
{kind=link}
I’ve been making an attempt to grasp one of many newest AI coding buzzword: Spec-driven growth (SDD). I checked out three of the instruments that label themselves as SDD instruments and tried to untangle what it means, as of now.
Definition
Like with many rising phrases on this fast-paced area, the definition of “spec-driven growth” (SDD) continues to be in flux. Right here’s what I can collect from how I’ve seen it used thus far: Spec-driven growth means writing a “spec” earlier than writing code with AI (“documentation first”). The spec turns into the supply of fact for the human and the AI.
GitHub: “On this new world, sustaining software program means evolving specs. […] The lingua franca of growth strikes to a better degree, and code is the last-mile method.”
Tessl: “A growth method the place specs — not code — are the first artifact. Specs describe intent in structured, testable language, and brokers generate code to match them.”
After trying over the usages of the time period, and among the instruments that declare to be implementing SDD, it appears to me that in actuality, there are a number of implementation ranges to it:
- Spec-first: A properly thought-out spec is written first, after which used within the AI-assisted growth workflow for the duty at hand.
- Spec-anchored: The spec is saved even after the duty is full, to proceed utilizing it for evolution and upkeep of the respective characteristic.
- Spec-as-source: The spec is the principle supply file over time, and solely the spec is edited by the human, the human by no means touches the code.
All SDD approaches and definitions I’ve discovered are spec-first, however not all attempt to be spec-anchored or spec-as-source. And infrequently it’s left obscure or completely open what the spec upkeep technique over time is supposed to be.
What’s a spec?
The important thing query by way of definitions after all is: What’s a spec? There doesn’t appear to be a common definition, the closest I’ve seen to a constant definition is the comparability of a spec to a “Product Necessities Doc”.
The time period is sort of overloaded in the mean time, right here is my try at defining what a spec is:
A spec is a structured, behavior-oriented artifact – or a set of associated artifacts – written in pure language that expresses software program performance and serves as steerage to AI coding brokers. Every variant of spec-driven growth defines their method to a spec’s construction, degree of element, and the way these artifacts are organized inside a venture.
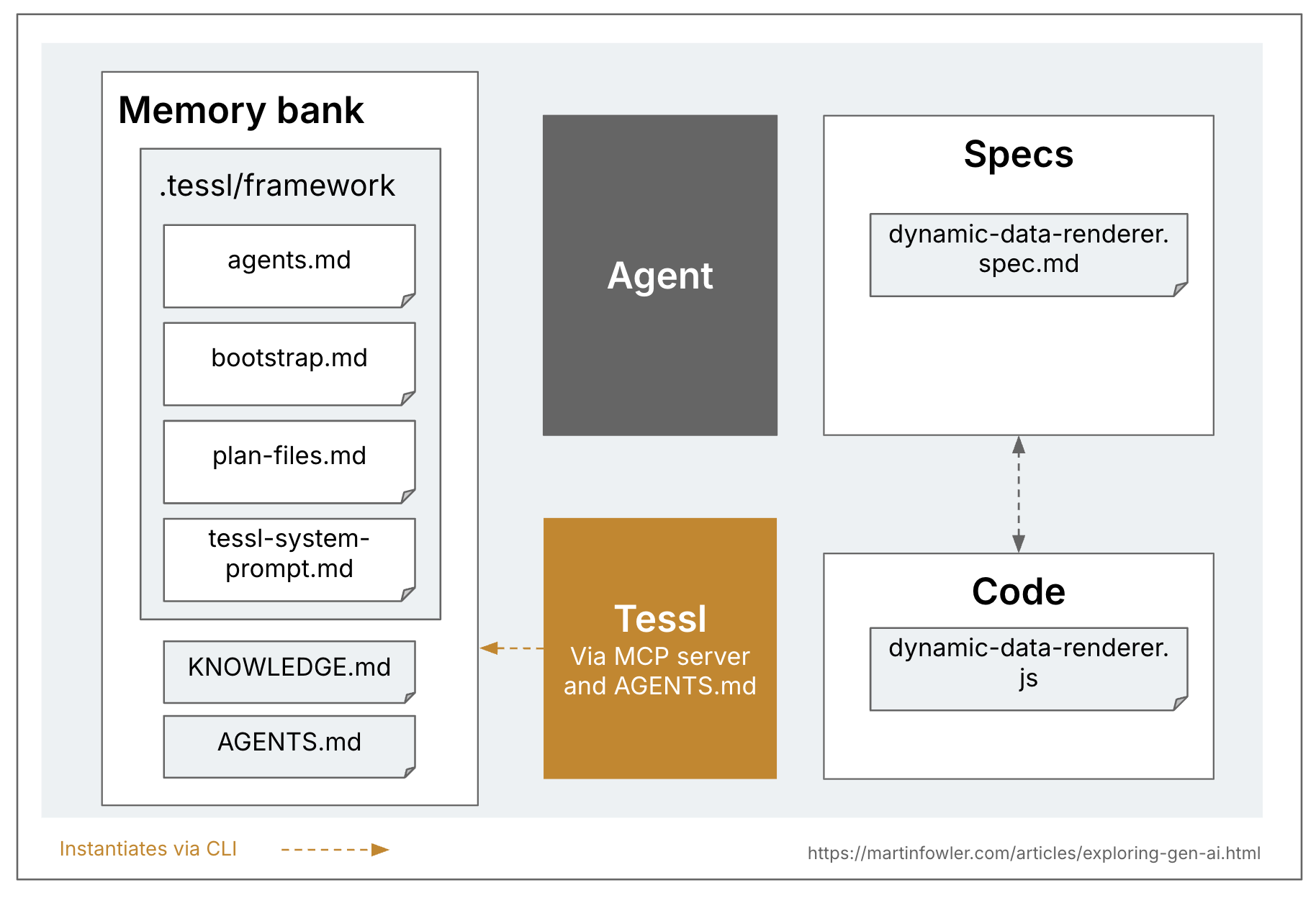
There’s a helpful distinction to be made I believe between specs and the extra common context paperwork for a codebase. That common context are issues like guidelines recordsdata, or excessive degree descriptions of the product and the codebase. Some instruments name this context a reminiscence financial institution, in order that’s what I’ll use right here. These recordsdata are related throughout all AI coding periods within the codebase, whereas specs solely related to the duties that really create or change that exact performance.
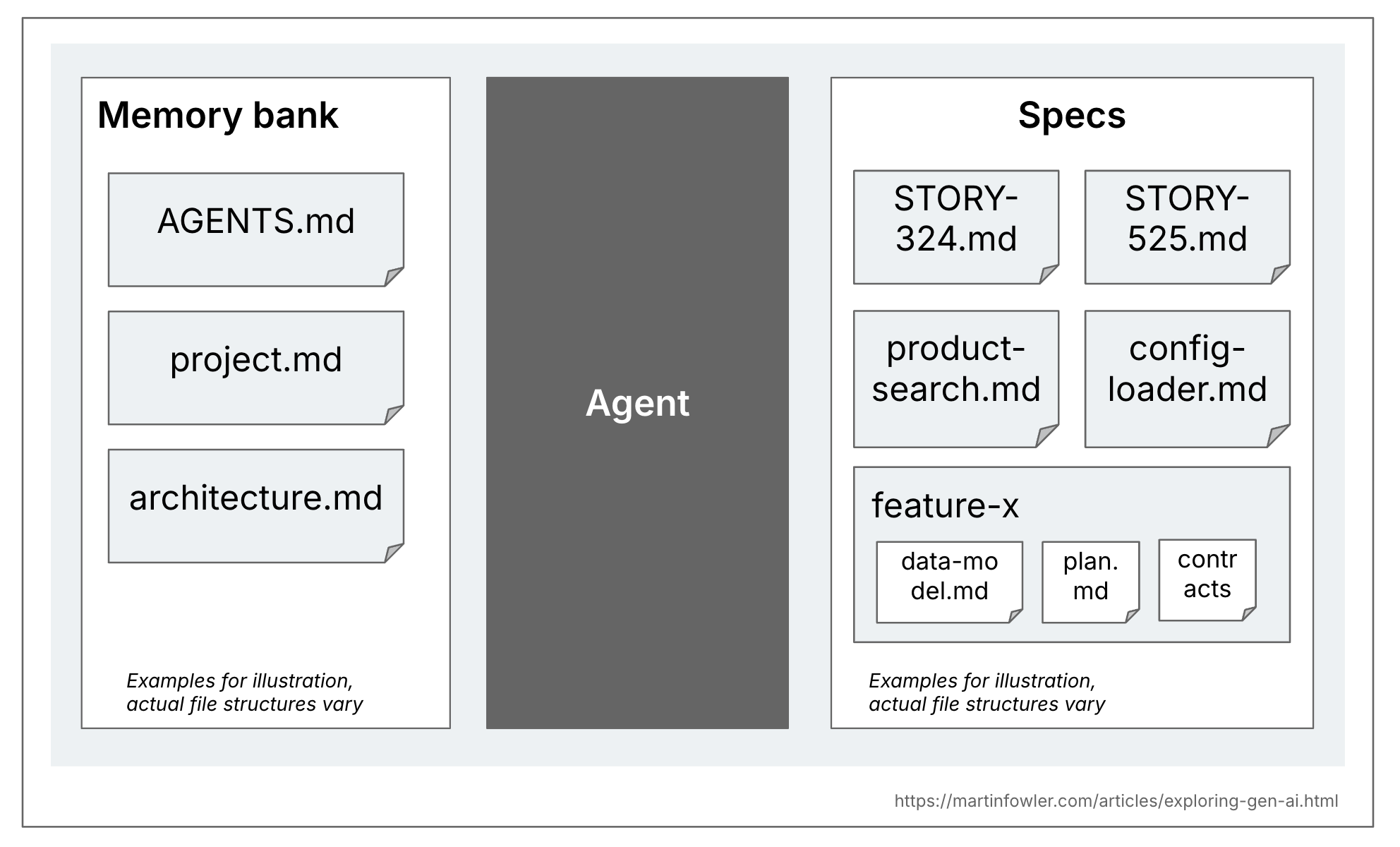
It seems to be fairly time-consuming to guage SDD instruments and approaches in a manner that will get near actual utilization. You would need to strive them out with totally different sizes of issues, greenfield, brownfield, and actually take the time to assessment and revise the intermediate artifacts with greater than only a cursory look. As a result of as GitHub’s weblog put up about spec-kit says: “Crucially, your position isn’t simply to steer. It’s to confirm. At every section, you mirror and refine.”
For 2 of the three instruments I attempted it additionally appears to be much more work to introduce them into an current codebase, subsequently making it even tougher to guage their usefulness for brownfield codebases. Till I hear utilization experiences from folks utilizing them for a time frame on a “actual” codebase, I nonetheless have plenty of open questions on how this works in actual life.
That being stated – let’s get into three of those instruments. I’ll share an outline of how they work first (or moderately how I believe they work), and can maintain my observations and questions for the top. Word that these instruments are very quick evolving, so they could have already modified since I used them in September.
Kiro
Kiro is the only (or most light-weight) one of many three I attempted. It appears to be principally spec-first, all of the examples I’ve discovered use it for a activity, or a consumer story, with no point out of tips on how to use the necessities doc in a spec-anchored manner over time, throughout a number of duties.
Workflow: Necessities → Design → Duties
Every workflow step is represented by one markdown doc, and Kiro guides you thru these 3 workflow steps within its VS Code primarily based distribution.
Necessities: Structured as a listing of necessities, the place every requirement represents a “Consumer Story” (in “As a…” format) with acceptance standards (in “GIVEN… WHEN… THEN…” format)
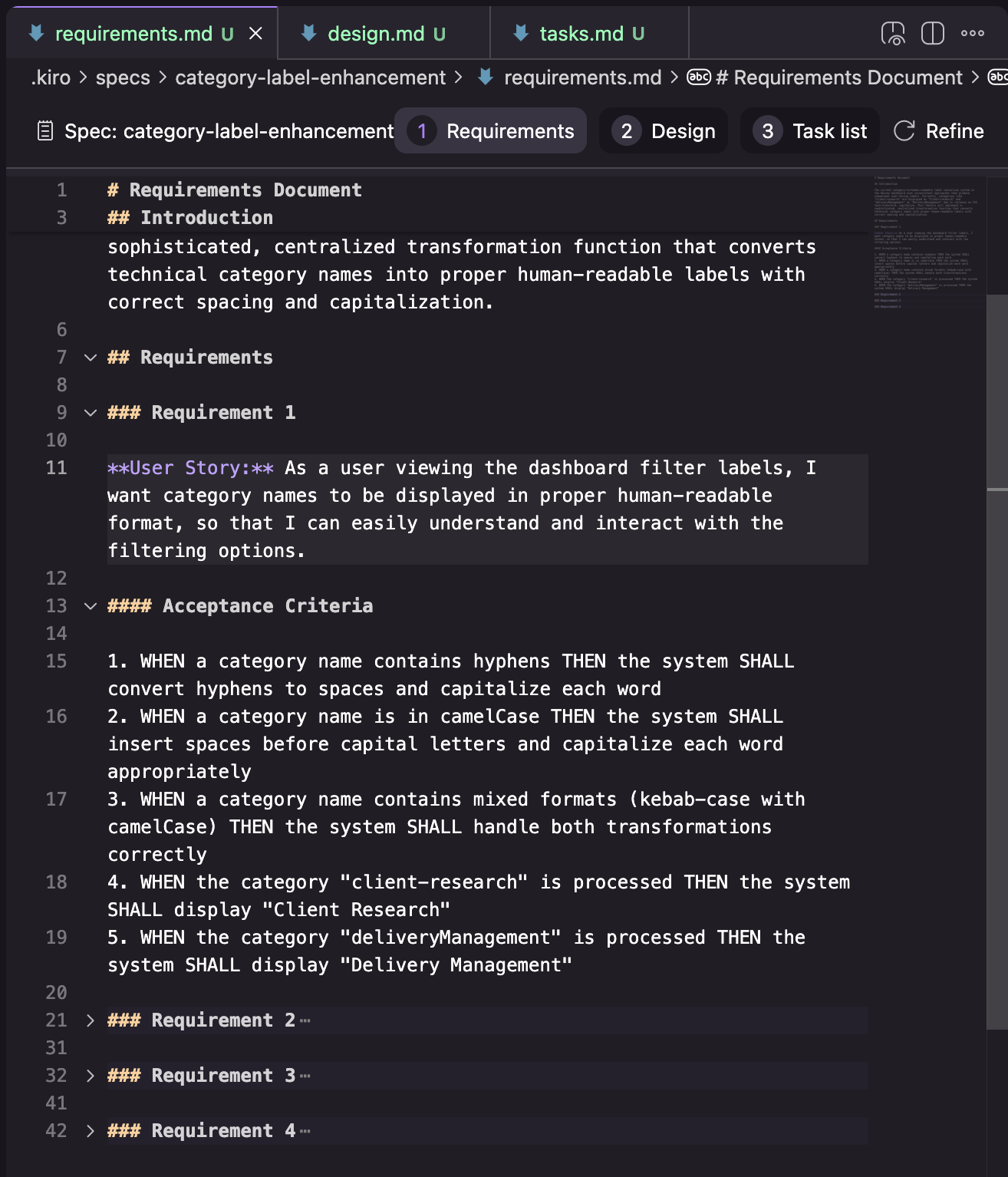
Design: In my try, the design doc consisted of the sections seen within the screenshot beneath. I solely have the outcomes of considered one of my makes an attempt nonetheless, so I’m undecided if it is a constant construction, or if it adjustments relying on the duty.
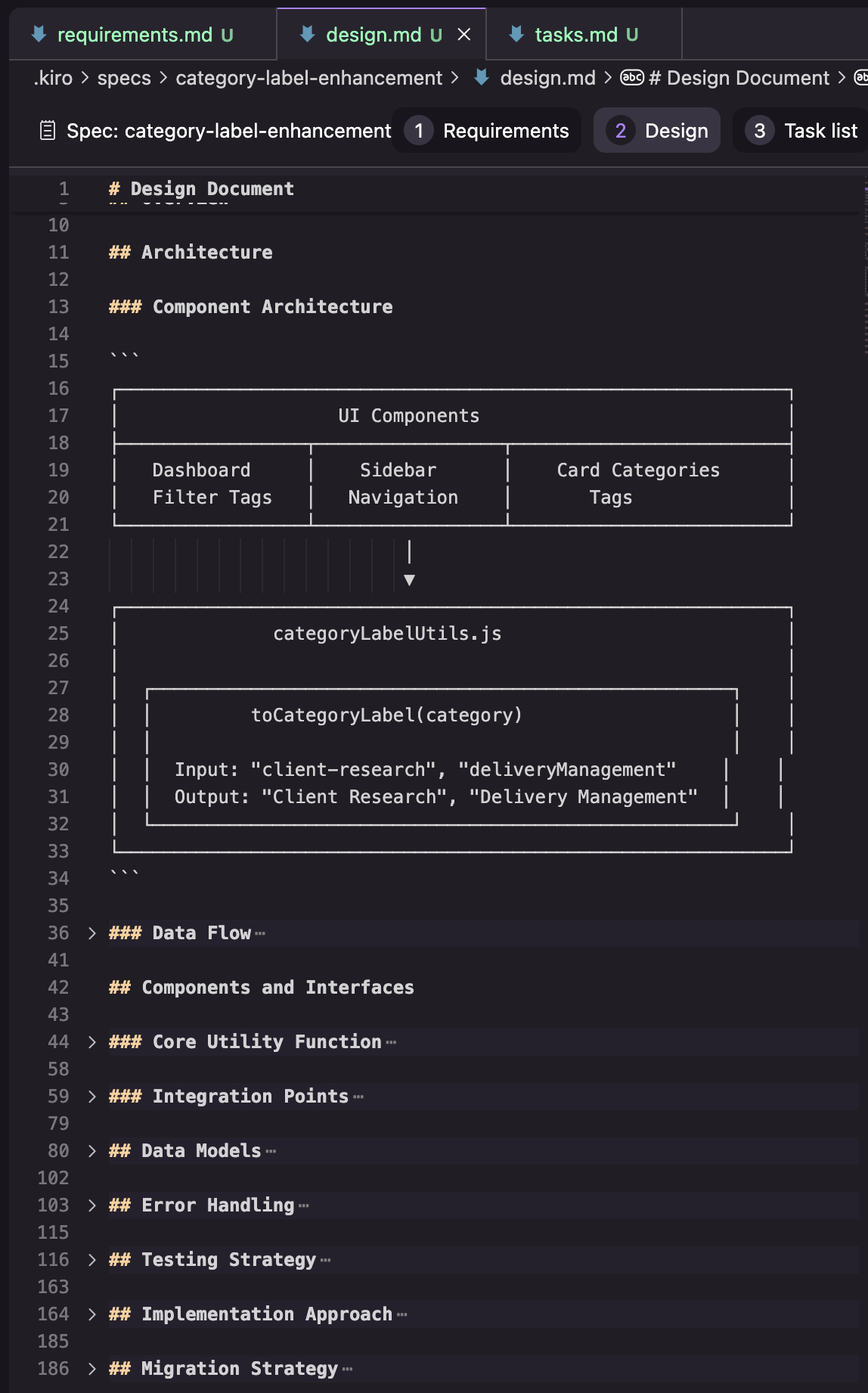
Duties: A listing of duties that hint again to the requirement numbers, and that get some additional UI components to run duties one after the other, and assessment adjustments per activity.
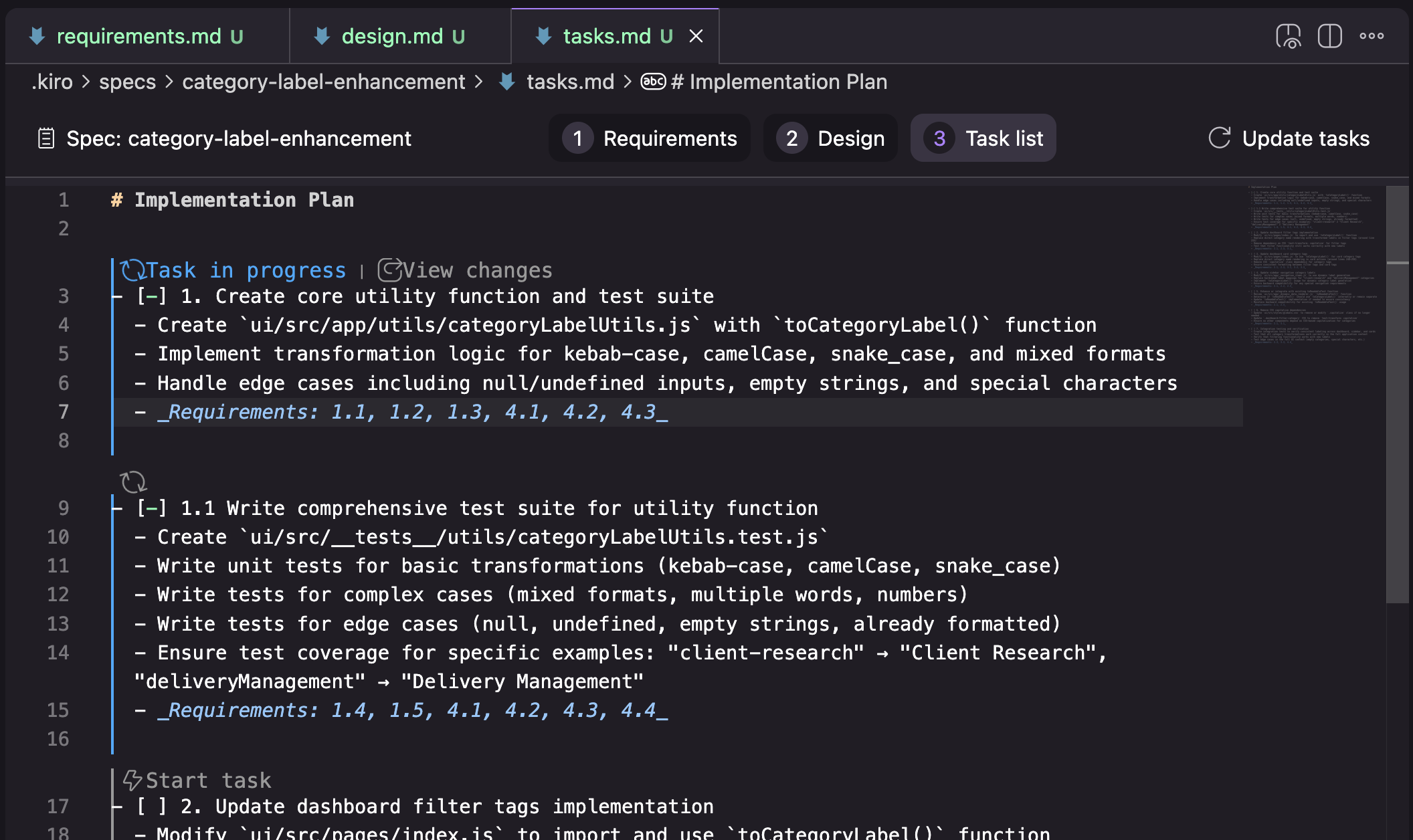
Kiro additionally has the idea of a reminiscence financial institution, they name it “steering”. Its contents are versatile, and their workflow doesn’t appear to depend on any particular recordsdata being there (I made my utilization makes an attempt earlier than I even found the steering part). The default topology created by Kiro once you ask it to generate steering paperwork is product.md, construction.md, tech.md.
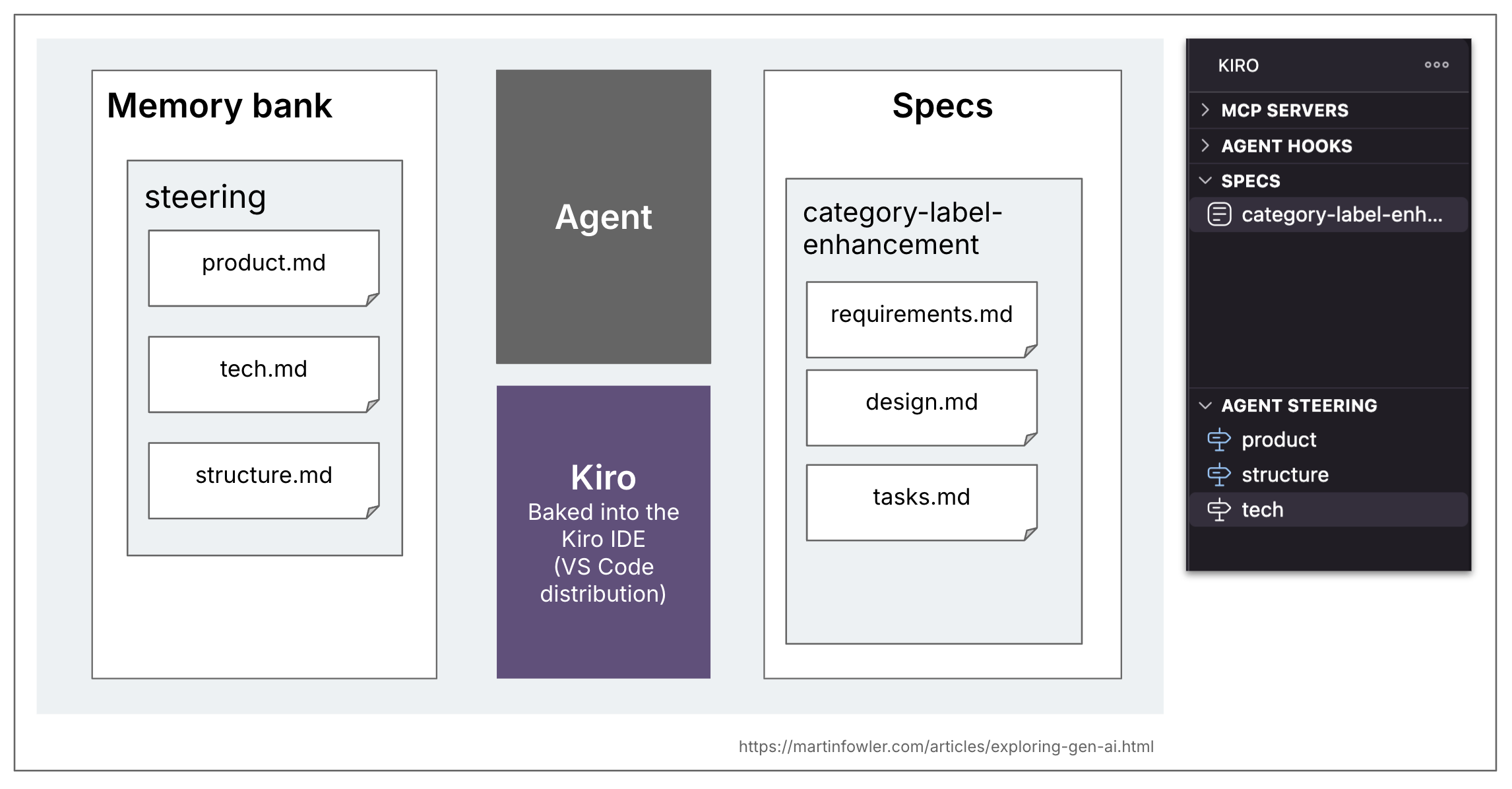
Spec-kit
Spec-kit is GitHub’s model of SDD. It’s distributed as a CLI that may create workspace setups for a variety of frequent coding assistants. As soon as that construction is about up, you work together with spec-kit by way of slash instructions in your coding assistant. As a result of all of its artifacts are put proper into your workspace, that is probably the most customizable one of many three instruments mentioned right here.
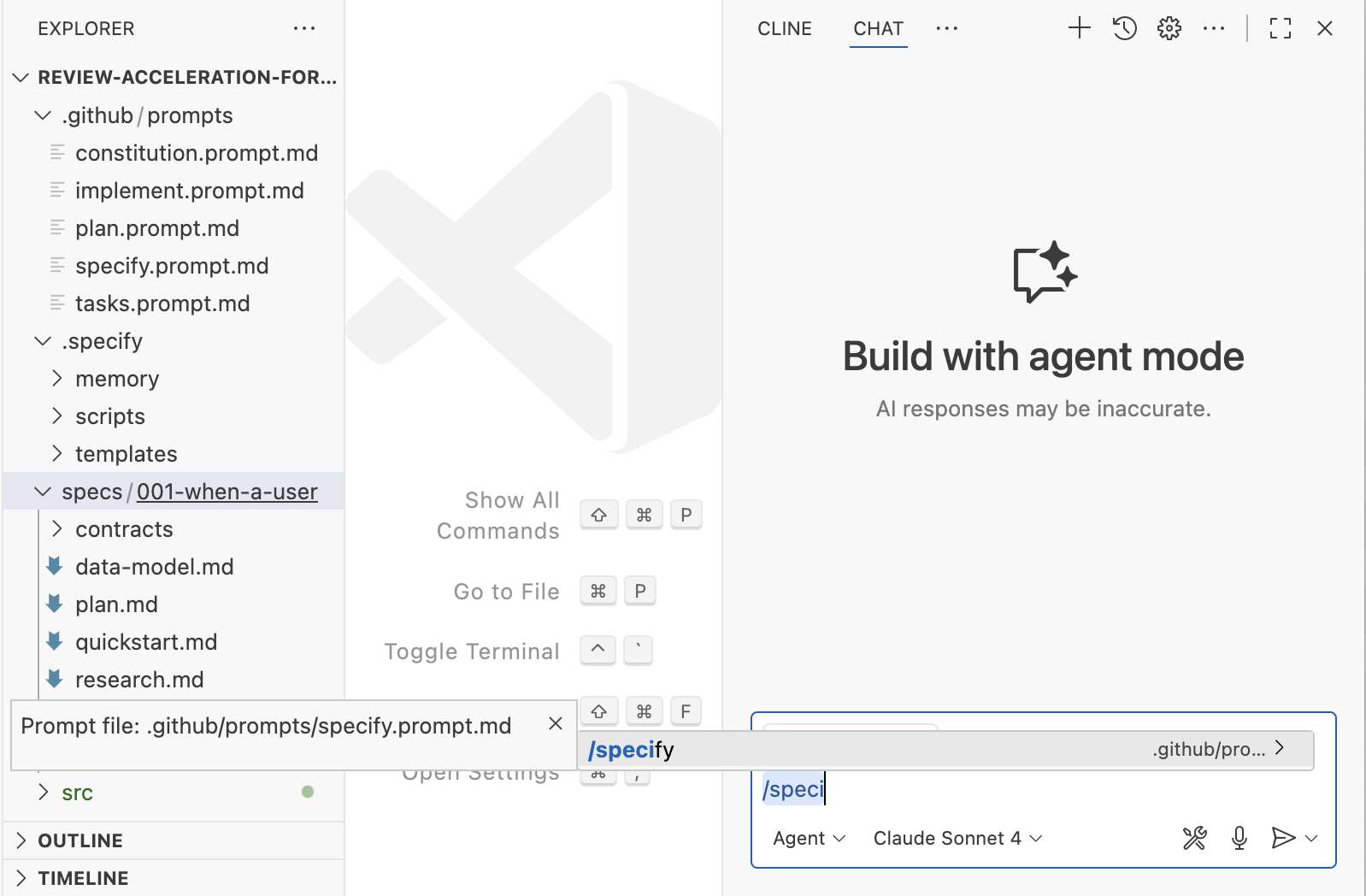
Workflow: Structure → 𝄆 Specify → Plan → Duties 𝄇
Spec-kit’s reminiscence financial institution idea is a prerequisite for the spec-driven method. They name it a structure. The structure is meant to include the excessive degree ideas which are “immutable” and will all the time be utilized, to each change. It’s mainly a really highly effective guidelines file that’s closely utilized by the workflow.
In every of the workflow steps (specify, plan, duties), spec-kit instantiates a set of recordsdata and prompts with the assistance of a bash script and a few templates. The workflow then makes heavy use of checklists within the recordsdata, to trace vital consumer clarifications, structure violations, analysis duties, and many others. They’re like a “definition of carried out” for every workflow step (although interpreted by AI, so there is no such thing as a 100% assure that they are going to be revered).
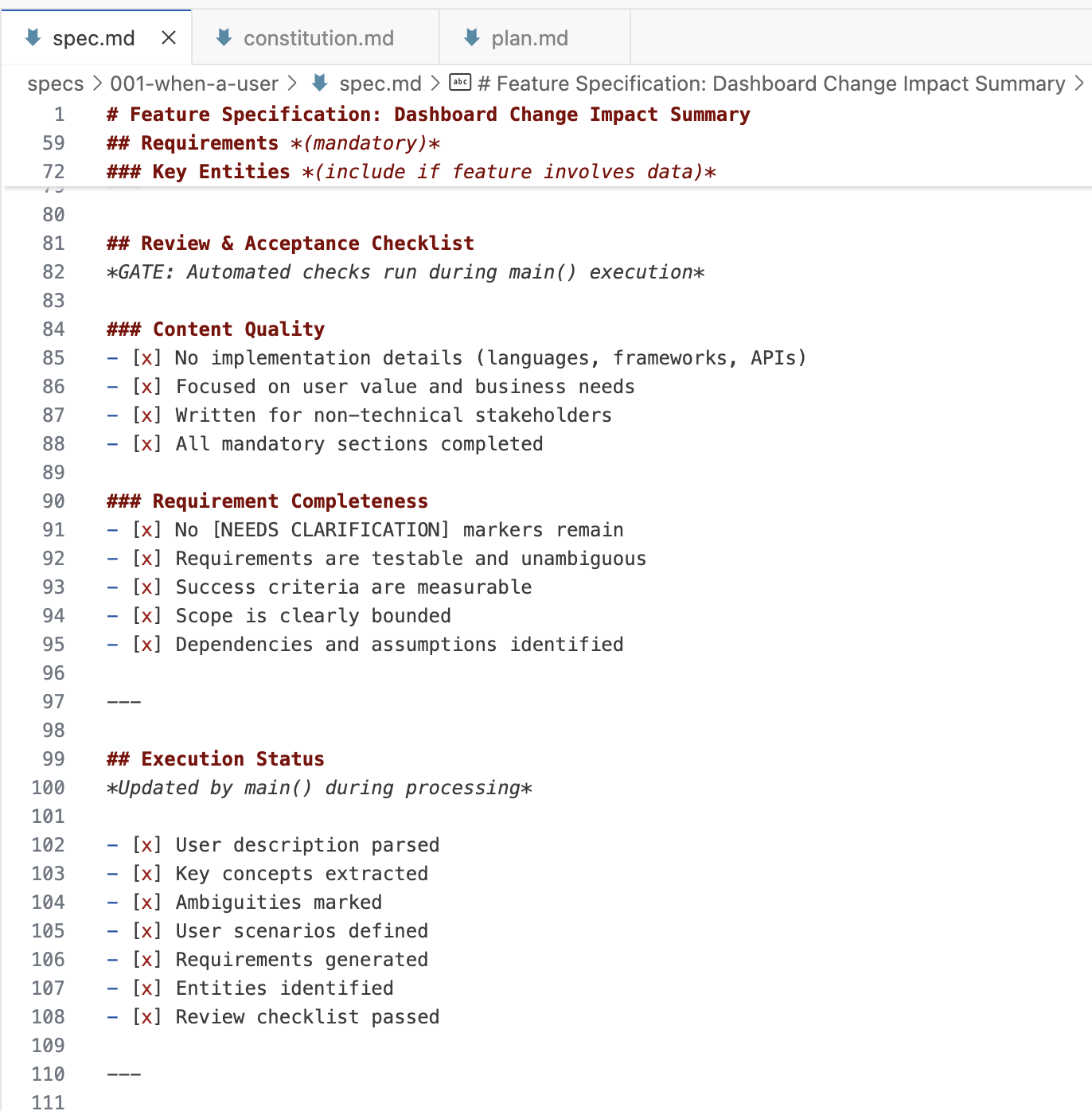
Beneath is an outline as an example the file topology I noticed in spec-kit. Word how one spec is made up of many recordsdata.
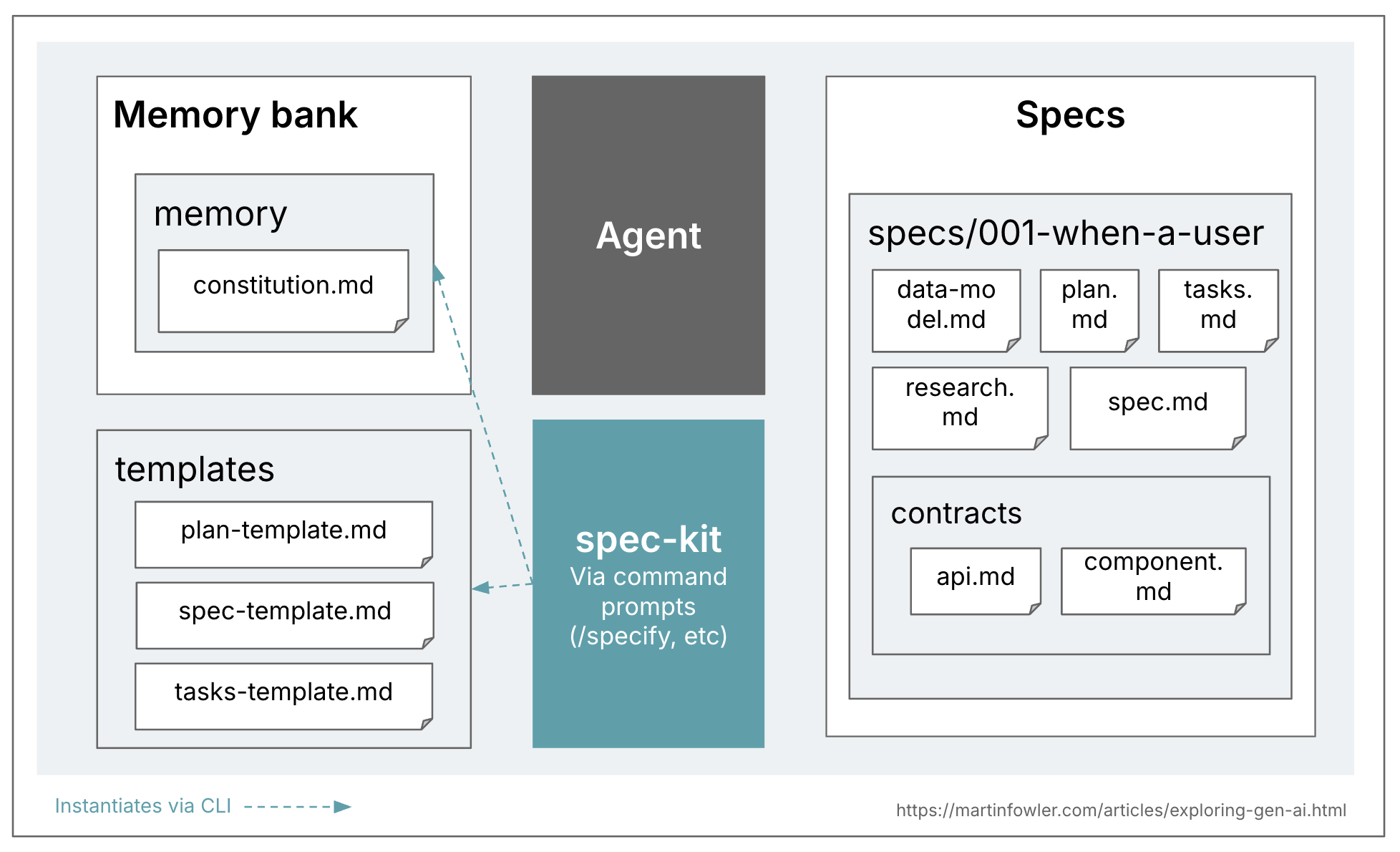
At first look, GitHub appears to be aspiring to a spec-anchored method (“That’s why we’re rethinking specs — not as static paperwork, however as dwelling, executable artifacts that evolve with the venture. Specs develop into the shared supply of fact. When one thing doesn’t make sense, you return to the spec; when a venture grows complicated, you refine it; when duties really feel too giant, you break them down.”) Nonetheless, spec-kit creates a department for each spec that will get created, which appears to point that they see a spec as a dwelling artifact for the lifetime of a change request, not the lifetime of a characteristic. This neighborhood dialogue is speaking about this confusion. It makes me suppose that spec-kit continues to be what I’d name spec-first solely, not spec-anchored over time.
Tessl Framework
(Nonetheless in non-public beta)
Like spec-kit, the Tessl Framework is distributed as a CLI that may create all of the workspace and config construction for quite a lot of coding assistants. The CLI command additionally doubles as an MCP server.
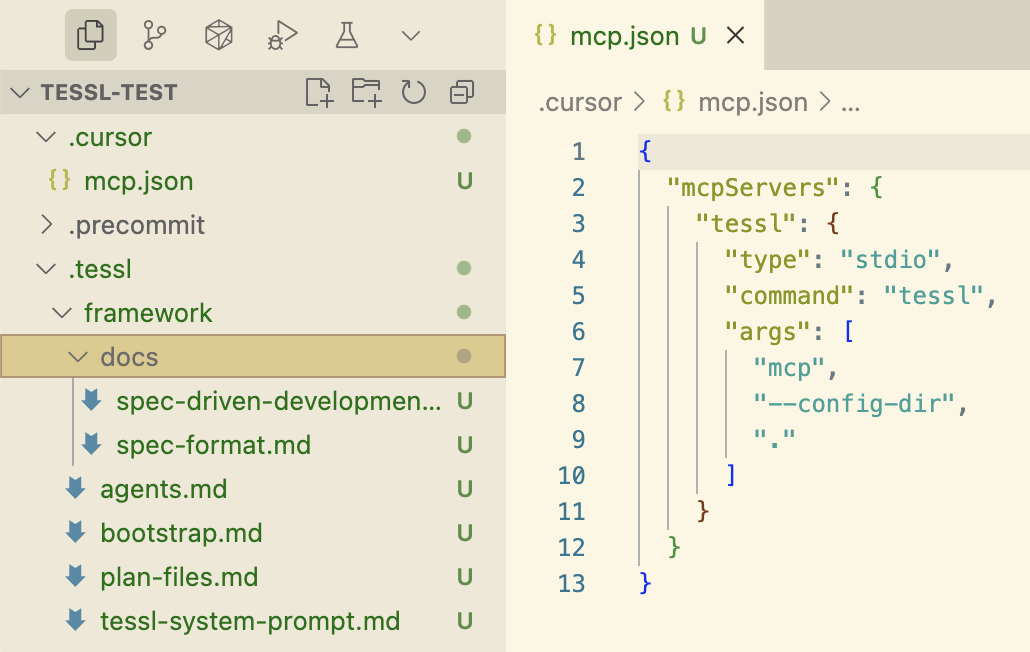
Tessl is the one considered one of these three instruments that explicitly aspires to a spec-anchored method, and is even exploring the spec-as-source degree of SDD. A Tessl spec can function the principle artifact that’s being maintained and edited, with the code even marked with a remark on the prime saying // GENERATED FROM SPEC - DO NOT EDIT. That is at the moment a 1:1 mapping between spec and code recordsdata, i.e. one spec interprets into one file within the codebase. However Tessl continues to be in beta and they’re experimenting with totally different variations of this, so I can think about that this method may be taken on a degree the place one spec maps to a code part with a number of recordsdata. It stays to be seen what the alpha product will assist. (The Tessl crew themselves see their framework as one thing that’s extra sooner or later than their present public product, the Tessl Registry.)
Right here is an instance of a spec that I had the Tessl CLI reverse engineer (tessl doc --code ...js) from a JavaScript file in an current codebase:
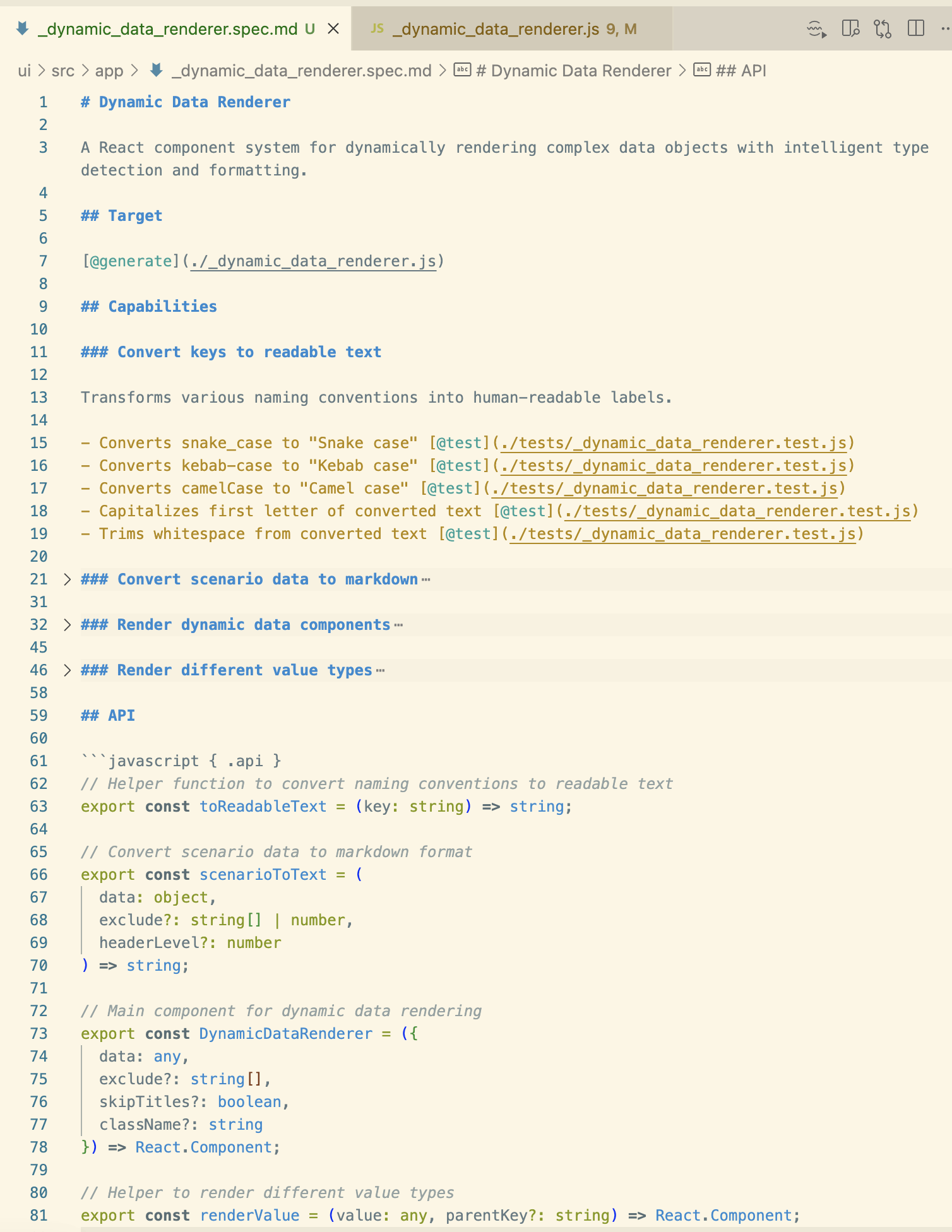
Tags like @generate or @take a look at appear to inform Tessl what to generate. The API part exhibits the concept of defining at the very least the interfaces that get uncovered to different components of the codebase within the spec, presumably to make it possible for these extra essential components of the generated part are totally below the management of the maintainer. Operating tessl construct for this spec generates the corresponding JavaScript code file.
Placing the specs for spec-as-source at a fairly low abstraction degree, per code file, most likely reduces quantity of steps and interpretations the LLM has to do, and subsequently the possibility of errors. Even at this low abstraction degree I’ve seen the non-determinism in motion although, after I generated code a number of instances from the identical spec. It was an attention-grabbing train to iterate on the spec and make it increasingly particular to extend the repeatability of the code technology. That course of jogged my memory of among the pitfalls and challenges of writing an unambiguous and full specification.
Observations and questions
These three instruments are all labelling themselves as implementations of spec-driven growth, however they’re fairly totally different from one another. In order that’s the very first thing to bear in mind when speaking about SDD, it isn’t only one factor.
One workflow to suit all sizes?
Kiro and spec-kit present one opinionated workflow every, however I’m fairly positive that neither of them is appropriate for almost all of actual life coding issues. Specifically, it’s not fairly clear to me how they’d cater to sufficient totally different downside sizes to be typically relevant.
After I requested Kiro to repair a small bug (it was the identical one I used up to now to strive Codex), it shortly grew to become clear that the workflow was like utilizing a sledgehammer to crack a nut. The necessities doc turned this small bug into 4 “consumer tales” with a complete of 16 acceptance standards, together with gems like “Consumer story: As a developer, I would like the transformation operate to deal with edge instances gracefully, in order that the system stays sturdy when new class codecs are launched.”
I had the same problem after I used spec-kit, I wasn’t fairly positive what dimension of downside to make use of it for. Accessible tutorials are often primarily based on creating an software from scratch, as a result of that’s best for a tutorial. One of many use instances I ended up making an attempt was a characteristic that will be a 3-5 level story on considered one of my previous groups. The characteristic trusted plenty of code that was already there, it was supposed to construct an outline modal that summarised a bunch of knowledge from an current dashboard. With the quantity of steps spec-kit took, and the quantity of markdown recordsdata it created for me to assessment, this once more felt like overkill for the scale of the issue. It was a much bigger downside than the one I used with Kiro, but additionally a way more elaborate workflow. I by no means even completed the total implementation, however I believe in the identical time it took me to run and assessment the spec-kit outcomes I may have applied the characteristic with “plain” AI-assisted coding, and I’d have felt way more in management.
An efficient SDD software would on the very least have to offer flexibility for a number of totally different core workflows, for various sizes and forms of adjustments.
Reviewing markdown over reviewing code?
As simply talked about, and as you may see within the description of the software above, spec-kit created a LOT of markdown recordsdata for me to assessment. They have been repetitive, each with one another, and with the code that already existed. Some contained code already. Total they have been simply very verbose and tedious to assessment. In Kiro it was a bit simpler, as you solely get 3 recordsdata, and it’s extra intuitive to grasp the psychological mannequin of “necessities > design > duties”. Nonetheless, as talked about, Kiro additionally was manner too verbose for the small bug I used to be asking it to repair.
To be trustworthy, I’d moderately assessment code than all these markdown recordsdata. An efficient SDD software must present an excellent spec assessment expertise.
False sense of management?
Even with all of those recordsdata and templates and prompts and workflows and checklists, I ceaselessly noticed the agent in the end not observe all of the directions. Sure, the context home windows at the moment are bigger, which is commonly talked about as one of many enablers of spec-driven growth. However simply because the home windows are bigger, doesn’t imply that AI will correctly decide up on every part that’s in there.
For instance: Spec-kit has a analysis step someplace throughout planning, and it did plenty of analysis on the prevailing code and what’s already there, which was nice as a result of I requested it so as to add a characteristic that constructed on prime of current code. However in the end the agent ignored the notes that these have been descriptions of current lessons, it simply took them as a brand new specification and generated them over again, creating duplicates. However I didn’t solely see examples of ignoring directions, I additionally noticed the agent go manner overboard as a result of it was too eagerly following directions (e.g. one of many structure articles).
The previous has proven that the easiest way for us to remain answerable for what we’re constructing are small, iterative steps, so I’m very skeptical that numerous up-front spec design is a good suggestion, particularly when it’s overly verbose. An efficient SDD software must cater to an iterative method, however small work packages nearly appear counter to the concept of SDD.
The right way to successfully separate useful from technical spec?
It’s a frequent thought in SDD to be intentional in regards to the separation between useful spec and technical implementation. The underlying aspiration I assume is that in the end, we may have AI fill in all of the solutioning and particulars, and swap to totally different tech stacks with the identical spec.
In actuality, after I was making an attempt spec-kit, I ceaselessly obtained confused when to remain on the useful degree, and when it was time so as to add technical particulars. The tutorial and documentation additionally weren’t fairly in keeping with it, there appear to be totally different interpretations of what “purely useful” actually means. And after I suppose again on the various, many consumer tales I’ve learn in my profession that weren’t correctly separating necessities from implementation, I don’t suppose we’ve a great observe file as a career to do that properly.
Who’s the goal consumer?
Most of the demos and tutorials for spec-driven growth instruments embrace issues like defining product and have targets, they even incorporate phrases like “consumer story”. The concept right here is perhaps to make use of AI as an enabler for cross-skilling, and have builders take part extra closely in necessities evaluation? Or have builders pair with product folks after they work on this workflow? None of that is made specific although, it’s offered as a given {that a} developer would do all this evaluation.
Wherein case I’d ask myself once more, what downside dimension and kind is SDD meant for? In all probability not for big options which are nonetheless very unclear, as certainly that will require extra specialist product and necessities abilities, and many different steps like analysis and stakeholder involvement?
Spec-anchored and spec-as-source: Are we studying from the previous?
Whereas many individuals draw analogies between SDD and TDD or BDD, I believe one other necessary parallel to take a look at for spec-as-source particularly is MDD (model-driven growth). I labored on a number of tasks originally of my profession that closely used MDD, and I saved being reminded about that after I was making an attempt out the Tessl Framework. The fashions in MDD have been mainly the specs, albeit not in pure language, however expressed in e.g. customized UML or a textual DSL. We constructed customized code mills to show these specs into code.

Finally, MDD by no means took off for enterprise purposes, it sits at a clumsy abstraction degree and simply creates an excessive amount of overhead and constraints. However LLMs take among the overhead and constraints of MDD away, so there’s a new hope that we are able to now lastly deal with writing specs and simply generate code from them. With LLMs, we aren’t constrained by a predefined and parseable spec language anymore, and we don’t need to construct elaborate code mills. The value for that’s LLMs’ non-determinism after all. And the parseable construction additionally had upsides that we’re shedding now: We may present the spec writer with plenty of software assist to put in writing legitimate, full and constant specs. I ponder if spec-as-source, and even spec-anchoring, would possibly find yourself with the downsides of each MDD and LLMs: Inflexibility and non-determinism.
To be clear, I’m not nostalgic about my MDD expertise up to now and saying “we would as properly carry that again”. However we should always look to code-from-spec makes an attempt up to now to study from them after we discover spec-driven at this time.
Conclusions
In my private utilization of AI-assisted coding, I additionally typically spend time on rigorously crafting some type of spec first to provide to the coding agent. So the final precept of spec-first is certainly helpful in lots of conditions, and the totally different approaches of tips on how to construction that spec are very wanted. They’re among the many prime most ceaselessly requested questions I hear in the mean time from practitioners: “How do I construction my reminiscence financial institution?”, “How do I write a great specification and design doc for AI?”.
However the time period “spec-driven growth” isn’t very properly outlined but, and it’s already semantically subtle. I’ve even not too long ago heard folks use “spec” mainly as a synonym for “detailed immediate”.
Concerning the instruments I’ve tried, I’ve listed lots of my questions on their actual world usefulness right here. I ponder if a few of them are attempting to feed AI brokers with our current workflows too actually, in the end amplifying current challenges like assessment overload and hallucinations. Particularly with the extra elaborate approaches that create numerous recordsdata, I can’t assist however consider the German compound phrase “Verschlimmbesserung”: Are we making one thing worse within the try of creating it higher?