Woman dinner began as a joke, however the thought behind it’s completely legitimate: generally the very best dinner is only a bunch of small meals you’re truly excited to eat (and never plated completely prefer it’s designed for Instagram).
Steal my woman dinner routine!
I feel “woman dinner” resonated with me as a result of it validated one thing I already did.
When Ben’s not house, I’m positively extra more likely to eat chips and some slices of the massive block of Sartori BellaVitano stashed within the fridge for dinner than to make a correct meal. (Really, that cheese is one in every of my favourite finds within the hallowed aisles of Costco.)
However, you already understand how to try this form of woman dinner. Open package deal; eat.
So right now, I’m going to share my favourite woman dinners for once I need one thing that feels slightly extra meal-like, however that’s nonetheless low-effort and straightforward to portion for one.
To me, the very best woman dinners steadiness consolation and ease. They’ve additionally received:
One thing crunchy
One thing creamy
Some protein or fiber
A mixture of textures and flavors
That’s why toast dinners work so properly. Or snack plates. Or fast air fryer meals. They’re low-effort however nonetheless satisfying sufficient to really feel like an precise meal.
Cottage Cheese Toast
Creamy cottage cheese with crunchy toasted bread and toppings is easy to make, however nonetheless surprisingly satisfying. (Hat-tip to the cottage cheese for that!)
You’ll see a theme with this assortment of recipes: the air fryer does numerous heavy lifting for my solo meals. It’s sooner and once I’m cooking for one, it means I don’t should make a number of batches. This tofu is an effective way so as to add protein to salads, however I additionally love dipping it in peanut sauce.
The whole lot about this grilled cheese is simply perfection. Generally if I’m feeling fancy, I’ll add caramelized onions, jam, or marmalade for slightly sweet-and-savory distinction.
By the point she was in school, saving cash to order Melanie Mills Glow merchandise from LA, the foundations of her strategy have been already in place: pores and skin first at all times, then coloration positioned the place it might do essentially the most to intensify options. “All the things simply naturally sits right here anyway,” she says. “I practiced on myself first.” She developed the three-step course of for blush: cream to map, powder to set, a last layer of translucent setting powder to construct depth. Her consumer roster speaks for itself: Raye, SZA, Viola Davis, Kelly Rowland, and Adut Akech, to call a number of.
Her affect has reached additional than she might have imagined. She describes watching a video not too long ago of a younger Black girl making use of daring blush and crediting Esther with giving her the arrogance to take action, after years of being instructed the look made her seem clownish. “She totally credited that to me,” Edeme says. “I simply began crying.” The lady within the video had determined she appreciated it and saved doing it no matter what anybody stated. For Edeme, that’s the entire level.
Like Edeme, who moved from Nigeria to the UK when she was youthful, I moved from Ghana to a metropolis within the UK the place my brother and I have been the one Black youngsters within the college. I used to be made to really feel ugly, and I didn’t slot in. After I began educating myself make-up at 17, blush felt like a threat; one thing that might draw consideration to a face I had already been instructed wasn’t ok. I wore it tentatively at first, then with extra conviction. Now, I am proud to be identified for my blush blindness.
Mine is the story of so many Black ladies, which maybe explains why, when the controversy broke, so many people rose as much as defend her. Edeme’s affect on magnificence tradition has given us a lot to guard.
There’s a unusual last stage to affect: when one thing you popularize turns into so well-known that it is larger than you. Edeme is cautious to emphasize that influencers play an essential position in introducing seems to new audiences, however her hope is that the business turns into as fast to have fun the artists who create as it’s to have fun those that unfold. On the finish of the day, recognition is not only a nicety. It is how we ensure the individuals shaping magnificence’s visible language are credited (and, ideally, compensated) for his or her work.
This week, many individuals have posted in assist of Edeme, typically with out mentioning the continued discourse in any respect: Creators have been sharing movies of themselves “attempting Painted by Esther’s iconic blush approach” and MAC Cosmetics printed a shoot that includes Olandria sporting the model’s blush alongside make-up ideas from Edeme. General, Edeme does really feel just like the business, together with mainstream media retailers, have accomplished a good job in giving her her flowers. She provides, nevertheless, with attribute directness: “I feel they may do higher.”
Within the meantime, she’s getting on with it. “My mission earlier than I depart this earth is to unfold my presents,” she says. She describes her objectives for what’s subsequent with the identical unhurried confidence that appears to animate all the things she does: workshops that really feel like a celebration, full with cocktails and a neighborhood of ladies studying collectively and lifting one another up. In time, she’d love a inventive director position at a model.
THE WHAT? Worldwide Paper has damaged floor on a brand new US$225 million corrugated packaging facility in Brandon, Mississippi, as a part of efforts to develop manufacturing capability and strengthen its packaging community throughout the Mid-South area.
THE DETAILS The 468,000-square-foot greenfield plant will likely be constructed on an 80-acre web site within the East Metro Heart industrial park and is positioned close to the corporate’s current Richland field plant. Development is scheduled to start in June 2026, with operations anticipated to start out within the fourth quarter of 2027. Staff from the present Richland facility are anticipated to transition to the brand new web site as soon as accomplished. Worldwide Paper stated the power will incorporate superior automation, manufacturing security programs and operational effectivity applied sciences designed to enhance reliability, product high quality and value efficiency. The undertaking can also be anticipated to create 150 manufacturing jobs and strengthen provide chain connectivity by way of partnerships together with rail operator CPKC.
THE WHY? The funding helps Worldwide Paper’s technique to modernize its manufacturing community, enhance operational effectivity and sustainability efficiency, and strengthen customer support capabilities throughout key packaging markets in North America.
London — Developer Safety Enablement Platform supplier SecureFlag, a pacesetter in safe coding coaching, launched its AI-Assisted Growth Labs, a brand new hands-on coaching resolution designed to assist builders safely combine AI coding assistants into their workflows.
AI-powered coding instruments reminiscent of GitHub Copilot, Claude, and ChatGPT are quickly remodeling how software program is constructed, with over 80% of builders worldwide utilizing AI instruments of their work in accordance with the Stack Overflow 2025 Developer Survey. Cybersecurity stories discovered that as much as 45% of AI-generated code comprises safety vulnerabilities, together with context-specific dangers and the replication of insecure patterns. As AI produces extra code than a developer can realistically assessment manually, vulnerabilities can multiply throughout an increasing assault floor.
SecureFlag’s AI-Assisted Growth Labs immediately tackle these dangers by coaching builders to critically assess AI outputs and apply safe coding practices all through the software program growth lifecycle. Targeted on real-world situations and instruments already utilized by growth groups, the important thing studying outcomes embrace:
Producing safe code when prompting and guiding AI assistants
Reviewing and validating AI-generated code to determine safety points
Integrating AI assistants into the SDLC, enabling interplay with safety instruments reminiscent of Static Software Safety Testing (SAST) scanners for vulnerability remediation
Constructing safe automations, together with customized abilities, brokers, and Mannequin Context Protocol (MCP) integrations
“Builders are now not simply writing code—they’re directing AI techniques. Our new labs guarantee they’ll achieve this with safety on the forefront,” mentioned Emilio Pinna, CTO at SecureFlag.
The launch of AI-Assisted Growth Labs builds on SecureFlag’s established strategy to hands-on, developer-focused coaching based mostly on real looking assault situations. As organizations proceed to undertake AI-driven growth, the corporate goals to make sure that safety stays a core consideration.
The primary labs are actually out there with new content material already on the way in which. To be taught extra or request a demo of the AI-Assisted Growth Labs, go to secureflag.com
Fashionable knowledge pipelines deal with large volumes of structured and unstructured knowledge daily. As datasets develop, poorly optimized Spark jobs develop into slower, costlier, and more durable to scale. Frequent points embody lengthy execution occasions, extreme shuffling, reminiscence bottlenecks, and inefficient joins.
Efficient PySpark optimization can considerably enhance efficiency, cut back infrastructure prices, and improve cluster effectivity. On this article, we’ll discover 12 confirmed PySpark optimization methods with sensible examples and real-world efficiency methods utilized by knowledge engineers.
How Spark Executes Your Code
It’s good to learn the way Spark executes your code earlier than you begin your optimization work. Builders write PySpark code with out understanding the underlying processes which energy their code. The absence of data ends in suboptimal efficiency selections. The core mechanics of this part allow readers to grasp each optimization approach which follows.
Understanding Spark Structure
Spark operates its distributed system which permits simultaneous knowledge processing throughout varied computer systems. Each Spark utility consists of two major elements which function in unison.
Driver vs Executors
The Driver serves because the central command system in your Spark utility. It executes your major program whereas growing the execution technique and supervising all operational actions. The Executors perform because the operational workers. The cluster distributes these staff to varied machines which retailer knowledge in reminiscence whereas conducting precise computational duties.
The Driver divides the work into smaller duties which it dispatches to Executors once you submit a Spark job. Every Executor operates on its designated knowledge section with none dependencies on different techniques. The mix of parallel processing strategies permits Spark to ship high-speed efficiency.
Jobs, Phases, and Duties
Spark organizes your computation work into three hierarchical layers.
Job: A whole computation triggered by an motion (like depend() or write()).
Stage: A set of duties that may run with out shuffling knowledge throughout the community.
Job: The smallest unit of labor. Every activity processes one partition of knowledge.
You could find efficiency issues within the Spark UI by utilizing this hierarchical construction to find varied system elements.
Lazy Analysis in Spark
The Spark framework is not going to execute your transformations for the time being you create them. The system information your meant actions once you use the filter() and choose() and groupBy() capabilities. The system creates a logical construction to characterize your meant actions. The system requires you to carry out an motion which incorporates present() and depend() and write() to provoke the execution course of.
Lazy analysis describes this sample of operation. The system permits Spark to design a whole question plan which it would execute in spite of everything planning is completed. Earlier than any work begins Spark can change the order of duties and transfer knowledge supply filters nearer and take away unneeded elements.
Understanding Spark Transformations and Actions
All PySpark operations fall into two classes.
Transformations: Transformations create new DataFrames by means of their execution of lazy operations. The capabilities filter(), choose(), be part of(), groupBy(), and withColumn() create new DataFrames by means of their execution of lazy operations. Spark information these however doesn’t run them but.
Actions: Precise execution begins when actions are carried out. The capabilities depend(), gather(), present(), write(), and first() function examples of this conduct. Once you name an motion, Spark evaluates all of the queued transformations and runs the job.
A typical mistake happens when folks execute a number of actions on the identical DataFrame without having them. The system executes all transformations once more for each motion except you employ knowledge caching.
Studying Spark Execution Plans with clarify()
The clarify() methodology is your debugging instrument. The system shows its full question execution plan by means of this characteristic. The system permits you to observe two points of the operation as a result of it reveals filter pushdown outcomes and broadcast be part of utilization and shuffle operation particulars.
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("ExplainDemo").getOrCreate()
df = spark.learn.parquet("/knowledge/gross sales.parquet")
df_filtered = df.filter(df["revenue"] > 5000).choose("product", "income")
# Learn the execution plan
df_filtered.clarify(True)
You’ll be able to see PushedFilters current within the output. The filter applies on the file degree which serves as a wonderful efficiency indicator.
Methods to Optimise Your Spark Fashions
Now, we’ll undergo the methods that may assist to optimize your spark fashions.
Approach 1: Use Columnar File Codecs Like Parquet or ORC
The file format you choose ends in vital results on Spark’s skill to learn knowledge. Groups desire CSV and JSON as their customary codecs as a result of these codecs require minimal effort to provide. The usage of these codecs causes main efficiency points when operations attain their most limits.
Why CSV and JSON Are Slower
CSV and JSON are row-based codecs. To learn a single column, Spark should learn each row and parse all columns. This wastes I/O and CPU time. Additionally they don’t have any built-in schema, so Spark should infer it which provides further overhead.
Advantages of Parquet and ORC
Parquet and ORC perform as column-based knowledge codecs which help analytical operations. The system organizes knowledge storage in line with columns as a substitute of storing knowledge in line with rows.
Columnar Storage: Columnar Storage permits Spark to entry solely the precise columns which you require. Once you select 3 columns from a dataset containing 50 columns Spark will exclude 47 columns from the processing.
Compression Advantages: Columnar codecs obtain superior knowledge compression outcomes by utilizing their columnar storage construction. The compression course of works successfully as a result of related values inside a single column preserve proximity. The system achieves storage price reductions whereas accelerating studying occasions.
Predicate Pushdown: Parquet and ORC preserve statistical info (minimal and most values and null counts) for each column throughout all row teams. Spark makes use of these statistics to skip whole chunks of knowledge with out studying them.
Use Parquet for analytical workloads and pipelines.
Use ORC when working with Hive or HBase ecosystems.
At all times write with Snappy compression for steadiness of velocity and measurement.
Keep away from CSV and JSON for intermediate storage between pipeline steps.
Approach 2: Filter Knowledge as Early as Attainable
The only and best PySpark optimization methodology includes performing early knowledge filtering. The velocity of your whole system improves when Spark processes a smaller quantity of knowledge all through your whole pipeline.
What Is Predicate Pushdown?
A predicate is a filter situation that features each age > 30 and standing == "energetic". Predicate pushdown means Spark strikes these filter circumstances as near the info supply as doable, ideally into the file scan itself. Spark performs its studying course of by making use of filters as a substitute of retrieving all knowledge for subsequent filtering.
Why Early Filtering Improves Efficiency
The operation of filtering earlier than processing permits all subsequent duties to work with a smaller knowledge set which incorporates joins and aggregations and types. The method ends in decreased reminiscence necessities and decreased community calls for and shorter CPU processing occasions for every stage of your mission.
The system operates by means of its checking course of which executes after the becoming a member of operation.
The method must execute knowledge assortment by means of gather() which brings knowledge to Python earlier than customers begin their knowledge filtering work by means of Python loops.
The system permits for filters on calculated columns when customers ought to first apply filters on authentic supply columns.
Approach 3: Choose Solely Required Columns
Studying pointless columns wastes I/O time and reminiscence. Many builders write choose("*") out of behavior however this observe causes your Spark jobs to endure efficiency issues when working on broad datasets.
The Downside with Vast DataFrames
A large DataFrame has many columns which may attain tons of in precise knowledge warehouse environments. The 200 columns should be loaded as a result of your evaluation wants to make use of solely 5 of them.
Why choose(“*”) Hurts Efficiency
choose("*") forces Spark to learn all columns whereas it processes your job by means of its completely different phases. Spark can remove whole columns from its processing once you select particular knowledge parts by means of columnar codecs comparable to Parquet.
Column Pruning in Spark
Column pruning is the method of eliminating unused columns from the question plan. Spark’s Catalyst optimizer performs column pruning routinely once you use express choose() statements. The system utterly avoids studying these columns from the supply.
The Catalyst optimizer of Spark routinely removes columns from its bodily plan development course of. The system tracks wanted columns for complicated queries whereas eliminating unneeded ones by means of its tracing mechanism. The usage of express choose() statements permits Catalyst to carry out its activity with better precision.
Approach 4: Optimize Partitioning
Partitioning is without doubt one of the most impactful areas of PySpark efficiency. Getting your partition technique flawed could make even easy jobs run slowly.
Understanding Spark Partitions
A partition capabilities as a DataFrame part which stays accessible by means of one executor. Spark conducts simultaneous processing of every DataFrame partition. The system achieves elevated processing capability by means of extra partitions but extreme tiny partitions end in processing delays. Your cluster capabilities at under its most capability as a result of you’ve created excessively giant partitions.
Default Partitioning Conduct
Spark establishes knowledge partitions from file enter based mostly on the variety of enter splits. HDFS and S3 techniques create one partition for every file block. Spark creates 200 partitions for shuffle operations which embody groupBy and be part of operations as a result of spark.sql.shuffle.partitions controls this default setting.
The usage of 200 shuffle partitions exceeds necessities for small datasets as a result of it ends in extreme tiny duties. The 200 partition depend won’t adequately deal with very giant datasets.
How Partitions Have an effect on Parallelism
Spark permits execution of 1 activity for every partition which makes use of one core of the system. Spark begins 20 duties concurrently throughout 10 execution phases when your cluster has 20 cores and your system has 200 partitions. The system requires 10 cores to function since you created 10 partitions. The usual advice suggests utilizing 2 to 4 partitions for every CPU core current inside your cluster.
repartition() vs coalesce()
The 2 strategies each alter partition counts but their operational processes differ from one another.
repartition(n): The perform repartition(n) redistributes knowledge by means of a whole network-based shuffle operation. It’s best to use it once you wish to create extra partitions or once you require equal-sized partitions. The method incurs excessive prices as a result of it transmits knowledge by means of the community system.
coalesce(n): The perform coalesce(n) achieves partition discount by means of non-disruptive partition motion. The perform permits partition merging on executors when two partitions exist. It’s best to use it to lower partitions (for instance, earlier than writing output). The answer prices much less cash to implement but it produces partition sizes which don’t attain equal distribution.
PySpark Code Instance
from pyspark.sql import SparkSession
spark = (
SparkSession.builder
.appName("PartitionDemo")
.config("spark.sql.shuffle.partitions", "10")
.getOrCreate()
)
# Create dummy transaction knowledge
knowledge = [
(
i,
f"TXN{i:05d}",
float(i * 15.5),
"completed" if i % 3 != 0 else "failed"
)
for i in range(1, 101)
]
schema = ["txn_id", "txn_ref", "amount", "status"]
df = spark.createDataFrame(knowledge, schema)
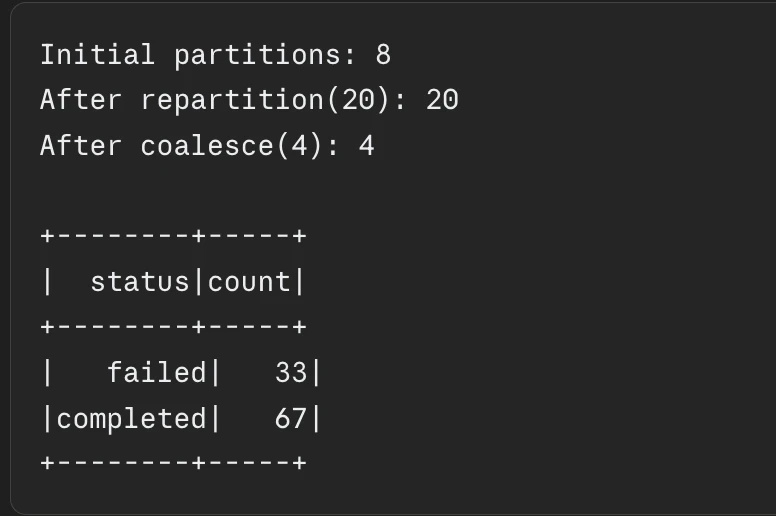
print(f"Preliminary partitions: {df.rdd.getNumPartitions()}")
# Enhance partitions for parallel processing
df_repartitioned = df.repartition(20)
print(
f"After repartition(20): "
f"{df_repartitioned.rdd.getNumPartitions()}"
)
# Scale back partitions earlier than writing output
df_coalesced = df_repartitioned.coalesce(4)
print(
f"After coalesce(4): "
f"{df_coalesced.rdd.getNumPartitions()}"
)
# Repartition by a column for be part of optimization
df_by_status = df.repartition(10, "standing")
df_by_status.groupBy("standing").depend().present()
Output:
Approach 5: Use Broadcast Joins for Small Tables
Probably the most resource-intensive operations in Spark techniques develop into their most costly operations as a result of they should transfer knowledge between completely different community places. A broadcast be part of permits you to take away the necessity for knowledge motion when one desk stays small.
Why Spark Joins Are Costly
The usual Spark be part of requires Each DataFrames to have matching keys on the identical executor. The Spark system achieves this end result by transferring knowledge by means of the community which strikes machine rows till their matching keys attain the right location. The method of community knowledge switch incurs each excessive bills and prolonged time delays.
What Is a Broadcast Be part of?
In a broadcast be part of, Spark sends a full copy of the small desk to each executor. The executors use their native giant desk partitions to carry out the be part of without having to shuffle knowledge between them. This method ends in a considerable lower of execution time.
When to Use Broadcast Joins
It’s best to use a broadcast be part of when one desk exists which will be totally saved within the reminiscence of every executor. Spark routinely broadcasts tables smaller than spark.sql.autoBroadcastJoinThreshold (default 10 MB). You’ll be able to manually broadcast bigger tables in case your executors have sufficient reminiscence.
When Spark sees broadcast(merchandise), it ships your entire merchandise desk to each executor upfront. Every executor retains the desk of their reminiscence storage. The be part of course of runs on each executor which manages its personal orders partition by matching rows with none community knowledge transmission. The end result produces a be part of course of that completes at a velocity which exceeds regular efficiency.
The introduction of Adaptive Question Execution (AQE) in Spark model 3.0 introduced probably the most vital efficiency increase to Spark between its current time and its final main replace. The system permits Spark to change your question optimizations throughout execution by utilizing actual knowledge metrics which it obtains by means of runtime operations.
What Is AQE in Spark?
Spark used to create a whole execution plan which it will comply with all through your entire course of with out making any changes based mostly on precise knowledge. The implementation of AQE permits this performance. The characteristic permits Spark to evaluate execution efficiency by means of precise knowledge evaluation which it obtains from every shuffle interval.
Runtime Question Optimization with AQE
The system consists of three major capabilities which begin working instantly after customers activate the system.
Dynamic Be part of Technique Choice: The system permits AQE to vary its execution methodology from sort-merge be part of to broadcast be part of throughout runtime. Spark routinely sends one aspect of a be part of to all nodes when it detects that the be part of’s measurement shall be smaller than predicted after a shuffle operation. This method prevents a whole shuffle operation when the desk exceeds the published measurement restrict which base on file dimensions.
Skew Be part of Optimization: Uneven knowledge distribution creates knowledge skew as a result of some partitions obtain greater knowledge volumes than different partitions. This case results in one or two sluggish duties which forestall your entire job from progressing. The system makes use of AQE to search out runtime skewed partitions which it then divides into smaller elements for higher distribution of duties.
Submit-Shuffle Partition Coalescing: The system permits AQE to mix a number of low quantity shuffle partitions into one bigger partition after finishing the shuffle operation. This course of eliminates the requirement for a number of small duties which carry out minimal capabilities due to their low execution quantity.
PySpark Code Instance
from pyspark.sql import SparkSession
spark = (
SparkSession.builder
.appName("AQEDemo")
.config("spark.sql.adaptive.enabled", "true")
.config("spark.sql.adaptive.coalescePartitions.enabled", "true")
.config("spark.sql.adaptive.skewJoin.enabled", "true")
.config("spark.sql.adaptive.localShuffleReader.enabled", "true")
.getOrCreate()
)
# Dummy gross sales transactions
sales_data = [
(
i,
f"CUST_{i % 50:03d}",
f"PROD_{i % 20:03d}",
float(i * 10.5)
)
for i in range(1, 201)
]
gross sales = spark.createDataFrame(
sales_data,
["sale_id", "customer_id", "product_id", "revenue"]
)
# Dummy product catalog
catalog_data = [
(
f"PROD_{i:03d}",
f"Product {i}",
"Category A" if i % 2 == 0 else "Category B"
)
for i in range(20)
]
catalog = spark.createDataFrame(
catalog_data,
["product_id", "product_name", "category"]
)
# AQE will optimize this be part of dynamically at runtime
end result = (
gross sales.be part of(catalog, on="product_id")
.groupBy("class")
.agg({"income": "sum"})
)
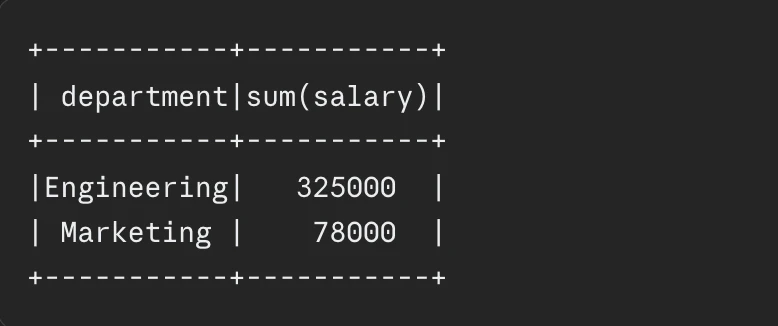
end result.present()
Output:
The implementation of AQE offers organizations with a bonus which requires minimal effort to attain. The system ought to be activated for all Spark model 3.x operations aside from circumstances which require particular exception dealing with.
Approach 7: Keep away from Python UDFs Every time Attainable
The Python Person Outlined Capabilities UDFs create probably the most frequent efficiency issues in PySpark as a result of they introduce sudden delays. Python builders discover it straightforward to make use of these capabilities however their utilization ends in vital efficiency degradation.
Why Python UDFs Sluggish Down Spark
Spark operates instantly on the Java Digital Machine which serves as its elementary execution platform. Python operates exterior the Java Digital Machine setting. Spark must execute a number of steps once you use a Python UDF as a result of it should convert knowledge from the JVM to Python, execute the perform, after which ship again the outcomes to the JVM. The system handles communication between elements by processing one row at a time.
Serialization Overhead
The system wants to rework each knowledge row from Spark’s inner binary format into Python objects for processing earlier than it could create the Python objects. The method of serialization and deserialization incurs excessive prices as a result of it must deal with hundreds of thousands of rows.
JVM-to-Python Communication Value
The system creates an unbiased Python course of for every executor in Spark. The JVM and Python processes change knowledge by means of a community socket. When working at scale, this communication bottleneck causes Python UDFs to carry out 10 occasions slower than equal native Spark capabilities.
Favor Native Spark Capabilities
The capabilities from pyspark.sql.capabilities execute utterly inside the JVM setting which eliminates the necessity for Python knowledge conversion. The system achieves quicker execution speeds by means of compiled and optimized capabilities that outperform customized Python UDFs.
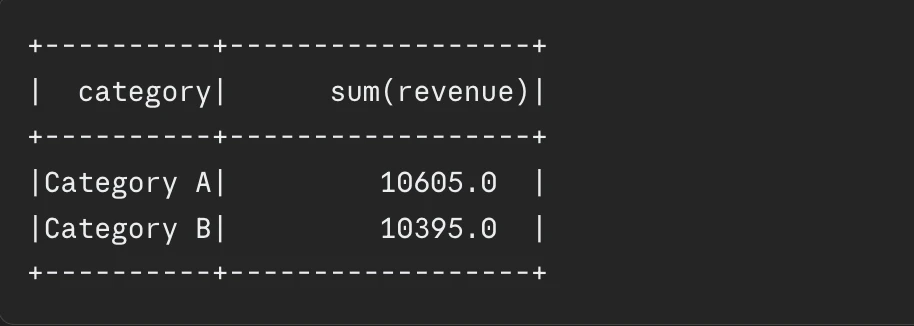
Spark form of recomputes your DataFrame from scratch each time you hit an motion on it. So should you do depend() after which, later present() on the “similar” DataFrame, Spark finally ends up working the entire pipeline twice. Caching helps, however provided that you really use it with a little bit of sense, not simply because it exists.
Understanding Spark Caching
Principally, caching means oncethe DataFrame will get computed the primary time, Spark shops the end in reminiscence (or disk). Then for the following motion, Spark can learn these saved rows and skip the recomputation from the unique sources.
When to Use cache()
It’s best to cache a DataFrame when stuff like that is true:
You find yourself reusing the identical DataFrame greater than as soon as in your workflow.
The DataFrame is dear to construct (suppose a number of joins , heavy aggregations , or numerous file reads).
It could actually comfortably match contained in the reminiscence accessible on the executors.
When Caching Can Damage Efficiency
In the event you cache a DataFrame that you just contact solely as soon as, you pay some overhead for nothing. And caching large DataFrames that don’t actually slot in reminiscence can result in spill to disk , which may find yourself slower than simply recomputing. So it’s price checking if caching helps in your state of affairs.
cache() vs persist()
cache() all the time shops the DataFrame in reminiscence in a deserialized kind. persist() offers you choices , like reminiscence solely, reminiscence + disk, disk solely, or serialized in-memory. In circumstances the place you want extra management over storage conduct, persist() is normally the higher selection.
PySpark Code Instance
from pyspark.sql import SparkSession
from pyspark.sql.capabilities import (
col,
sum as spark_sum,
avg
)
spark = (
SparkSession.builder
.appName("CachingDemo")
.getOrCreate()
)
# Dummy retail knowledge
knowledge = [
("2024-01", "Electronics", "Laptop", 1200.00, 30),
("2024-01", "Furniture", "Chair", 200.00, 50),
("2024-02", "Electronics", "Phone", 800.00, 75),
("2024-02", "Electronics", "Monitor", 450.00, 40),
("2024-03", "Furniture", "Desk", 350.00, 20),
("2024-03", "Electronics", "Tablet", 600.00, 25),
("2024-04", "Furniture", "Lamp", 60.00, 60),
("2024-04", "Electronics", "Keyboard", 80.00, 100),
]
schema = [
"month",
"category",
"product",
"price",
"units"
]
df = spark.createDataFrame(knowledge, schema)
# Compute income as soon as
df_revenue = df.withColumn(
"income",
col("worth") * col("models")
)
# Cache as a result of we use df_revenue a number of occasions
df_revenue.cache()
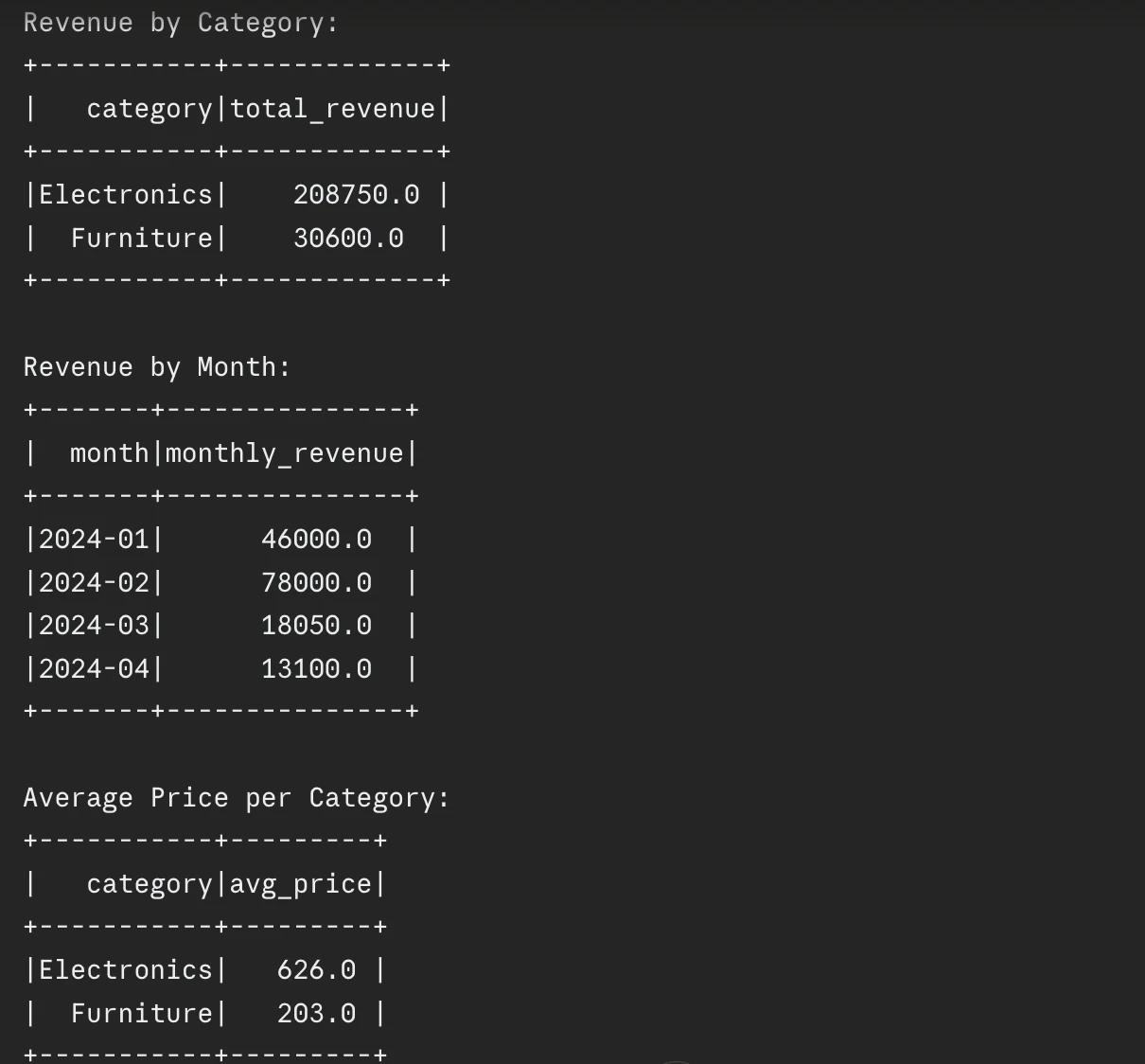
# Motion 1: Income by class
print("Income by Class:")
df_revenue.groupBy("class").agg(
spark_sum("income").alias("total_revenue")
).present()
# Motion 2: Income by month
print("Income by Month:")
df_revenue.groupBy("month").agg(
spark_sum("income").alias("monthly_revenue")
).present()
# Motion 3: Common unit worth
print("Common Worth per Class:")
df_revenue.groupBy("class").agg(
avg("worth").alias("avg_price")
).present()
# At all times unpersist when executed
df_revenue.unpersist()
Output:
Eradicating Cached DataFrames
It’s good to use unpersist() after you end working with a cached DataFrame. Cached DataFrames preserve their reminiscence utilization till both the Spark session terminates otherwise you select to free them. Extreme caching of DataFrames will result in reminiscence strain which leads to spilling.
Approach 9: Deal with Knowledge Skew Effectively
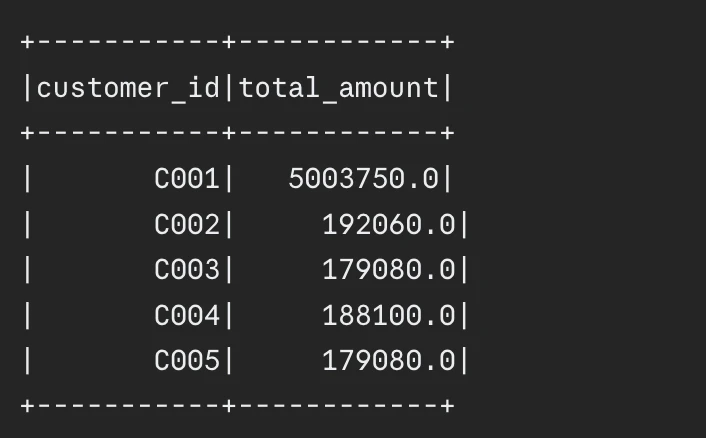
Skewed knowledge distribution creates one of the vital troublesome efficiency challenges for Spark techniques. The system operates with out detection as a result of it creates prolonged activity execution occasions for particular duties which ends up in delayed job completion till the sluggish duties full their execution.
What Is Knowledge Skew?
Knowledge skew happens when some partitions include way more knowledge than others. A buyer orders dataset reveals that one main buyer has 10 million orders whereas all different clients common 1,000 orders every. The shopper ID grouping operation in Spark creates one partition which incorporates extreme knowledge.
Signs of Skewed Spark Jobs
Your job has reached 95% completion but it surely experiences a delay through the remaining duties. The state of affairs shows basic skew conduct. Most duties full their operations rapidly whereas a small variety of duties with heavy workloads create delays for your entire system.
Detecting Skew Utilizing Spark UI
It’s best to entry the Spark UI to look at the Phases tab. The duty metrics develop into accessible when you choose a sluggish stage for evaluation. Knowledge skew exists when some duties present greater values for “Enter Dimension” and “Shuffle Learn” and “Period” than their median values.
Methods to Repair Knowledge Skew
Salting: The method requires including a random prefix that ranges from 0 to N to the skewed key. This generates N smaller partitions which is able to end result from processing the heavy partition. The salt ought to be deleted after the aggregation course of, and the outcomes ought to be mixed.
AQE Skew Be part of: Spark will routinely handle the method once you allow the setting spark.sql.adaptive.skewJoin.enabled.
Broadcast be part of: The system will broadcast the smaller be part of aspect when its measurement falls under the edge as a result of this methodology permits full operation without having a shuffle.
Repartitioning: The system wants handbook repartitioning as a result of it requires higher distribution by means of particular column repartitioning.
PySpark Code Instance
from pyspark.sql import SparkSession
from pyspark.sql.capabilities import (
col,
rand,
flooring,
concat,
lit,
sum as spark_sum
)
spark = (
SparkSession.builder
.appName("SkewDemo")
.config("spark.sql.adaptive.skewJoin.enabled", "true")
.getOrCreate()
)
# Skewed knowledge:
# buyer C001 has 80% of all orders
orders_data = (
[
(i, "C001", float(i * 12.5))
for i in range(1, 801)
] +
[
(
i + 800,
f"C{str(i % 10 + 2).zfill(3)}",
float(i * 9.9)
)
for i in range(1, 201)
]
)
orders = spark.createDataFrame(
orders_data,
["order_id", "customer_id", "amount"]
)
# Salting approach to repair skew manually
num_salts = 5
# Add salt to orders
orders_salted = orders.withColumn(
"salted_key",
concat(
col("customer_id"),
lit("_"),
(flooring(rand() * num_salts)).forged("string")
)
)
# Mixture with salted key
agg_salted = (
orders_salted
.groupBy("salted_key", "customer_id")
.agg(
spark_sum("quantity").alias("partial_sum")
)
)
# Remaining aggregation
# take away salt and sum partial outcomes
end result = (
agg_salted
.groupBy("customer_id")
.agg(
spark_sum("partial_sum").alias("total_amount")
)
)
end result.orderBy(
"total_amount",
ascending=False
).present(5)
Output:
Actual-World Skew Optimization Instance
Knowledge skew develops throughout actual pipelines when customers be part of on energetic person IDs and high product IDs and optionally available international keys which include default null values. At all times examine your be part of key distributions earlier than writing your pipeline. The tactic to examine for skew in knowledge makes use of groupBy("join_key").depend().orderBy("depend", ascending=False).present(10) to point out outcomes.
Approach 10: Reduce Shuffle Operations
The costliest operation in Spark processing refers to shuffles as a result of these operations require community knowledge transfers between executors. The best optimization in your system happens by means of the method of lowering shuffle operations.
Why Shuffles Are Costly
All rows should endure serialization earlier than Spark can course of them through the shuffle operation as a result of the system must retailer them on disk and ship them to the suitable executor after which convert them again into their authentic format. The system operates all three elements collectively which embody disk I/O and community I/O and CPU processing. The length of shuffles on in depth datasets can lengthen from a number of minutes to a number of hours.
Operations That Set off Shuffles
The next widespread operations in Spark create shuffles:
groupBy(): The operation teams knowledge based mostly on key values. The community switch course of turns into mandatory as a result of all rows sharing the identical key should be processed on a single executor.
be part of(): The operation performs a be part of between two DataFrames based mostly on matching keys. The be part of key partitioning requires each DataFrames to endure shuffling operations on one or each DataFrame sides.
distinct(): The operation eliminates all duplicate rows by means of your entire dataset. The operation requires all duplicate row situations to assemble at a single location.
orderBy(): The operation types all knowledge throughout each partition. The operation performs a world type which routinely creates a shuffle course of.
PySpark Code Instance
from pyspark.sql import SparkSession
from pyspark.sql.capabilities import (
col,
sum as spark_sum,
countDistinct
)
spark = (
SparkSession.builder
.appName("ShuffleDemo")
.config("spark.sql.shuffle.partitions", "8")
.getOrCreate()
)
knowledge = [
("2024-Q1", "North", "Electronics", "Laptop", 1200.00, 30),
("2024-Q1", "South", "Electronics", "Phone", 800.00, 75),
("2024-Q2", "North", "Furniture", "Chair", 200.00, 50),
("2024-Q2", "East", "Electronics", "Monitor", 450.00, 40),
("2024-Q3", "West", "Electronics", "Tablet", 600.00, 25),
("2024-Q3", "North", "Furniture", "Desk", 350.00, 20),
("2024-Q4", "South", "Electronics", "Keyboard", 80.00, 100),
("2024-Q4", "East", "Furniture", "Lamp", 60.00, 60),
]
schema = [
"quarter",
"region",
"category",
"product",
"price",
"units"
]
df = spark.createDataFrame(knowledge, schema)
df = df.withColumn(
"income",
col("worth") * col("models")
)
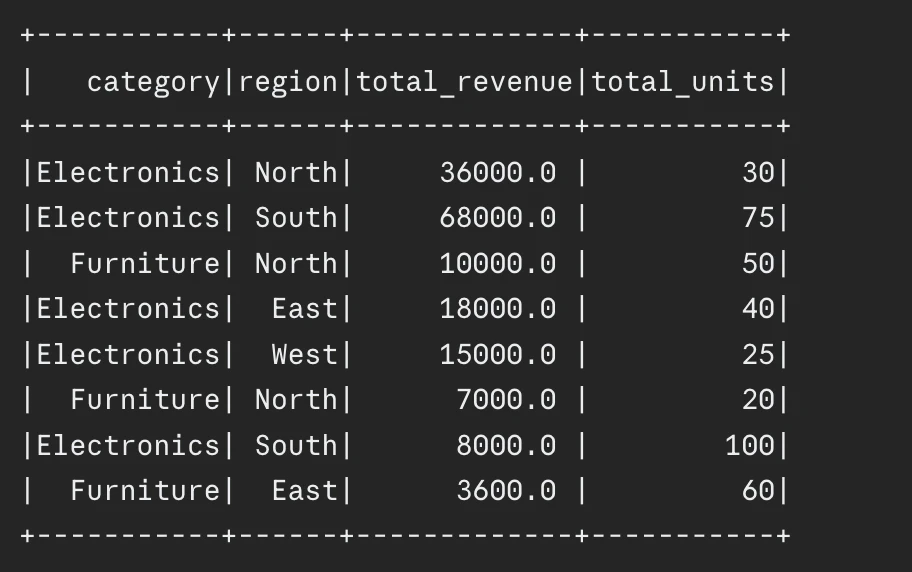
# BAD:
# A number of separate groupBy operations
# (a number of shuffles)
df_q1 = df.groupBy("class").agg(
spark_sum("income").alias("cat_revenue")
)
df_q2 = df.groupBy("area").agg(
spark_sum("income").alias("reg_revenue")
)
# GOOD:
# Mix aggregations in a single groupBy
# to scale back shuffles
df_combined = (
df.groupBy("class", "area")
.agg(
spark_sum("income").alias("total_revenue"),
spark_sum("models").alias("total_units")
)
)
df_combined.present()
Output:
Monitoring Shuffle Metrics in Spark UI
The Phases tab in Spark UI shows each Shuffle Learn and Shuffle Write metrics. The operations require optimization from you once they produce giant shuffle sizes which ought to lead you to pre-partition your knowledge for capability discount. The SQL tab reveals shuffle change nodes in your question plan.
Approach 11: Use Bucketing for Repeated Joins
The pipeline requires a number of joins of the identical giant tables which causes shuffle overhead to vanish by means of bucketing as a result of it creates disk-based knowledge group.
What Is Bucketing?
Bucketing is a method the place Spark writes knowledge to disk pre-sorted and pre-partitioned by a be part of key. Spark makes use of pre-existing knowledge partitions to conduct its joins as a substitute of performing knowledge shuffling. The result’s a be part of with no shuffle in any respect.
How Bucketing Improves Be part of Efficiency
Once you bucket two tables on the identical key with the identical variety of buckets matching rows go into matching bucket information. When Spark reads these tables for a be part of it could instantly pair up corresponding bucket information with none community switch. The shuffle price drops to zero.
PySpark Code Instance
from pyspark.sql import SparkSession
spark = (
SparkSession.builder
.appName("BucketingDemo")
.config(
"spark.sql.sources.bucketing.enabled",
"true"
)
.enableHiveSupport()
.getOrCreate()
)
# Massive orders desk
orders_data = [
(
i,
f"CUST_{i % 100:03d}",
float(i * 25.0),
"completed"
)
for i in range(1, 501)
]
orders = spark.createDataFrame(
orders_data,
["order_id", "customer_id", "amount", "status"]
)
# Buyer information desk
customers_data = [
(
f"CUST_{i:03d}",
f"Customer {i}",
f"Region_{i % 5}"
)
for i in range(100)
]
clients = spark.createDataFrame(
customers_data,
["customer_id", "customer_name", "region"]
)
# Write each tables bucketed on customer_id
# with the identical variety of buckets
orders.write
.bucketBy(10, "customer_id")
.sortBy("customer_id")
.mode("overwrite")
.saveAsTable("orders_bucketed")
clients.write
.bucketBy(10, "customer_id")
.sortBy("customer_id")
.mode("overwrite")
.saveAsTable("customers_bucketed")
# Now this be part of requires NO shuffle
# Spark matches bucket information instantly
end result = (
spark.desk("orders_bucketed")
.be part of(
spark.desk("customers_bucketed"),
on="customer_id"
)
.groupBy("area")
.agg({"quantity": "sum"})
)
end result.present()
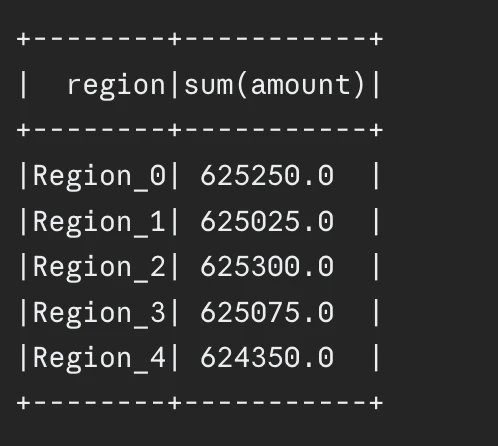
Output:
Finest Use Instances for Bucketing
Your pipeline requires a number of joins with giant dimension tables which you course of repeatedly.
Knowledge warehouses use fact-to-dimension joins for his or her becoming a member of operations.
Any two giant DataFrames that share the identical key could have a number of be part of operations all through the day.
It’s best to use bucket-merge joins to exchange sort-merge joins in these particular conditions.
Approach 12: Tune Spark Configuration Settings
The right Spark configuration settings ship substantial efficiency enhancements which stay relevant even after implementing all code-level enhancements. Your jobs expertise efficiency degradation as a result of misconfigured executors both waste assets or generate reminiscence errors.
Vital Spark Configurations for Efficiency
Spark offers greater than 100 configuration settings. The next settings ship the strongest affect for general-purpose efficiency enhancements.
Executor Reminiscence: Spark configuration by means of spark.executor.reminiscence units the entire reminiscence allocation for executor-based calculations and knowledge preservation. Spark strikes knowledge to disk once you set this worth under the required degree. The extreme setting waste reminiscence assets which might help extra executor operations.
Executor Cores: The spark.executor.cores setting determines the variety of duties that every executor can course of on the similar time. The optimum vary for this worth lies between 2 and 5. The system experiences rubbish assortment strain when a number of cores entry the identical Java digital machine reminiscence area.
Driver Reminiscence: The spark.driver.reminiscence setting establishes the entire reminiscence capability for the motive force. It’s best to enhance this parameter when your system collects in depth outcomes and desires a number of broadcast variables whereas executing intricate question planning procedures.
PySpark Configuration Instance
from pyspark.sql import SparkSession
from pyspark.sql.capabilities import (
col,
sum as spark_sum,
avg
)
spark = (
SparkSession.builder
.appName("ConfigTuningDemo")
.config("spark.executor.reminiscence", "4g")
.config("spark.executor.cores", "4")
.config("spark.driver.reminiscence", "2g")
.config("spark.sql.shuffle.partitions", "50")
.config("spark.sql.adaptive.enabled", "true")
.config(
"spark.sql.adaptive.coalescePartitions.enabled",
"true"
)
.config("spark.reminiscence.fraction", "0.8")
.config("spark.reminiscence.storageFraction", "0.3")
.config(
"spark.serializer",
"org.apache.spark.serializer.KryoSerializer"
)
.getOrCreate()
)
# Dummy payroll dataset
payroll_data = [
(
f"EMP_{i:04d}",
f"Dept_{i % 10}",
float(50000 + (i % 50) * 1000),
"FT" if i % 4 != 0 else "PT"
)
for i in range(1, 201)
]
df = spark.createDataFrame(
payroll_data,
[
"emp_id",
"department",
"annual_salary",
"employment_type"
]
)
end result = (
df.filter(col("employment_type") == "FT")
.groupBy("division")
.agg(
spark_sum("annual_salary").alias("total_payroll"),
avg("annual_salary").alias("avg_salary")
)
.orderBy("total_payroll", ascending=False)
)
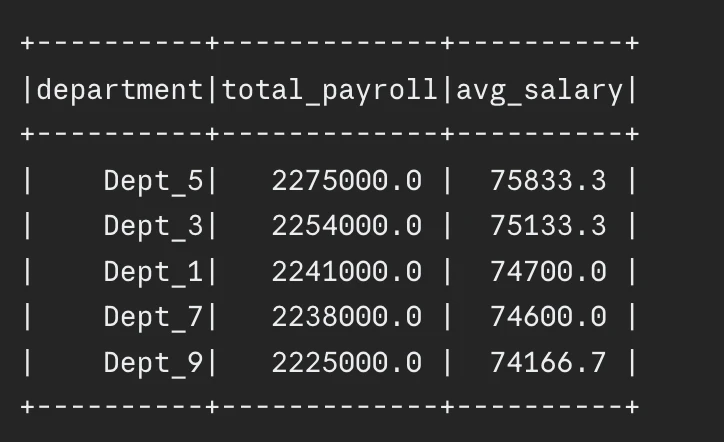
end result.present(5)
Output:
Cluster-Degree vs Software-Degree Tuning
Cluster-level settings: The cluster makes use of default settings from spark-defaults.conf to ascertain cluster-wide configuration for all Spark purposes. The baseline settings ought to be established by means of these settings.
Software-level settings: Software-level settings (set in SparkSession.builder.config()) override cluster defaults for a particular job. The system permits job-specific changes by means of these settings.
Finish-to-Finish PySpark Optimization Instance
Okay so now lets sew all these methods collectively into one thing that feels extra like an actual pipeline. We begin with a sluggish, kinda unoptimized job, then we work out the place it stalls, and solely after that we stack a number of methods to get the optimized model out.
Baseline Sluggish Spark Job
from pyspark.sql import SparkSession
from pyspark.sql.capabilities import (
col,
sum as spark_sum,
broadcast
)
spark = (
SparkSession.builder
.appName("OptimizedJob")
.config("spark.sql.adaptive.enabled", "true")
.getOrCreate()
)
# Massive transactions desk
# Learn as Parquet as a substitute of CSV for higher efficiency
transactions = spark.learn.parquet(
"/tmp/transactions_parquet"
)
# Product lookup desk
merchandise = spark.learn.parquet(
"/tmp/products_parquet"
)
# Filter early and choose solely required columns
transactions_filtered = (
transactions
.filter(col("standing") == "accomplished")
.choose(
"product_id",
"quantity"
)
)
products_selected = (
merchandise
.choose(
"product_id",
"class"
)
)
# Broadcast small lookup desk
end result = (
transactions_filtered
.be part of(
broadcast(products_selected),
on="product_id"
)
.groupBy("class")
.agg(
spark_sum("quantity").alias("total_amount")
)
)
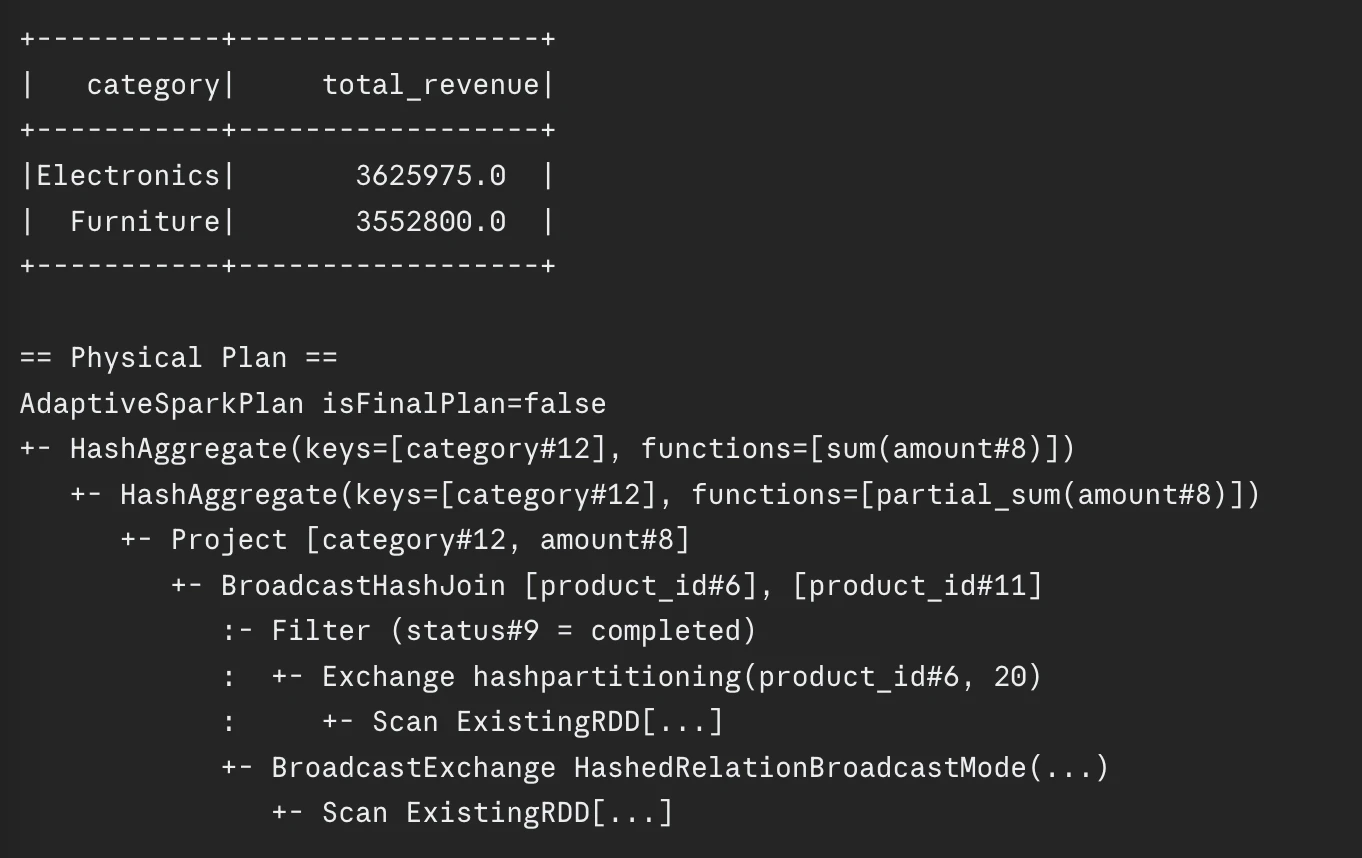
end result.present()
Figuring out Efficiency Bottlenecks
If we run end result.clarify(True) on the sluggish job it reveals a bunch of issues: there isn’t a predicate pushdown, which occurs as a result of CSV merely doesn’t help it, you get a full type merge be part of which causes an enormous shuffle, it reads all columns from each information, and adaptive optimizations aren’t enabled in any respect.
Making use of A number of Optimization Methods
Now allow us to rewrite the job, with all of the optimizations turned on and utilized, step-by-step so it behaves correctly.
from pyspark.sql import SparkSession
from pyspark.sql.capabilities import (
broadcast,
col,
sum as spark_sum
)
spark = (
SparkSession.builder
.appName("OptimizedJob")
.config("spark.sql.adaptive.enabled", "true")
.config(
"spark.sql.adaptive.coalescePartitions.enabled",
"true"
)
.config(
"spark.sql.adaptive.skewJoin.enabled",
"true"
)
.config("spark.sql.shuffle.partitions", "20")
.config(
"spark.serializer",
"org.apache.spark.serializer.KryoSerializer"
)
.getOrCreate()
)
# Create dummy transactions
# (in an actual job, learn from Parquet)
txn_data = [
(
f"TXN{i:05d}",
f"PROD_{i % 10:03d}",
float(i * 14.5),
"completed" if i % 5 != 0 else "failed",
f"CUST_{i % 50:03d}"
)
for i in range(1, 1001)
]
transactions = spark.createDataFrame(
txn_data,
[
"txn_id",
"product_id",
"amount",
"status",
"customer_id"
]
)
# Small merchandise desk
# excellent for broadcasting
prod_data = [
(
f"PROD_{i:03d}",
f"Product {i}",
"Electronics" if i % 2 == 0 else "Furniture"
)
for i in range(10)
]
merchandise = spark.createDataFrame(
prod_data,
[
"product_id",
"product_name",
"category"
]
)
Optimizing Partitions
# Repartition transactions on product_id earlier than be part of
transactions_repartitioned = transactions.repartition(20, "product_id")
Including Broadcast Be part of
# Use broadcast for the small merchandise desk — eliminates shuffle
joined = transactions_repartitioned.be part of(broadcast(merchandise), on="product_id")
Enabling AQE
Already enabled within the SparkSession config above. AQE handles dynamic partition coalescing and skew joins routinely, prefer it simply… nicely, takes care of it on the fly.
Lowering Shuffle
# Filter early, choose solely required columns, mixture in a single move
end result = joined
.filter(col("standing") == "accomplished")
.choose("txn_id", "class", "quantity")
.groupBy("class")
.agg(spark_sum("quantity").alias("total_revenue"))
Remaining Optimized Model
end result.present()
end result.clarify()
Output:
Conclusion
PySpark optimization isn’t just one single repair, its extra like this stacked set of layered decisions that snowball into large efficiency wins. Begin with the excessive affect fundamentals, use Parquet, flip on AQE , filter early and solely pull the columns you really need. After that, transfer into the be part of technique stuff, suppose partitioning and take care of skew.
With these 12 methods in your toolkit you possibly can usually drag hours-long Spark runs all the way down to minutes, however you need to apply them in a scientific method. Additionally measure it utilizing the Spark UI, and maintain tuning as you study. The hole between a sluggish Spark job and a quick one is normally very apparent when you take a look at the execution plan.
Whats up! I am Vipin, a passionate knowledge science and machine studying fanatic with a robust basis in knowledge evaluation, machine studying algorithms, and programming. I’ve hands-on expertise in constructing fashions, managing messy knowledge, and fixing real-world issues. My aim is to use data-driven insights to create sensible options that drive outcomes. I am wanting to contribute my expertise in a collaborative setting whereas persevering with to study and develop within the fields of Knowledge Science, Machine Studying, and NLP.
Login to proceed studying and luxuriate in expert-curated content material.
Cloud outages drove headlines in 2025 with disruptions throughout main suppliers and lots of of hundreds of thousands in estimated losses. However the havoc wasn’t precipitated for under the explanations many enterprise and industrial IT leaders anticipated. In a number of high-profile incidents, the underlying infrastructure remained absolutely purposeful.
Throughout a number of business analyses, a sample has emerged: Failures more and more originate not within the knowledge airplane — the place workloads run — however within the management and administration layers that coordinate, authenticate, configure and orchestrate programs at scale.
In keeping with Uptime Institute’s seventh Annual Outage Evaluation, IT and networking outages elevated in 2024, accounting for 23% of impactful outages, reflecting elevated IT and community complexity that led to points with change administration and misconfigurations. This represents a elementary shift within the outage panorama, one which {hardware} redundancy can not handle: Infrastructure did not fail, management did.
Trade analysts are drawing the identical conclusion. The 2024 Gartner report “9 Rules for Enhancing Cloud Resilience” famous that management airplane failures can forestall operators from executing remedial actions even when data-plane visitors continues to be flowing, blocking provisioning, configuration adjustments and automatic restoration actions on the very second they’re wanted most. In these eventualities, resilience relies upon much less on redundant infrastructure and extra on prebuilt contingency plans and examined operational procedures.
The fragility of centralized management
Fashionable cloud and distributed environments rely on management planes. These are centralized or semi-centralized programs that deal with orchestration, coverage enforcement, identification, routing and lifecycle administration. These layers act because the operational “mind” of digital infrastructure.
Over time, these management programs have turn into extra automated, extra feature-rich and extra centralized. That improves effectivity, but it surely additionally will increase threat. When a management airplane misconfigures assets or turns into unavailable, the impression can lengthen throughout areas, websites and companies concurrently.
For years, resilience technique targeted on redundancy: duplicate servers, replicated storage and distributed clusters. These measures defend execution capability. Nonetheless, they don’t assure operational continuity when orchestration and administration layers fail.
When management programs are impaired, organizations could encounter the next:
Functions could proceed operating, however they can’t be reached.
Methods stay wholesome, however they can’t be reconfigured.
Identification and entry companies are on-line however unusable.
Automation pipelines propagate errors quicker than groups can reply
For industrial and enterprise operators, this creates a harmful phantasm of availability with out operability. It is akin to a manufacturing facility with absolutely purposeful equipment however no management system to coordinate operations.
Complexity, automation enhance dangers
The stakes will solely go increased as environments turn into more and more software-defined, extra complicated and extra automated, whereas nonetheless being extremely depending on people to keep away from errors. Outage analyses throughout the business proceed to indicate that course of breakdowns and human error stay main contributors, particularly throughout change occasions. It is no surprise; operational groups now handle hybrid estates spanning cloud, edge, on-premises and third-party platforms, which are sometimes linked by means of layered automation and coverage engines. Every added integration level will increase coupling and reduces transparency. On the similar time, enterprises are pushing quicker launch cycles, extra infrastructure as code and broader automation — all optimistic tendencies, however ones that require stronger guardrails and validation.
The result’s a threat multiplier: increased system complexity, mixed with quicker change velocity and centralized management authority.
Industrial, mission-critical programs face excessive stakes
For industrial and enterprise operators, outages will not be simply digital occasions; they’re operational occasions. Downtime can halt manufacturing traces, interrupt subject operations, delay logistics, disrupt communications or have an effect on security programs.
These environments can not rely solely on distant or centralized restoration. They require architectures that may maintain protected, predictable operation even when upstream management programs are degraded.
That requires designing for operational independence, not simply availability.
Key architectural priorities more and more embrace:
Distributed management with site-level autonomy.
Native survivability throughout WAN or cloud management loss.
Fault domains that restrict orchestration blast radius.
Deterministic habits below degraded connectivity.
Change validation and staged rollout controls.
Operational guardrails that constrain automation threat.
From uptime to operational continuity
Conventional resilience metrics emphasize uptime, specializing in whether or not infrastructure is reachable and powered. However for industrial and enterprise programs, the extra significant measure is operational continuity: Guaranteeing programs stay controllable, observable and protected below stress.
A system that’s technically “up” however can’t be managed, authenticated or reconfigured is just not operationally out there.
As enterprises develop edge deployments, undertake AI-driven workloads, and enhance automation throughout infrastructure, the management airplane turns into a main threat floor.
Resilience methods should evolve, extending past redundant {hardware} and multi-region failover to incorporate distributed management design, course of self-discipline and failure-containment structure. This can be a new architectural mindset, one which extends resilience to all of the items that collectively decide how a cloud operates below strain.
In an period outlined by digital dependence, the true measure of cloud resilience is the flexibility to proceed functioning when the sudden occurs. The lesson from outage tendencies is obvious: Resilience is now not outlined by solely what retains operating, however by what stays in management.
Vanny Birungi, a Crimson Cross volunteer, speaks to individuals throughout a public sensitisation marketing campaign amid the Ebola outbreak in Bunia, Congo, Monday, Could 25, 2026.
Moses Sawasawa/AP
conceal caption
toggle caption
Moses Sawasawa/AP
BUNIA, Congo — Each time Vanny Birungi, a volunteer with the Crimson Cross in jap Congo, goes out to boost consciousness in regards to the newest Ebola outbreak as suspected circumstances close to 1,000, she faces a double risk.
One is the uncommon Bundibugyo kind of Ebola, with no vaccine or therapy. The opposite is the anger and suspicion of residents who’ve pelted her with stones and verbal abuse in Bunia, a metropolis on the coronary heart of the outbreak.
“We proceed to inform them that the illness is on the market. Some settle for, and others do not,” Birungi informed The Related Press on Monday as she and colleagues spoke with teams of individuals in a working-class neighborhood beneath the scorching solar.
Help staff are particularly in danger on this unstable area the place residents, like Birungi, have lengthy been beneath risk of armed teams which have killed hundreds of individuals and displaced many extra in recent times.
Belief is tough to seek out among the many traumatized inhabitants that’s cautious of outsiders, even these attempting desperately to comprise the quickly spreading outbreak that specialists say was found weeks late. Surveillance for such illnesses has been weakened by U.S. and different assist cuts.
“These individuals ought to cease bothering us. They only wish to get wealthy. Let’s not overlook that Ebola is a white man’s invention,” declared Pierre Basola, a 56-year-old resident of Bunia, who added: “Cease speaking to me anyway.”
Francois Kasereka, a member of the Congo Scouts motion, speaks to individuals throughout a public sensitisation marketing campaign amid the Ebola outbreak in Bunia, Congo, Saturday, Could 23, 2026.
Moses Sawasawa/AP
conceal caption
toggle caption
Moses Sawasawa/AP
Circumstances are nearing 1,000 however well being facilities are burned
Thrice previously week, healthcare services have been attacked. On Sunday, offended younger males stormed a hospital treating Ebola sufferers, forcing medical workers to evacuate them as gunfire rang out.
On Saturday, a gaggle of residents set fireplace to a tent for suspected and confirmed Ebola circumstances run by Medical doctors With out Borders in Mongbwalu, and greater than a dozen individuals suspected to have the virus fled. On Thursday, a middle in Rwampara was burned after family members had been barred from retrieving the physique of a person suspected to have Ebola.
Anger is amplified as virus prevention practices maintain family members from dealing with our bodies in remaining rites following an sickness some have described as sudden and dramatic, with vomiting and bleeding.
The Ebola virus is unfold via shut contact with sick or deceased sufferers’ bodily fluids, reminiscent of sweat, blood, feces or vomit. Specialists say healthcare staff and relations caring for sufferers face the very best danger.
“Belief is sort of as necessary because the well being response, as a result of if you happen to get this large mistrust within the communities, they don’t seem to be going to go to the well being facilities,” mentioned Heather Kerr, nation director for the Worldwide Rescue Committee in Congo.
Armed battle within the area poses one other problem. To journey from Bunia, the capital of Ituri province, to Mongbwalu, assist teams danger potential assaults in a area greater than 1,000 kilometers (620 miles) from Congo’s capital, Kinshasa.
In the meantime, the outbreak now has over 900 suspected circumstances and greater than 220 suspected deaths, the director common of the World Well being Group, Tedros Adhanom Ghebreyesus, mentioned Monday.
“We at the moment are taking part in catch-up with a really fast-moving epidemic,” he mentioned.
‘We go away all the things to God’
Mado Nditamba, a 70-year-old Bunia resident, mentioned she has seen college students operating away from assist staff.
“The final time Ebola got here, it was not on the size that we see at present,” Nditamba mentioned. “However this epidemic at present is worse. We go to the medical doctors within the hospitals, however in addition they die. That is what worries us. We do not know what to do and we go away all the things to God.”
Congo has had 17 Ebola outbreaks, and the WHO says the nation is supplied to reply. However early assessments on this outbreak had been carried out for a extra frequent kind of Ebola, dropping priceless time. Specialists are nonetheless attempting to find out when this outbreak started.
There are few locations to check for this Bundibugyo kind in a area the place clinics can run on mills and a serious airport serving as a humanitarian hub has been within the palms of rebels for over a 12 months.
Well being staff on the bottom have informed the AP they’re underprepared and underprotected. Now an unknown variety of responders have been contaminated, and a few have died.
A Congolese physician was reported useless on Sunday in Rwampara, Rubens Dhedgia, coordinator of the Ebola response within the area, informed the AP. In neighboring Uganda, the place a much smaller variety of circumstances has begun to unfold after Congolese traveled there, at the very least three well being staff have been contaminated.
And maybe most worryingly, the Worldwide Federation of Crimson Cross and Crimson Crescent Societies says three volunteers died in Mongbwalu after it believes they dealt with our bodies on March 27 throughout work unrelated to Ebola.
If confirmed, that might considerably push again the timeline of the outbreak from the primary confirmed loss of life in late April in Bunia.
Some residents nonetheless imagine Ebola is a fable
At the same time as at the very least one funeral dwelling supervisor dusted off coffins on the market alongside a highway in Bunia, specialists reported an absence of belief amongst some residents of the area who don’t imagine the virus exists.
Motion Help, one other of the worldwide humanitarian teams responding, mentioned a excessive degree of skepticism and lack of knowledge stays, citing residents it questioned in mid-Could in Ituri province simply after the outbreak was introduced.
“The one option to go, so far as this explicit virus is anxious, is neighborhood engagement,” mentioned Yakubu Mohammed Saani, nation director for Motion Help in Congo.
How that will likely be improved, and shortly, continues to be not clear. In the meantime, each the WHO and Africa Facilities for Illness Management and Prevention imagine the outbreak is bigger than the circumstances reported to date.
The Rossignol Venosk. All pictures: iRunFar/Bryon Powell
Door-to-trail sneakers have all the time been round — simply marketed underneath completely different phrases — and the Rossignol Venosk ($140) is the French model’s tackle a easy and versatile workhorse that provides consolation and efficiency. Though the model is greatest recognized for its snow-sport tools, they’re making a reputation for themselves rapidly in path operating as nicely.
After lately testing the Rossignol Vezor (overview), I used to be wanting to tackle its sibling, the Rossignol Venosk. Each are adaptable and value-laden sneakers. As I wrote within the Vezor overview, Rossignol is studying the temperature of the path operating world and making use of its product design data to its path shoe line.
The Venosk has a 28-millimeter stack peak on the heel and 22 millimeters on the forefoot for a easy 6-millimeter drop. It has an precise weight of 9.2 ounces (260 grams) for a U.S. males’s 9 — lighter than the Vezor. Total, versatility is the popular and dominant descriptor of this shoe. It matches nicely, grips on a wide range of terrain, has a lightweight, breathable higher, and gives a responsive trip good for shorter runs. With street miles, snow miles, and abandoned technical miles, the Venosk confirmed up able to navigate many strong runs.
The Rossignol Venosk higher is fabricated from a breathable engineered mesh and has a strong toe bumper.
The Rossignol Venosk higher resembles the Rossignol Vezor in character and aesthetic attraction. The Venosk is barely wider all through, particularly on the toebox. A large, forgiving toebox is a clutch design within the realm of endurance and facilitates higher-volume days. The mission of the Venosk is more true endurance, versus the Vezor’s speedier objectives. Regardless of offering extra toe room than the Vezor, the Venosk nonetheless has a slender and tapered look, simply much less so. Its size helps with general house.
I had a a lot simpler time dialing in a efficiency match with the Venosk, aided by two main design ingenuities. A double-lacing system with a wider set of lace holes at three distinct areas on each side has the capability to marginally launch the higher from a tighter wrap. This allowed me to dial within the match at a extra exact stage for extra quantity and rest. Subsequent, a double insole system accommodates completely different foot shapes. As with the Rossignol Vezor, which has the identical insoles, the very first thing I did was take away the 2-millimeter flat insole under the principle insole. The latter is patterned with gentle compression beads for additional underfoot suggestions. This twin insole system permits the wearer to decide on their precision match primarily based on their toes and operating wants.
The engineered higher mesh, made partially of recycled supplies, is comfy, gentle, and breathable. It sits atop an intensive inner midfoot wrap that gives additional assist. It’s each snag-resistant and technically resilient, particularly if venturing off-trail or by chance shedding the path within the desert. Cacti damage. In snow and in 100-degree Fahrenheit climate, the higher felt supportive. It dried rapidly and allowed airflow.
The toebox has a suitably thick TPU bumper, and the heel is solidly constructed, notably on the medial aspect. The wedge heel design retains the gait on monitor and the heel locked in. The lateral midsole pushes up simply barely, however the shoe helps a lateral heel touchdown whereas offering sufficient medial assist to assist cut back overpronation by way of the later components of the gait. This doesn’t imply it’s important to land in your heel, however the design is there.
The excessive heel sheath aids slip-on and covers the Achilles. I might see how the raised heel collar could offend some individuals’s ankle bones.
The one hang-up I’ve with the Venosk is the tongue. Whereas it’s held in place with an inner midfoot wrap, I discovered that it nonetheless tended to shift.
Rossignol Venosk Midsole
The EVA midsole of the Rossignol Venosk makes use of the model’s Sensor 3 expertise to supply underfoot assist.
The Rossignol Venosk makes use of the model’s Sensor 3 expertise to create a reliable, long-lasting underfoot expertise. The midsole is fabricated from a monoblock EVA foam that’s injected moderately than compressed, which helps extra athleticism on the path.
The Sensor 3 idea makes use of three zones underfoot to boost shock absorption, consolation, and general cushion. The system, which provides and removes foam in sure areas, focuses on correctly supporting three proprioceptive nerves within the foot to enhance steadiness. This affords the midsole to supply propulsion with elevated floor really feel. It additionally offered me with respectable street miles once I wanted them. With near 150 miles on these sneakers, I can nonetheless really feel the midsole assist and luxury. I’m eager on a strong EVA foam regardless of the growing reputation of some higher-end choices.
Rossignol Venosk Outsole
The 4-millimeter lugs on the Rossignol Venosk provide grip on trails but additionally run nicely on roads.
The Rossignol Venosk outsole is a rubber that’s going locations. It has a well-designed tread that undoubtedly takes the shoe from doorsteps to the filth past. The Venosk makes use of Rossignol’s Sensor All Terrain Rubber, a proprietary mix with superior grip. As a runner with a passion for sneakers recognized for his or her grip — just like the VJ iRock+ (overview) or the VJ Lightspeed (overview) — and people with Vibram Megagrip, I do know when an outsole is primed for traction and friction. The Venosk outsole works. I trusted it on all terrains, from snow to abandon granitic soils and filth singletrack in between.
One of the best factor in regards to the outsole together with the general shoe design is that it runs nicely on the street. After I briefly damage my again, I needed to forego all my cushioned street sneakers for the Venosk as a result of it allowed extra leg suggestions as a substitute of accelerating the chain of discomfort. In a nod to its versatility, it slid in as a street shoe with out hesitation. The hoofed heel and the midfoot midsole reveal permit for a few of this flexibility.
The 4-millimeter lugs aren’t overly aggressive, however the distinctive single and double quadrilateral- and trapezoid-shaped lugs each pattern the gait ahead and provide eager medial to lateral stability. I’ve by no means seen something prefer it earlier than. The lugs body the rim of the outsole properly. There’s probably a technique behind the lug design and placement, however for what it’s value, it really works.
Rossignol Venosk Total Impressions
The Rossignol Venosk is a flexible and athletic road-to-trails shoe.
I’ve genuinely loved my adventures within the Rossignol Venosk. It’s a remarkably adept and athletic-fitting path operating shoe. The heel drop, low weight, acquainted — but enhanced — midsole, and eager outsole design welcomed an array of prospects. There’s pep within the Venosk step. It could possibly stride slowly for miles, however it may flip up the depth when wanted. It’s model and a mannequin value trusting, and it may carry out throughout the seasons.
Pickleball has a humorous method of pulling individuals in quick. One week, somebody is enjoying an off-the-cuff sport with mates. A number of weeks later, they’re shopping for a greater paddle, studying find out how to dink, and attempting to determine why their calves really feel cooked after a couple of video games. The game appears easy from the surface, however as soon as rallies pace up, you begin to really feel how a lot fast motion, stability, and physique management matter.
From a training perspective, that’s the place coaching turns into helpful. Pickleball asks you to maneuver laterally, cease rapidly, rotate by photographs, and keep sharp by repeated factors. Gamers who transfer properly often aren’t counting on a single high quality. They’ve sufficient energy to carry positions, sufficient energy to react, and sufficient management to remain balanced when the ball pulls them misplaced.
Perhaps most of us aren’t coaching for a professional tour cease anytime quickly, however preparation nonetheless issues. Weekend matches nonetheless get aggressive, particularly as soon as the trash discuss begins flying and no one needs to lose the ultimate sport earlier than heading dwelling. Placing in some work throughout the week helps you progress higher, recuperate sooner, and present up feeling able to play, somewhat than spending Monday morning questioning why your hips, knees, and shoulders really feel like they went by a five-set event.
This information breaks down find out how to prepare for pickleball with a performance-first strategy. We’ll have a look at what the game calls for by a wants evaluation, then construct that right into a sensible coaching plan for pace, energy, and court docket management. The purpose is that can assist you transfer higher, hit with extra confidence, and maintain your physique feeling good as you play extra usually.
Pickleball Is Rising Quick, and the Recreation Is Getting Extra Athletic
Pickleball has exploded over the previous few years, and the numbers make that fairly onerous to disregard. In keeping with the Sports activities & Health Business Affiliation’s newest participation information, 24.3 million Individuals performed pickleball in 2025, with participation rising 479% from 2020 to 2025. SFIA additionally stories that pickleball grew 171.8% from 2022 to 2025, making it the fastest-growing sport in the USA.
A number of numbers stand out:
24.3 million Individuals performed pickleball in 2025
Participation grew 479% from 2020 to 2025
Pickleball grew 171.8% from 2022 to 2025
The game now ranks among the many high 25 most-played sports activities and actions within the U.S.
SFIA notes sturdy participation amongst younger adults, adults ages 25 to 44, and gamers, 65+
As extra individuals get into pickleball, the sport naturally quickens. You see longer rallies, sharper motion, and extra gamers who can assault weak returns. The physique has to maintain up with that tempo. Fast cuts, onerous stops, repeated side-to-side motion, and lengthy periods can add stress quick. For gamers who need to enhance and keep wholesome, the work they do off the court docket issues extra.
Pickleball Wants Evaluation: What the Sport Calls for From the Athlete
A wants evaluation examines the calls for of the game and compares them with what the athlete can presently do. In pickleball, meaning trying past the paddle and taking note of how the physique strikes, reacts, and holds up over the course of repeated video games. Fast factors, fixed modifications of course, and lengthy periods place extra stress on the physique than most individuals anticipate once they first begin enjoying. Cedric Scotto, MS Kinesiology, CEO and founding father of Notace Footwear, factors out that many leisure gamers underestimate how bodily demanding pickleball can grow to be as soon as motion quickens, and rallies get longer. He notes that fast cuts and reactive motion patterns place important stress on the toes and ankles, particularly for gamers who spend a number of days per week on the court docket.
A number of bodily qualities have a tendency to indicate up constantly in gamers who transfer properly, keep balanced, and maintain up over time:
Lateral Motion and Deceleration: Pickleball requires fixed side-to-side motion, fast stops, and speedy modifications of course. Gamers want to soak up drive effectively and reposition rapidly between photographs.
Foot and Ankle Stability: Sturdy toes and steady positioning assist gamers transfer confidently and scale back pointless stress by the ankles throughout cuts and reactive motion.
Decrease-Physique Power and Energy: Sturdy legs assist assist acceleration, stability, and repeated motion all through lengthy matches and prolonged play periods.
Rotational Energy: Power generated by the hips and torso helps drive photographs whereas supporting higher physique management throughout rotational motion patterns.
Stability and Coordination: Gamers consistently shift positions, react to awkward bounces, and modify to altering shot angles. Good stability helps preserve management throughout quick exchanges.
Shoulder and Higher-Physique Sturdiness: Repeated swings, volleys, and overhead photographs place ongoing calls for on the shoulders, elbows, and higher again.
Work Capability and Restoration: Pickleball usually includes a number of matches, prolonged rallies, and repeated play all through the week. Conditioning and restoration grow to be extra essential as court docket time will increase.
Scotto additionally emphasizes that preparation is usually neglected as a result of pickleball feels accessible early on. Many gamers leap straight into video games with out warming up or doing a lot bodily preparation outdoors the court docket. Over time, these habits can meet up with individuals, particularly as soon as the quantity will increase.
Understanding these calls for makes it simpler to coach with goal. As an alternative of guessing what may assist your sport, you possibly can concentrate on the bodily qualities that straight carry over to motion, management, and sturdiness on the court docket.
tanaonte/Adobe Inventory
How you can Practice for Pickleball Efficiency
Pickleball coaching ought to concentrate on motion high quality first, then construct pace, energy, energy, and sturdiness round it. The game strikes rapidly, particularly throughout longer rallies, and gamers spend a lot of their time accelerating, stopping, reacting, and repositioning. An excellent coaching program ought to assist these calls for with out including pointless complexity.
This program makes use of a easy two-day setup constructed across the bodily qualities that carry over most to the court docket. Every session begins with a warm-up to lift physique temperature, enhance mobility, and put together the toes, hips, shoulders, and higher again for motion. Plyometric work comes subsequent to coach quickness, reactive potential, and lower-body elasticity. Energy workout routines comply with whereas the physique remains to be recent, serving to enhance drive manufacturing and rotational explosiveness. Power work builds the muse that helps stability, positioning, and repeated motion all through matches, whereas accent workout routines assist reinforce shoulder well being, core management, and sturdiness.
The purpose right here isn’t to coach like a full-time athlete. It’s to maneuver higher, keep more healthy, and construct bodily qualities that truly present up throughout video games. Even a few structured periods per week could make a noticeable distinction as soon as matches begin rushing up.
Begin With a Correct Heat-Up
This warm-up can be used for each coaching days and may also be accomplished earlier than matches or longer apply periods. The purpose is to lift physique temperature, loosen up key areas concerned in motion and rotation, and put together the physique for fast modifications of course as soon as play begins.
For pickleball, the highest priorities are getting the toes and ankles prepared for motion, opening the hips and higher again, and activating the muscle groups that stabilize the shoulders and core. Scotto notes that many gamers overlook warming up completely, regardless that a couple of minutes of preparation could make a significant distinction as soon as the tempo of play picks up on the court docket.
Key Focus Areas
Foot and Ankle Preparation: Helps enhance stability and readiness for fast cuts and course modifications
Hip Mobility: Helps lateral motion, stability, and rotational positioning
Thoracic Backbone Mobility: Helps enhance upper-body rotation and posture
Shoulder Activation: Prepares the shoulders and higher again for repeated swings and volleys
Core Engagement: Helps stability, management, and drive switch throughout motion
Pattern Warmup
Bounce Rope or Gentle Skipping: 20–30 seconds Raises physique temperature and prepares the toes and ankles for motion
Standing Hip Circles: 8–10 reps every course Opens the hips and prepares the decrease physique for lateral motion and rotation
World’s Biggest Stretch: 5 reps either side Opens the hips and higher again whereas transferring by a deep lunge place
Down Canine to Cobra: 6–8 reps Warms up the shoulders, hips, and thoracic backbone by a number of motion patterns
Lateral Lunges: 8 reps either side Prepares the hips and groin for side-to-side motion
Quadruped or Standing T-Backbone Rotations: 8–10 reps either side Improves upper-back mobility and rotational motion
Band Pull-Aparts: 10–12 reps Prompts the higher again and shoulders
Plank with Shoulder Faucets: 5–6 reps either side Builds trunk stability and shoulder management throughout motion patterns
joescarnici/Adobe Inventory
Coaching Day 1: Acceleration, Energy, and Full-Physique Power
This session focuses on acceleration, rotational explosiveness, and full-body energy that carry over to court docket motion and shot manufacturing. The construction strikes from reactive motion into energy and finishes with easy conditioning work to construct total work capability.
Plyometric Prep
Prepares the toes, ankles, and decrease physique for explosive motion
Vertical Pogos: 2 units x 10 reps
Line Hop Pogos: 2 units x 10 reps every course
Superset A: Plyometric Energy + Rotational Explosion
Builds lower-body explosiveness and rotational drive manufacturing
A1. Broad Jumps: 4 units x 3 reps
A2. Half-Kneeling Rotational Med Ball Shot Put: 4 units x 3 reps either side
Superset B: Agility and Motion Management
Trains lateral repositioning, acceleration, and court docket motion
B1. Hip Change to 3-Step Energy Shuffle: 4 units x 2 reps either side
B2. Lateral Certain to Stick: 4 units x 3 reps either side
Superset C: Full-Physique Power and Higher-Physique Management
Builds lower-body energy, stability, and upper-body positioning
C1. Goblet Ahead Lunges: 3 units x 8 reps either side
C2. Single-Arm Dumbbell Rows: 3 units x 8–12 reps either side
Superset D: Posterior Chain Energy, Shoulder Stability, and Core Management
Targets hip drive, upper-body stability, and trunk management
D1. Kettlebell Swings: 3 units x 10–12 reps
D2. Half-Kneeling Dumbbell Shoulder Press: 3 units x 8–10 reps either side
D3. Facet Plank Maintain: 3 units x 15–20 seconds either side
Elective 10-Minute Conditioning
Builds cardio capability and repeat effort conditioning
Bike, rower, SkiErg, or elliptical intervals
20 seconds moderate-hard effort / 40 seconds straightforward tempo x 10 rounds
Notes:
Carry out every superset so as earlier than resting
Relaxation 60–90 seconds between rounds
Hold pogos mild, springy, and fast off the bottom
Deal with jumps, throws, and agility work like talent apply. Cease the set earlier than pace or management drops
Hold conditioning easy. The purpose is to construct the engine, not bury your self
joescarnici/Adobe Inventory
Coaching Day 2: Lateral Motion, Deceleration, and Sturdiness
This session locations a larger concentrate on lateral motion, deceleration, and full-body energy to assist repeated modifications of course and longer matches on the court docket.
Plyometric Prep
Prepares the toes, ankles, and decrease physique for reactive motion
Vertical Pogos: 2 units x 10 reps
Line Hop Pogos: 2 units x 10 reps every course
Superset A: Lateral Plyometrics + Rotational Energy
Builds side-to-side explosiveness and rotational drive manufacturing
A1. Skater Jumps to Stick: 4 units x 4 reps either side
A2. Facet-to-Facet Med Ball Slams: 4 units x 3 reps either side
Superset B: Acceleration and Deceleration Management
Improves transition pace, braking potential, and court docket positioning
B1.Base Stance Begin, 3-Step Dash to 3-Step Backpedal: 4 units x 2 reps either side
B2. Lateral Shuffle to Stick: 4 units x 3 reps either side
Superset C: Full-Physique Power and Push Management
Builds lower-body energy, upper-body drive manufacturing, and stability
C1. Goblet Maintain Break up Squats: 3 units x 8 reps either side
C2. Push-Ups: 3 units x 8–15 reps
Superset D: Posterior Chain Power, Pulling Power, and Anti-Rotation Management
Targets hip drive, upper-back energy, and trunk stability
D1. Dumbbell Romanian Deadlifts: 3 units x 8–10 reps
D2. Chin-Ups (Assisted if Wanted): 3 units x 5–8 reps
D3. Band Pallof Press: 3 units x 10 reps either side
Elective 10-Minute Conditioning
Builds cardio capability and repeat effort conditioning
Operating intervals
20–30 seconds run / 40–60 seconds stroll x 8–10 rounds
Notes:
Carry out every superset so as earlier than resting
Relaxation 60–90 seconds between rounds
Give attention to managed landings and steady positions throughout lateral motion work
Keep clean throughout agility drills and keep away from dashing transitions
Hold conditioning managed and repeatable somewhat than all-out depth
Restoration and Each day Habits That Enhance Pickleball Efficiency
The coaching helps, however what you do between exercises and matches performs an enormous position in how properly your physique holds up over time. Pickleball can add up rapidly, particularly as soon as individuals begin enjoying a number of days per week. The mixture of fast motion, repeated stops, and lengthy periods can put on on the toes, ankles, knees, hips, and shoulders if restoration will get ignored.
Scotto factors out that many gamers overlook the small habits that assist them keep wholesome and proceed transferring properly on the court docket. Warming up constantly, taking note of foot well being, and carrying steady footwear can all make a noticeable distinction as soon as enjoying quantity begins growing.
Restoration and Efficiency Ideas
Prioritize Sleep: Restoration, response time, and total motion high quality all take a success when sleep drops off
Keep Hydrated: Dehydration can have an effect on coordination, vitality ranges, and muscle perform throughout longer periods
Hold Shifting Between Periods: Strolling, mild mobility work, or straightforward restoration periods assist scale back stiffness and preserve motion high quality
Practice Your Ft and Ankles: Foot energy and ankle stability play a significant position in stability, slicing, and total motion effectivity
Handle Courtroom Quantity: Too many high-intensity video games with out restoration can put on down motion high quality and enhance soreness
Take Time to Heat Up: A couple of minutes of preparation earlier than enjoying will help enhance motion and scale back pointless stress on the physique
Use Secure Footwear: Supportive court docket sneakers assist enhance stability, consolation, and confidence throughout fast modifications of course
In the present day co-anchor Savannah Guthrie is doing every thing in her energy to seek out her 84-year-old mom, Nancy Guthrie, who has been lacking since early 2026. Though Savannah has returned to the information desk, sources informed business insider Rob Shuter that she’s “spending closely” on non-public investigators and has no plans to cease anytime quickly.
“Savannah is paying no matter it takes to maintain this search lively,” one supply informed Shuter’s Naughty However Good. “She refuses to rely solely on legislation enforcement.”
Guthrie has reportedly shaped a workforce of personal investigators, together with former federal brokers and safety specialists, who’re working to trace down leads associated to Nancy’s alleged abduction.
Buddies of the Emmy-winning journalist stated Guthrie has turn into “more and more pissed off” with the gradual tempo of the official investigation, particularly after Pima County Sheriff Chris Nanos minimize off direct communication along with her household.
“I personally am not,” Nanos beforehand informed Folks when requested if he was in contact with the Guthrie household. Pointing to the detectives and the FBI, Nanos famous, “In the event that they want the household for something, they get in contact with them and the household. It really works each methods.”
One other insider informed Shuter that Guthrie discovered Nanos’ feedback “extremely upsetting. She anticipated urgency and direct communication. As an alternative, she feels the investigation turned distant and procedural.”
Insiders additionally revealed to Shuter that Guthrie is spending “monumental” quantities of cash on the non-public search, and he or she refuses to cut back the operation.
“Cash doesn’t matter to her proper now,” one supply stated. “That is about discovering her mom. If extra investigators, extra safety, or extra sources assist, she’ll maintain paying for them.”
They added, “She nonetheless believes her mother could be discovered. That’s why the non-public investigators are nonetheless working each single day.”
This improvement comes amid experiences {that a} suspect’s identify could quickly be recognized. In a Might 2026 interview with Information 4 Tucson, Robbie Mayer—a former detective with the Pima County Sheriff’s Division—drew parallels between Nancy’s case and a serious investigation he led many years in the past. In 1986, Mayer broke the “Prime Time Rapist” case, through which Brian Larriva robbed Tucson properties and sexually assaulted the feminine residents. These crimes occurred between 1983 and 1986.
Mayer remembered that police sifted by “4,000 leads” earlier than lastly figuring out Larriva, who died by suicide after authorities surrounded his home. “One of many detectives had Larriva’s identify as a lead,” Mayer defined, “however he hadn’t gotten to it but as a result of he had so many leads in entrance of that.”
Now, Mayer is assured that “the suspect’s names are in these 50,000” suggestions submitted to investigators in Nancy’s case. He emphasised that perseverance shall be essential to cracking the thriller. “The query is that if they’ll acknowledge it after they see it,” Mayer continued. “Being in a case like that is like being in a discipline with rocks, and what you’re in search of is beneath one rock. You simply must maintain turning.”