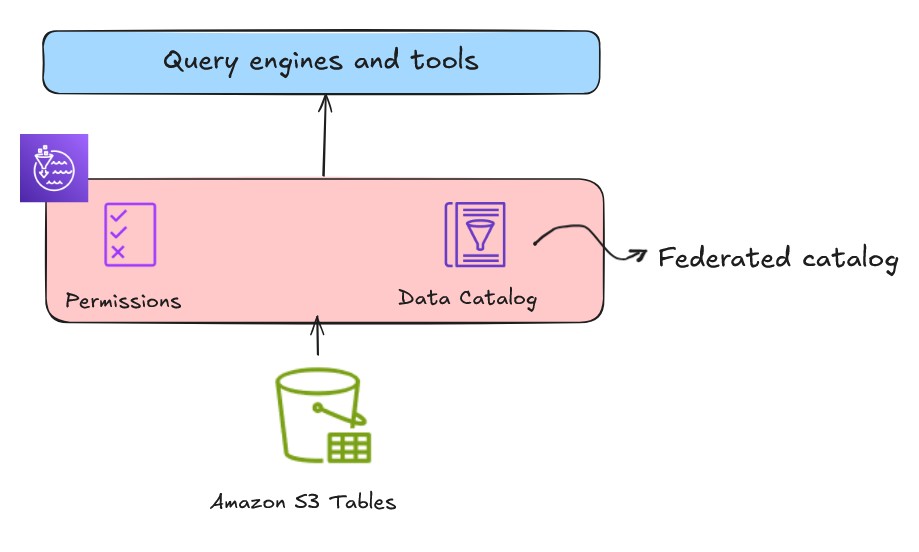
S3 Tables
S3 Tables gives S3 storage that’s optimized for analytic workloads and gives Apache Iceberg compatibility to retailer tabular information at scale. You may combine S3 desk buckets and tables with Information Catalog and register the catalog as a Lake Formation information location from the Lake Formation console or utilizing service APIs, as proven within the following determine. This catalog might be registered and mounted as a federated lakehouse catalog.
When to make use of it:
- Simplified operations: S3 Tables mechanically handles desk upkeep duties similar to compaction, snapshot administration and orphan file cleanup within the background. This automation eliminates the necessity to construct and handle customized upkeep jobs, considerably lowering your operational overhead.
- Automated optimization: S3 Tables gives built-in automated optimizations that enhance question efficiency. These optimizations embrace background processes similar to file compaction to deal with the small information downside and information structure optimizations particular to tabular information. Nonetheless, this automation trades flexibility for comfort. As a result of you possibly can’t management the timing or technique of compaction operations, workloads with particular efficiency necessities would possibly expertise various question efficiency.
- Concentrate on information utilization: S3 Tables reduces the engineering overhead and shifts the main target to information consumption, information governance and worth creation.
- Simplified entry to open desk codecs: It’s appropriate for groups who’re new to the idea of Apache Iceberg however need to use transactional capabilities on information lake.
- No exterior catalog: Appropriate for smaller groups who don’t need to handle an exterior catalog.
Redshift managed storage
Whereas the info lake serves because the central supply of reality for all of your information, it’s not probably the most appropriate information retailer for each job. For probably the most demanding enterprise intelligence and reporting workloads, the info lake’s open and versatile nature can introduce efficiency unpredictability. To assist guarantee the specified efficiency, take into account transitioning a curated subset of your information from the info lake to a knowledge warehouse for the next causes:
- Excessive concurrency BI and reporting: When a whole bunch of enterprise customers are concurrently working advanced queries on dwell dashboards, a knowledge warehouse is particularly optimized to deal with these workloads with predictable, sub-second question latency.
- Predictable efficiency SLAs:– For important enterprise processes that require information to be delivered at a assured pace, similar to monetary reporting or end-of-day gross sales evaluation, a knowledge warehouse gives constant efficiency.
- Complicated SQL workloads: Whereas information lakes are highly effective, they’ll wrestle with extremely advanced queries involving quite a few joins and large aggregations. An information warehouse is purpose-built to run these relational workloads effectively.
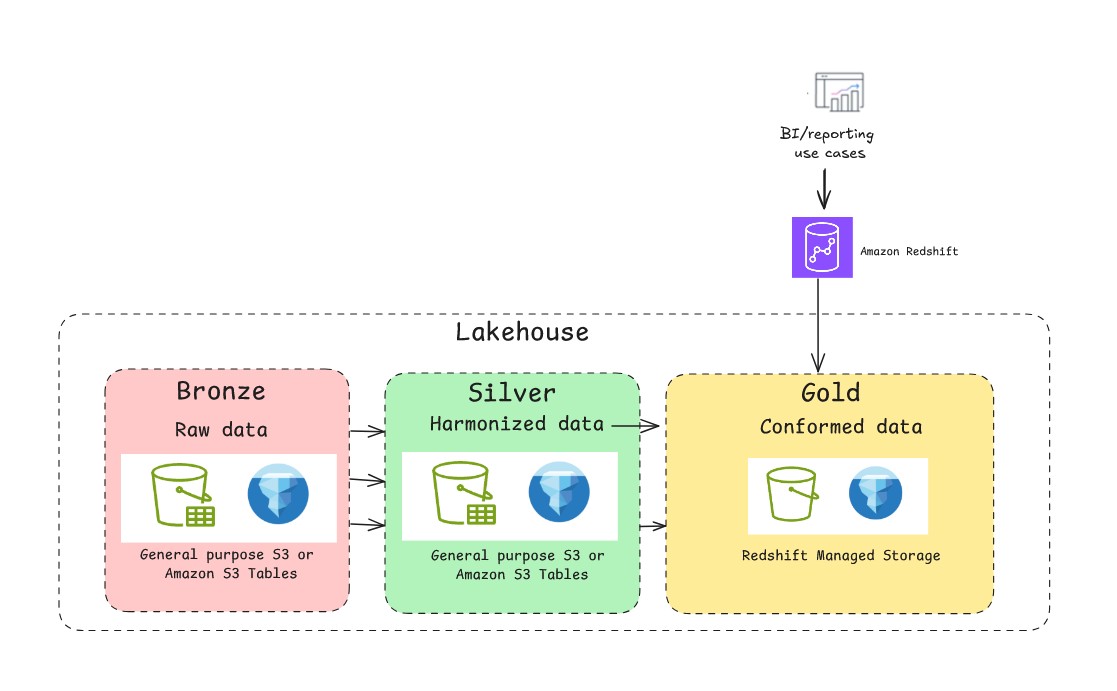
The lakehouse structure on AWS helps Redshift Managed Storage (RMS), a storage choice offered by Amazon Redshift, a completely managed, petabyte-scale information warehouse service within the cloud. RMS storage helps the automated desk optimization provided in Amazon Redshift similar to built-in question optimizations for information warehousing workloads, automated materialized views, and AI-driven optimizations and scaling for often working workloads.
Federated RMS catalog: Onboard present Amazon Redshift information warehouses to lakehouse
Implementing a federated catalog with present Amazon Redshift information warehouses creates a metadata-only integration that requires no information motion. This method enables you to lengthen your established Amazon Redshift investments into a contemporary open lakehouse framework whereas sustaining compatibility with present workflows. Amazon Redshift makes use of a hierarchical information group construction:
- Cluster stage: Begins with a namespace
- Database stage: Accommodates a number of databases
- Schema stage: Organizes tables inside databases
If you register your present Amazon Redshift provisioned or serverless namespaces as a federated catalog in Information Catalog, this hierarchy maps instantly into the lakehouse metadata layer. The lakehouse implementation on AWS helps a number of catalogs utilizing a dynamic hierarchy to prepare and map the underlying storage metadata.
After you register a namespace, the federated catalog mechanically mounts throughout all Amazon Redshift information warehouses in your AWS Area and account. Throughout this course of, Amazon Redshift internally creates exterior databases that correspond to information shares. This mechanism stays utterly abstracted from finish customers. By utilizing federated catalogs, you possibly can create and use quick visibility and accessibility throughout your information ecosystem. Permissions on the federated catalogs will be managed by Lake Formation for each similar account and cross account entry.
The actual functionality of federated catalogs emerges when accessing Amazon Redshift-managed storage from exterior AWS engines similar to Amazon Athena, Amazon EMR, or open supply Spark. As a result of Amazon Redshift makes use of proprietary block-based storage that solely Amazon Redshift engines can learn natively, AWS mechanically provisions a service-managed Amazon Redshift Serverless occasion within the background. This service-managed occasion acts as a translation layer between exterior engines and Amazon Redshift managed storage. AWS establishes automated information shares between your registered federated catalog and the service-managed Amazon Redshift Serverless occasion to allow safe, environment friendly information entry. AWS additionally creates a service-managed Amazon S3 bucket within the background for information switch.
When an exterior engine similar to Athena submits queries in opposition to Amazon Redshift federated catalog, Lake Formation handles the credential merchandising by offering the short-term credentials to the requesting service. The question executes by the service-managed Amazon Redshift Serverless, which accesses information by mechanically established information shares, processes outcomes, offloads them to a service-managed Amazon S3 staging space, after which returns outcomes to the unique requesting engine.
To trace the compute value of the federated catalog of present Amazon Redshift warehouse, use the next tag.
aws:redshift-serverless:LakehouseManagedWorkgroup worth: "True"
To activate the AWS generated value allocation tags for billing perception, observe the activation directions. You can even view the computational value of the assets in AWS Billing.
When to make use of it:
- Current Amazon Redshift investments: Federated catalogs are designed for organizations with present Amazon Redshift deployments who need to use their information throughout a number of providers with out migration.
- Cross-service information sharing:– Implement so groups can share present information in an Amazon Redshift information warehouse throughout completely different warehouses and centralize their permissions.
- Enterprise integration necessities: This method is appropriate for organizations that must combine with established information governance. It additionally maintains compatibility with present workflows whereas including lakehouse capabilities.
- Infrastructure management and pricing:– You may retain full management over compute capability for his or her present warehouses for predictable workloads. You may optimize compute capability, select between on-demand and reserved capability pricing, and fine-tune efficiency parameters. This gives value predictability and efficiency management for constant workloads.
When implementing lakehouse structure with a number of catalog varieties, choosing the suitable question engine is essential for each efficiency and value optimization. This submit focuses on the storage basis of lakehouse, nonetheless for important workloads involving intensive Amazon Redshift information operations, take into account executing queries inside Amazon Redshift or utilizing Spark when doable. Complicated joins spanning a number of Amazon Redshift tables by exterior engines would possibly lead to greater compute prices if the engines don’t assist full predicate push-down.
Different use-cases
Construct a multi-warehouse structure
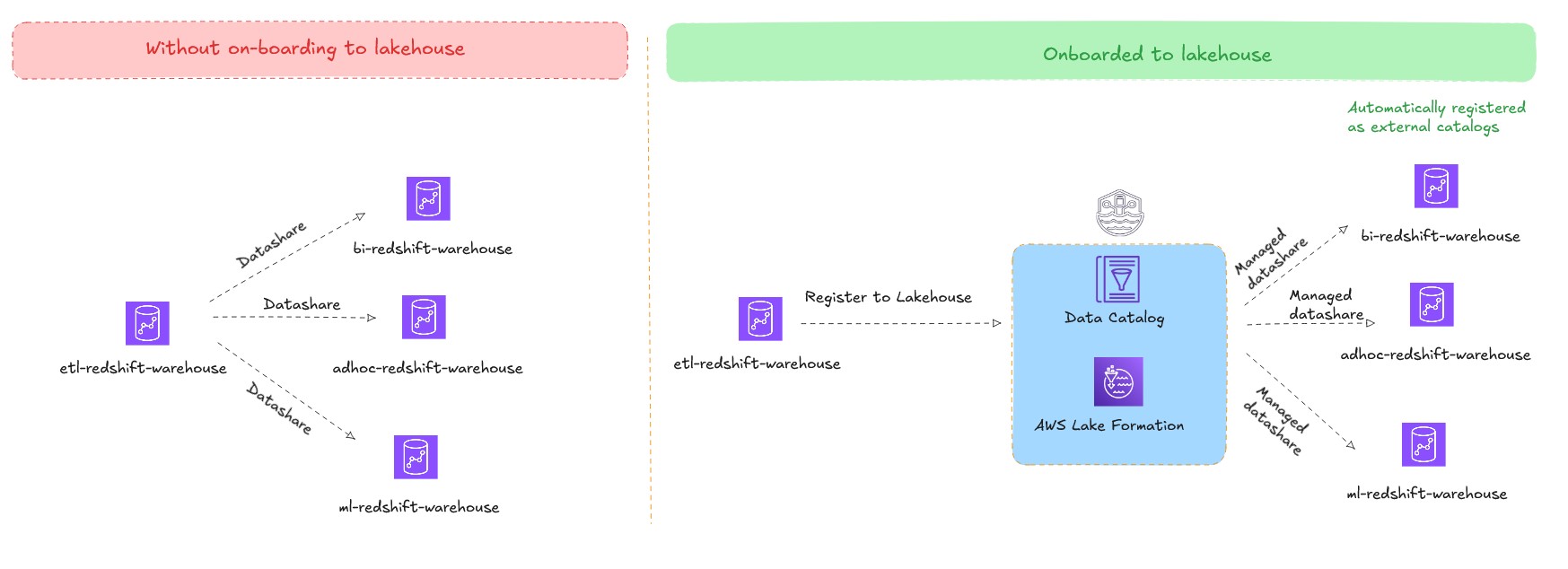
Amazon Redshift helps information sharing, which you should use to share dwell information between supply and goal Amazon Redshift clusters. By utilizing information sharing, you possibly can share dwell information with out creating copies or shifting information, enabling makes use of circumstances similar to workload isolation (hub and spoke structure) and cross group collaboration (information mesh structure). And not using a lakehouse structure, you have to create an specific information share between supply and goal Amazon Redshift clusters. Whereas managing these information shares in small deployments is comparatively simple, it turns into advanced in information mesh architectures.
The lakehouse structure addresses this problem so prospects can publish their present Amazon Redshift warehouses as federated catalogs. These federated catalogs are mechanically mounted and made accessible as exterior databases in different client Amazon Redshift warehouses throughout the similar account and Area. By utilizing this method, you possibly can preserve a single copy of knowledge and use a number of information warehouses to question it, eliminating the necessity to create and handle a number of information shares and scale with workload isolation. The permission administration turns into centralized by Lake Formation, streamlining governance throughout all the multi-warehouse atmosphere.
Close to real-time analytics on petabytes of transactional information with no pipeline administration:
Zero-ETL integrations seamlessly replicate transactional information from OLTP information sources to Amazon Redshift, basic goal S3 (with self-managed Iceberg) or S3 Tables. This method eliminates the necessity to preserve advanced ETL pipelines, lowering the variety of shifting elements in your information structure and potential factors of failure. Enterprise customers can analyze contemporary operational information instantly quite than working with stale information from the final ETL run.
See Aurora zero-ETL integrations for a listing of OLTP information sources that may be replicated to an present Amazon Redshift warehouse.
See Zero-ETL integrations for details about different supported information sources that may be replicated to an present Amazon Redshift warehouse, basic goal S3 with self-managed Iceberg, and S3 Tables.
Conclusion
A lakehouse structure isn’t about selecting between a knowledge lake and a knowledge warehouse. As an alternative, it’s an method to interoperability the place each frameworks coexist and serve completely different functions inside a unified information structure. By understanding elementary storage patterns, implementing efficient catalog methods, and utilizing native storage capabilities, you possibly can construct scalable, high-performance information architectures that assist each your present analytics wants and future innovation. For extra data, see The lakehouse structure of Amazon SageMaker.
Concerning the authors