
{kind=link}
(ra2 studio/Shutterstock)
Neo4j this week unveiled its new Infinigraph structure that it says addresses one of many basic challenges within the scaling of graph databases: the issue in conserving a graph database’s construction in reminiscence as the amount of information will increase. The innovation will unleash new scale for operational use circumstances, resembling fraud detection, and in addition bolster rising GraphRAG workloads, the corporate says.
Due to the way in which they retailer information in linked nodes, graph databases are in a position to run some varieties of data-intensive workloads an order of magnitude extra effectively than conventional relational databases. As a substitute of performing compute-intensive joins to establish connections in a given information set–resembling individuals who have labored with a selected firm–a property graph like Neo4j’s can discover the similarities with a easy question, because the information was initially modeled upon connections to start with. Along with getting solutions faster, graphs can save CPU cycles and energy and expense that entails.
Nevertheless, there are limitations to the graph method. For starters, graph databases work finest when the whole graph could be loaded into reminiscence. That isn’t an issue for smaller information units, but it surely turns into a problem as the scale of the information grows. Neo4j was initially constructed to run on giant symmetric multi-processor (SMP) scale-up machines with a lot of reminiscence. It began creating a distributed, scale-out model of its database about 5 years in the past to handle clients with very giant datasets. Whereas it made progress within the distributed world, the basic limitations in utilizing graphs in a distributed structure stay.
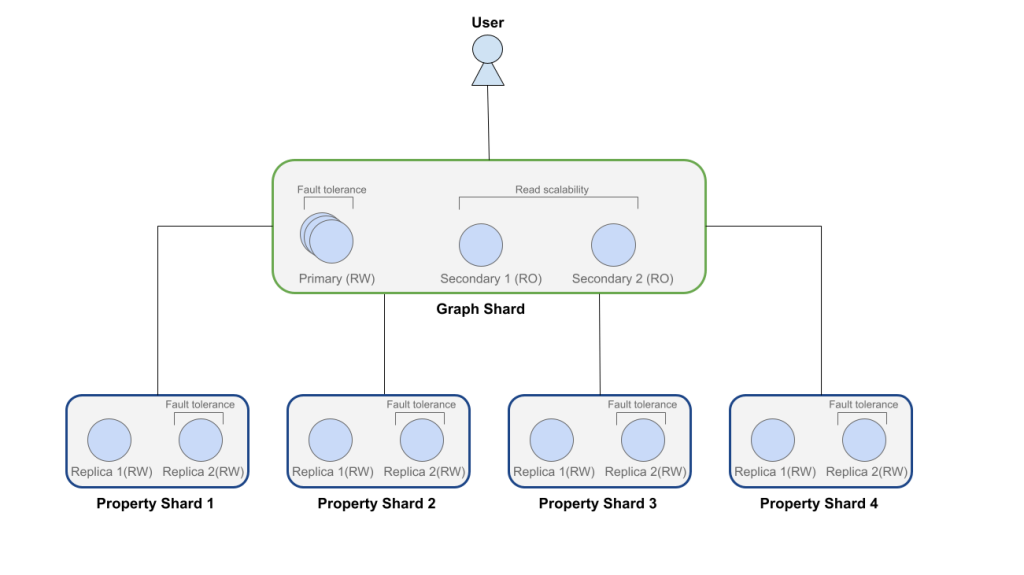
Infinigraph permits Neo4j to scale horizontally whereas conserving nodes and edges in reminiscence (Picture courtesy Neo4j)
Neo4j’s launch of Infinigraph represents an modern resolution to this dilemma. The corporate determined to compromise on the varieties of information that it separated to run on separate nodes, or sharded. As a substitute of splitting the core elements of its property graph structure–specifically the nodes and relationships–and sharding them out to separate machines in a cluster, with Infinigraph, the corporate elected to shard solely properties related to the nodes and relationships, thereby conserving the nodes and relationships intact in the identical reminiscence house.
Properties in a graph database are the values related to a node or a relationship. Every node or relationship can have any variety of properties related to it. For example, a node for a “particular person” may need properties resembling “title” or “age,” whereas the connection element may need extra proprieties, like a selected date or location for a “WorksAt” property.
With Infinigraph, Neo4j is introducing property sharding, which allows the nodes and relationships to remain on a single server whereas the possibly voluminous properties are saved in separate nodes in a cluster, says Dan McGrath, Neo4j’s VP of product administration for cloud.
“One of many nice challenges within the database business has been scaling transactional and analytical graph workloads with out sacrificing efficiency, construction, or ease of use,” McGrath wrote in a weblog submit. “Infinigraph structure solves this problem by distributing a graph’s property information throughout the servers in a cluster. Property sharding permits the graph itself to stay logically complete; queries behave as anticipated, and purposes scale with out code modifications or handbook workarounds.”
In accordance with McGrath, every entity within the Neo4j graph shard has precisely one corresponding entity in a property shard, and when a question requests properties, the system mechanically fetches them from the suitable shard, whereas traversal stays native to the topology shard.![]()
“The entire system runs in an autonomous cluster,” he wrote. “The graph shard types an everyday Raft group, making certain availability and failover. Property shards could be scaled independently by including replicas, which gives them with excessive availability, a brand new function launched for property sharding within the Neo4j autonomous cluster.”
No modifications are required to the graph database purposes with Infinigraph, Neo4j says, and Cypher queries work as earlier than. Nodes and relationships are written to the graph shard, whereas the precise properties of the nodes and relationships could also be written to a special shard. The developer nevertheless is writing only a single question, and the database figures out which property shard to fetch the information from.
This method brings many advantages, McGrath says, together with the potential to scale a graph past 100TB of information; the potential to embed billions of vectors immediately within the graph; eliminating the necessity for ETL pipelines; all whereas sustaining full ACID compliance.
Neo4j says this new method will assist groups conduct operational and analytic operations on the identical time, together with detecting fraud and analyzing fraud rings from the identical dataset, or producing real-time buyer suggestions whereas analyzing a long time of buyer information and behavioral traits. “They will energy GenAI assistants, compliance programs, and transactional purposes on one constant supply of fact,” the comapny says.
There are some limitations with the brand new method, nevertheless. The variety of property shards is mounted at creation within the first model of Infinigraph, and it doesn’t but assist computerized rebalancing. Neo4j recommends Infinigraph be used for property-heavy graphs.
Infinigraph is accessible now in Neo4j’s self-managed providing. It would quickly be out there in Neo4j AuraDB, the corporate’s cloud-native platform.
Associated Gadgets:
Neo4j Guarantees ‘No Extra ETL’ with Aura Graph Analytics
Neo4j Drives Simplicity with Graph Information Science Refresh
Neo4j Going Distributed with Graph Database