
{kind=link}
(Phuttharak/Shutterstock)
A startup known as PuppyGraph is popping heads within the huge knowledge world with a novel idea: Marrying the info storage effectivity of the info lakehouse with the analytic capabilities of a graph database. The result’s a distributed, column-oriented OLAP graph question engine that runs atop Iceberg or Parquet tables in an object retailer and may scale horizontally into the petabyte vary.
PuppyGraph was co-founded in 2023 by software program engineer Weimo Liu, who lower his enamel on distributed graph databases through the early days of TigerGraph earlier than becoming a member of Google. Liu, who’s CEO of the corporate, understands the advantages that the graph strategy holds, however has been pissed off with low adoption charges.
“A number of customers confirmed sturdy curiosity in graph, however most of them lastly finish in nothing,” Liu says. “It’s by no means in manufacturing. And folks received drained after they spend a number of time on it, and I believe there have to be one thing incorrect.”
Graph databases are well-known to carry a giant efficiency benefit over relational databases relating to executing sure forms of queries throughout linked knowledge. A graph database can effectively execute a multi-hop traverse to find {that a} given transaction is linked to a fraudster, for instance, whereas the identical workload would require an enormous SQL be a part of that will deliver a relational database to its knees.
However graph databases have a elementary limitation of their design: The information have to be ETL’d into the database earlier than the graph engine can do its factor. There’s downtime related to extracting the info from its supply, reworking it into the graph database format, after which loading it into the graph database. This has been the Achille’s Heal of graph databases used for analytics (though it’s not as limiting for OTLP workloads).
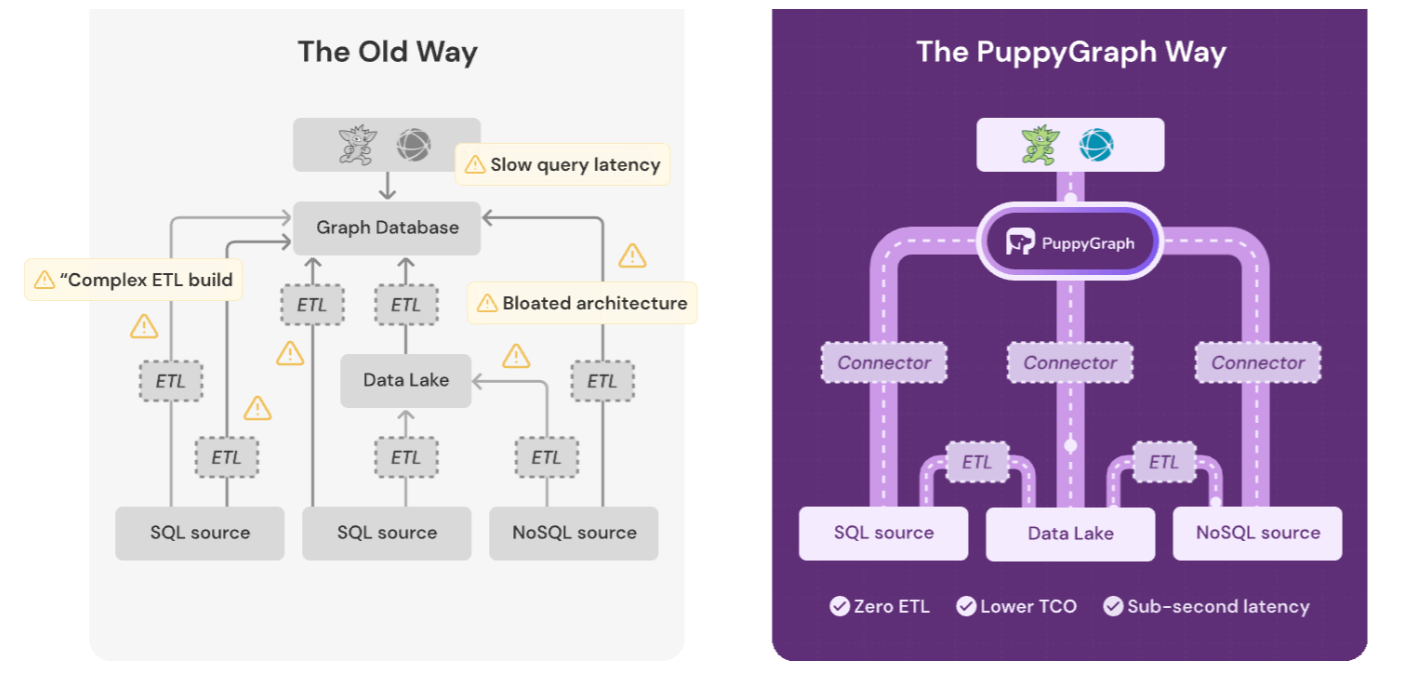
PuppyGraph is a column-oriented graph question engine for knowledge lakehouses (Picture courtesy PuppyGraph)
“I believe a giant blocker for the graph database adoption will not be a graph–it’s in regards to the database,” Liu says. “Loading the info from someplace else to graph database. That could be a huge drawback.”
Whereas at Google, Liu was impressed with the F1 question engine crew. A key ingredient of F1 is an information mannequin that helps desk columns with structured knowledge sorts. Based on Liu, this works as a common knowledge construction that permits varied knowledge codecs to be outlined as a desk that’s amendable to SQL queries.
“This can be a very inspiring design,” Liu tells BigDATAwire. “I believe if a graph can [use] the design, it can profit rather more.”
With PuppyGraph, Liu and his co-founders are hoping to remove that limitation within the graph database design. By separating the compute and storage layers and constructing a vectorized and column-oriented graph question engine, PuppyGraph says it could supply quick OLAP graph efficiency on huge knowledge sitting in object retailer, thereby eliminating the downtime related to loading knowledge into graph databases.
Simply as Trino and Presto have separated the storage from the SQL question engine and helped to drive the expansion of the lakehouse structure, PuppyGraph hopes to separate the storage from the graph question engine and make the most of knowledge lakehouses full of knowledge saved in open desk codecs, resembling Apache Iceberg.
PuppyGraph executes graph queries on knowledge saved in lakehouses (Picture courtesy PuppyGraph)
“If you have already got knowledge someplace else, like a Parquet file, or in PostgreSQL, MySQL, or Iceberg, we will simply straight question on high of it to run a graph question. Then the onboard price will likely be nearly zero,” Liu says. “And on the similar time, it solves the scalability subject, as a result of knowledge lakes like Iceberg and Delta Lake nearly don’t have any limitation on knowledge dimension. So we will leverage their storage after which reply the question, which was written in graph question language.”
PuppyGraph presently helps Cypher and Gremlin, the 2 hottest graph question languages. The corporate borrows from the Google F1 question engine design, which allows the question engine to map sure attributes of the supply knowledge right into a logical graph layer that’s composed of nodes and edges, the important thing components of the graph knowledge mannequin. This column-based strategy permits PuppyGraph to effectively run graph queries with out having to course of the entire knowledge in every file, Liu says.
“Every node or every edge can have tons of of attributes, however throughout one question, solely perhaps 5 or 6 will likely be accessed,” he says. “If we will leverage the column-based storage, we don’t must entry all the opposite attributes. We solely must put mandatory knowledge into the reminiscence, and it could deal with extra edges and nodes on the similar time, which is also a giant profit for the scalable graph analytics.”
Along with the logical graph layer operating atop columnar knowledge fashions, PuppyGraph additionally leverages caching and indexing to make its queries run quick, Liu says. The corporate has additionally adopted SIMD processing method to offer extra parallelism. The whole PuppyGraph product runs in a Docker container atop Kubernetes, which handles useful resource scheduling and offers elasticity.
After he constructed the primary PuppyGraph prototype, Liu contacted a number of the founders of Tabular, the business outfit behind the Iceberg desk format (since acquired by Databricks). The Iceberg founders had been impressed {that a} three-hop question on Azure ran quicker that devoted graph databases, Liu says. “They notice, oh, there’s a potential for different knowledge fashions,” he says.![]()
PuppyGraph is a younger firm (dare we are saying it’s nonetheless a “pup?”), but it surely already has paying prospects, together with one firm concerned in cryptocurrency. The corporate, which has attracted $5 million in seed funding, is concentrating on OLAP graph and graph analytic use circumstances, resembling fraud detection and regulatory compliance with its BYOC cloud choices. A totally managed model of PuppyGraph is within the works.
Whereas OLAP graph workloads are a very good match for PuppyGraph, the corporate doesn’t plan to chase OLTP graph alternatives, Liu says. These transaction-oriented graph workloads don’t endure from the identical knowledge loading and latency drawbacks that OLAP graph workloads do, he says.
However relating to graph analytics and knowledge science graph workloads, the parents at PuppyGraph are satisfied {that a} distributed graph question engine operating in a vectorized trend atop an information lakehouse full of Iceberg tables often is the ticket to graph riches.
“Customers need to analyze their knowledge as a graph, and what they want is a graph, not a graph database,” he says. “We need to deliver graph to their knowledge. In order that’s how we design our system.”
Associated Objects:
Why Younger Builders Don’t Get Information Graphs
Huge Graph Workloads Want Huge Cloud {Hardware}, Katana Graph Says
Graph Database ‘Shapes’ Knowledge