
{kind=link}
It is a visitor submit by Jeffrey Wang, Co-Founder and Chief Architect at Amplitude in partnership with AWS.
Amplitude is a product and buyer journey analytics platform. Our prospects needed to ask deep questions on their product utilization. Ask Amplitude is an AI assistant that makes use of massive language fashions (LLMs). It combines schema search and content material search to offer a personalized, correct, low latency, pure language-based visualization expertise to finish prospects. Ask Amplitude has data of a person’s product, taxonomy, and language to border an evaluation. It makes use of a collection of LLM prompts to transform the person’s query right into a JSON definition that may be handed to a customized question engine. The question engine then renders a chart with the reply, as illustrated within the following determine.
Amplitude’s search structure advanced to scale, simplify, and cost-optimize for our prospects, by implementing semantic search and Retrieval Augmented Era (RAG) powered by Amazon OpenSearch Service. On this submit, we stroll you thru Amplitude’s iterative architectural journey and discover how we deal with a number of essential challenges in constructing a scalable semantic search and analytics platform.
Our major focus was on enabling semantic search capabilities and pure language chart era at scale, whereas implementing an economical multi-tenant system with granular entry controls. A key goal was optimizing the end-to-end search latency to ship fast outcomes. We additionally tackled the problem of empowering finish prospects to securely search and use their current charts and content material for extra subtle analytical inquiries. Moreover, we developed options to deal with real-time information synchronization at scale, ensuring fixed updates to incoming information could possibly be processed whereas sustaining persistently low search latency throughout all the system.
RAG and vector search with Ask Amplitude
Let’s take a short have a look at why Ask Amplitude makes use of RAG. Amplitude collects omnichannel buyer information. Our finish prospects ship information on person actions which might be carried out of their platforms. These actions are recorded as user-generated occasions. For instance, within the case of retail and ecommerce prospects, the forms of person occasions embrace “product search,” “add to cart,” “checked out,” “delivery choice,” “buy,” and extra. These occasions assist outline the shopper’s database schema, outlining the tables, columns, and relationships between them. Let’s contemplate a person query corresponding to “How many individuals used 2-day delivery?” The LLM wants to find out which parts of the captured person occasions are pertinent to formulating an correct response to the question. When customers ask a query to Ask Amplitude, step one is to filter the related occasions from OpenSearch Service. Slightly than feeding all occasion information to the LLM, we take a extra selective strategy for each value and accuracy causes. As a result of LLM utilization is billed based mostly on token rely, sending full occasion information can be unnecessarily costly. Extra importantly, offering an excessive amount of context can degrade the LLM’s efficiency—when confronted with 1000’s of schema parts, the mannequin struggles to reliably establish and give attention to the related data. This data overload can distract the LLM from the core query, probably resulting in hallucinations or inaccurate responses. Because of this RAG is the popular strategy. To retrieve essentially the most related gadgets from the product utilization schema, a vector search is carried out. That is efficient even in conditions when the query won’t seek advice from the precise phrases which might be within the buyer’s schema. The next sections stroll by way of the iterations of Amplitude’s search journey.
Preliminary resolution: No semantic search
We used Amazon Relational Database Service (Amazon RDS) for PostgreSQL as the first database to retailer our folks, occasions, and properties information. Nevertheless, as the next diagram reveals, we had a separate, third-party retailer to implement key phrase search. We had to usher in information from PostgreSQL to this third-party search index and hold it up to date.
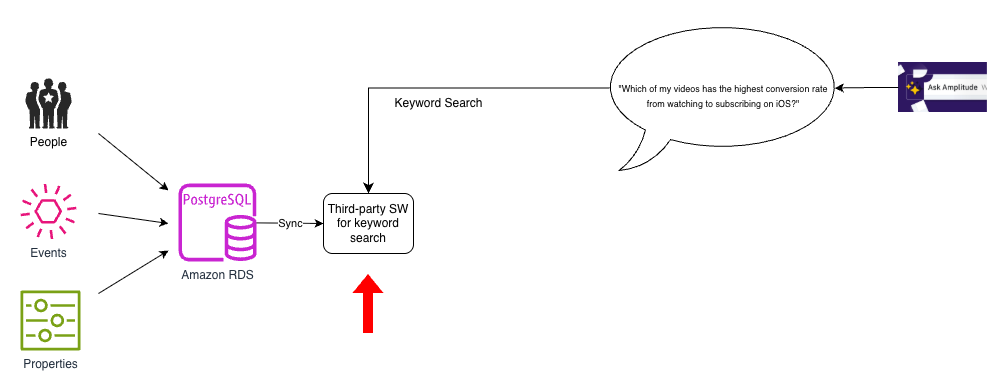
This structure was easy however had two key shortcomings: there have been no pure language capabilities in our search index, and the search index supported solely key phrase search.
Iteration 1: Brute pressure cosine similarity
To enhance our search functionality, we thought of a number of prototypes. As a result of information volumes for many prospects weren’t very massive, it was fast to construct a vector search prototype utilizing PostgreSQL. We remodeled person interplay information into vector embeddings and used array cosine similarity to compute similarity metrics throughout the dataset. This alleviated the necessity for customized similarity computation. The vector embeddings captured nuanced person habits patterns utilizing PostgreSQL capabilities with out extra infrastructure overhead. That is usually known as the brute pressure methodology, the place an incoming question is matched in opposition to all embeddings to search out its prime (Ok) neighbors by a distance measure (cosine similarity on this case). The next diagram illustrates this structure.
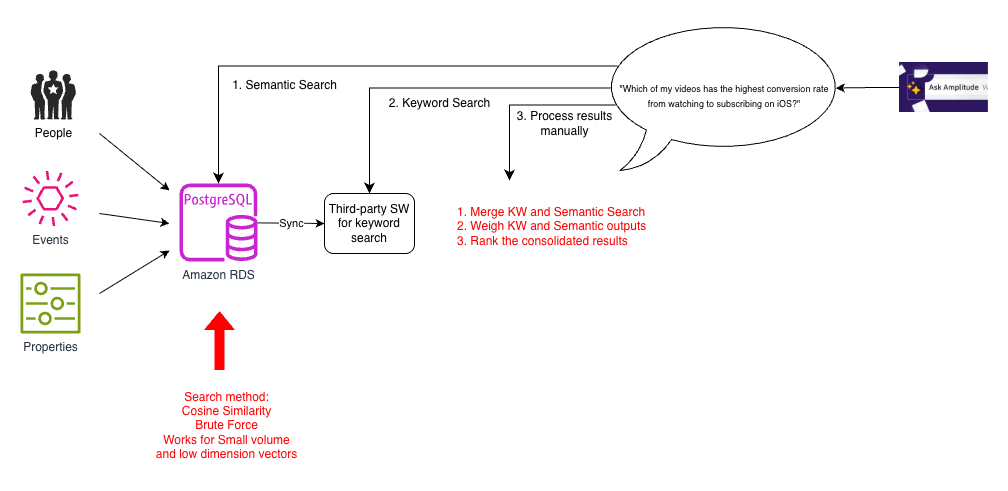
Enabling semantic search was an enormous enchancment over conventional seek for customers who may use totally different phrases to seek advice from the identical ideas, corresponding to “hours of video streamed” or “complete watch time”. Nevertheless, though this labored for small datasets, it was gradual as a result of the brute pressure methodology needed to compute cosine similarity for all pairs of vectors. This was amplified because the variety of parts within the occasions schema, the complexity of questions, and expectations of high quality grew. Moreover, Ask Amplitude solutions wanted to mix each semantic and key phrase search. To assist this, every search question needed to be carried out as a three-step course of involving a number of calls to separate databases:
- Retrieve the semantic search outcomes from PostgreSQL.
- Retrieve the key phrase search outcomes from our search index.
- Within the utility, semantic search outcomes and key phrase search outcomes had been mixed utilizing pre-assigned weights, and this output was dispatched to the Ask Amplitude UI.
This multi-step handbook strategy made the search course of extra complicated.
Iteration 2: ANN search with pgvector
As Amplitude’s buyer base grew, Ask Amplitude wanted to scale to accommodate extra prospects and bigger schemas. The purpose was not simply to reply the query at hand, however to show the person construct an end-to-end evaluation by guiding them iteratively. To this finish, the embeddings wanted to retailer and index contextually wealthy semantic content material. The staff experimented with greater, increased dimensionality embeddings and had anecdotal observations of vector dimensionality showing to influence the effectiveness of the retrieval. One other requirement was to assist multilingual embeddings.
To assist a extra scalable k-NN search, the staff switched to pgvector, a PostgreSQL extension that gives highly effective functionalities for with vectors in high-dimensional area. The next diagram illustrates this structure.
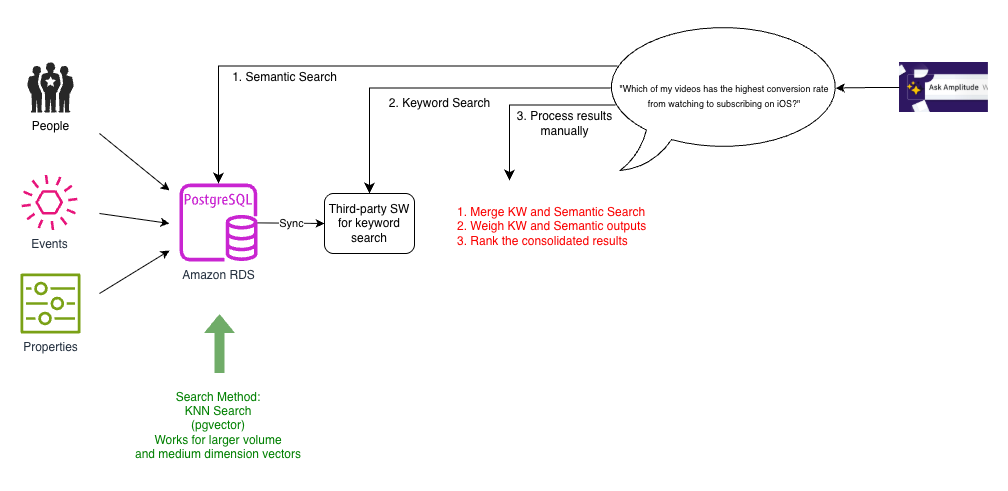
Pgvector was capable of assist k-nearest neighbor (k-NN) similarity seek for bigger dimensionality vectors. Because the variety of vectors grew, we switched to indexes that allowed approximate nearest neighbor (ANN) search, corresponding to HNSW and IVFFlat.
For patrons with bigger schemas, calculating brute pressure cosine similarity was gradual and costly. We discovered a efficiency distinction after we moved to ANN enabled by pgvector. Nevertheless, we nonetheless wanted to take care of the complexity launched by the three-step means of querying PostgreSQL for semantic search, a separate search index for key phrase search, after which stitching all of it collectively.
Iteration 3: Twin sync to key phrase and semantic search with OpenSearch Service
Because the variety of prospects grew, so did the variety of schemas. There have been lots of of tens of millions of schema entries within the database, so we sought a performant, scalable, and cost-effective resolution for k-NN search. We explored OpenSearch Service and Pinecone. We selected OpenSearch Service as a result of we might mix key phrase and vector search capabilities. This was handy for 4 causes:
- Less complicated structure – Positioning semantic search as a functionality in an current search resolution, as we noticed in OpenSearch Service, makes for a less complicated structure than treating it as a separate specialised service.
- Decrease-latency search – The power to successfully set up and catalog search information was elementary to how we generated solutions. Augmenting semantic search to our current pipeline by combining each into one question offered decrease latency querying.
- Diminished want for information synchronization – Preserving the database in sync with the search index was essential to the accuracy and high quality of solutions. With the options that we checked out, we must preserve two synchronization pipelines, one for key phrase search index and the opposite for a semantic search index, complicating the structure and rising the possibilities of experiencing out-of-sync outcomes between key phrase and semantic search outcomes. Synchronizing them into one place was simpler than synchronizing them into a number of locations after which combining the alerts at question time. With a mixed key phrase and vector search capabilities of OpenSearch Service, we now wanted to synchronize just one major database on PostgreSQL with the search index.
- Minimized efficiency influence to supply information updates – We discovered that synchronizing information to a different search index is a posh drawback as a result of our dataset modifications continually. With each new buyer, we had lots of of updates each second. We had to ensure the latency of those updates wasn’t impacted by the sync course of. Collocating search information with vector embeddings obviated the necessity for a number of sync processes. This helped us keep away from extra latency within the major database, because of the sync processes encroaching upon database replace site visitors.
Though our earlier third-party search engine specialised in quick ecommerce search, this wasn’t aligned with Amplitude’s particular wants. By migrating to OpenSearch Service, we simplified our structure by lowering two synchronization processes to 1. We phased out the present search platform step by step. This meant we briefly continued to have two synchronization processes, one with present platform and one other to the mixed key phrase and semantic search index on OpenSearch Service, as proven within the following diagram.
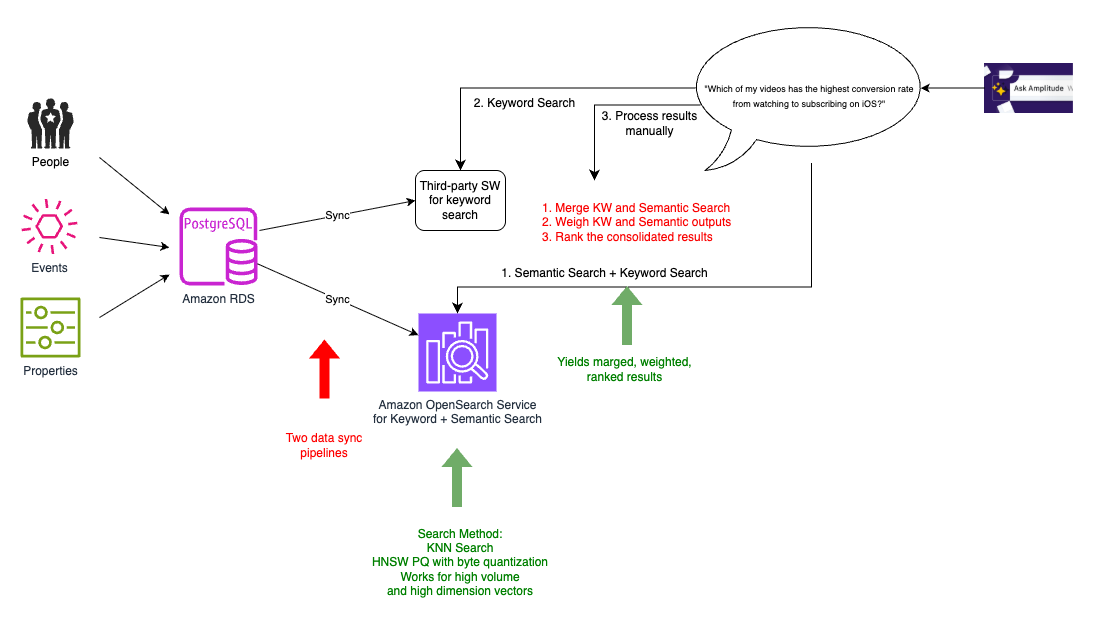
Along with the professionals of k-NN search recognized within the earlier iteration, shifting to OpenSearch Service helped us understand three key advantages:
- Diminished latency – As an alternative of collocating the embeddings with major information, we had been capable of collocate with our search index. The search index is the place our utility wanted to run our queries to select person occasions which might be related to the query being requested and ship this as context despatched to the LLM. As a result of the search textual content, metadata, and embeddings had been multi functional place, we wanted just one hop for all our search necessities, thereby bettering latency.
- Diminished compute energy – We had anyplace between 5,000–20,000 parts within the person occasions schema. We didn’t have to ship all the schema to the LLM, as a result of every person question required solely 20–50 related parts. With the environment friendly filtering capabilities of OpenSearch Service, we had been capable of slender down the vector search area by utilizing tenant-specific metadata, considerably lowering compute necessities throughout our multi-tenant atmosphere.
- Improved scalability – With OpenSearch Service, we might reap the benefits of extra capabilities corresponding to HNSW product quantization (PQ) and byte quantization. Byte quantization made it doable to deal with the dimensions of tens of millions of vector entries with minimal discount in recall, however with enchancment to value and latency.
Nevertheless, on this interim resolution, our information wasn’t totally migrated to OpenSearch Service but. We nonetheless had the previous pipeline together with the brand new pipeline, and needed to carry out twin syncing. This was solely non permanent, as we phased out the previous search index, and the previous pipeline served as a baseline to match with when it comes to efficiency and recall.
Iteration 4: Hybrid search with OpenSearch Service
Within the remaining structure, we had been capable of migrate all our information to OpenSearch Service, which additionally served as our vector database, as proven within the following diagram.
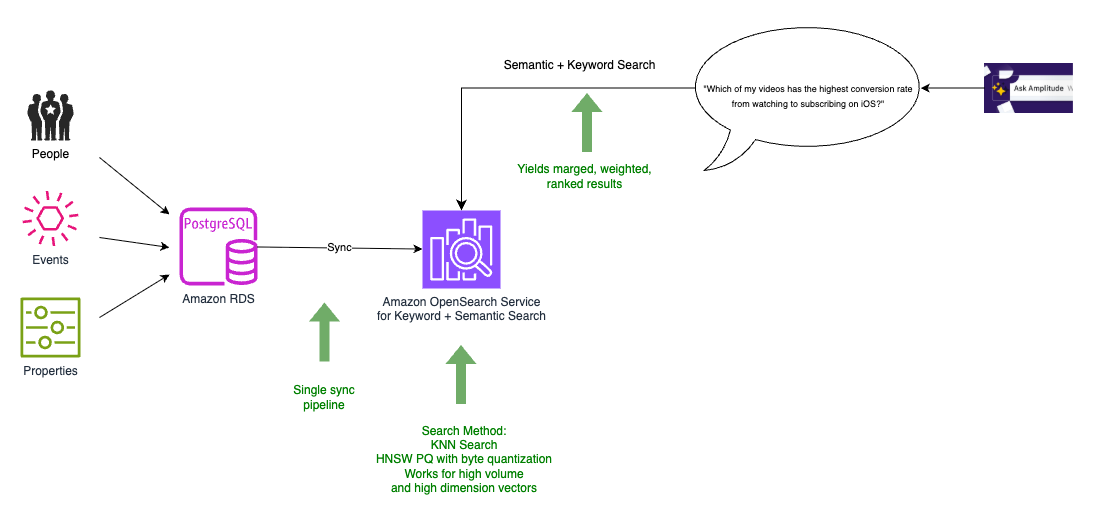
We now needed to carry out only one information synchronization from the PostgreSQL database to the mixed search and vector index, permitting the assets on the database to give attention to transactional site visitors. OpenSearch Service supplies merging, weighting, and rating of the search outcomes as a part of the identical question. This obviated the necessity to implement them as a separate module in our utility, successfully leading to a single, scalable hybrid search (mixed keyword-based (lexical) search and vector-based (semantic) search). With OpenSearch Service, we might additionally experiment with the brand new integration with Amazon Personalize.
Evolving RAG to attract upon user-generated content material
Our prospects needed to ask deeper questions on their product utilization that couldn’t be answered simply by trying on the schema (the construction and names of the information columns) alone. Merely realizing the column names in a database doesn’t essentially reveal the that means, values, or correct interpretation of that information. The schema alone supplies an incomplete image. A naïve strategy can be to index and search all information values as an alternative of looking simply the schema. Amplitude avoids this for scalability causes. The cardinality and quantity of occasion information (probably trillions of occasion information) makes indexing all values value prohibitive. Amplitudes hosts about 20 million charts and dashboards throughout all Amplitude prospects. This user-generated content material is efficacious. We noticed that we will higher perceive the that means and context by analyzing how different customers have beforehand visualized information.For instance, if a person asks about “2-day delivery,” Amplitude first checks if the information schema incorporates columns with related names like “delivery” or “delivery methodology”. If such columns exist, it then examines the potential values in these columns to search out values associated to 2-day delivery. Amplitude additionally searches user-created content material (charts, dashboards, and extra) to see if anybody else on the firm has already visualized information associated to 2-day delivery. If that’s the case, it will possibly use that current chart as a reference for correctly filter and analyze the information to reply the query. To look this content material effectively, Amplitude employs a hybrid strategy combining key phrase and vector similarity (semantic) searches. For tenant isolation and pruning, we use metadata to filter by buyer first, after which vector search.
Conclusion
On this submit, we confirmed you the way Amplitude constructed Ask Amplitude, an AI assistant utilizing OpenSearch Service as a vector database to allow pure language queries of product analytics information. We advanced our system by way of 4 iterations, in the end consolidating key phrase and semantic search into OpenSearch Service, which simplified our structure from a number of sync pipelines to 1, lowered question latency by combining search operations, and enabled environment friendly multi-tenant vector search at scale utilizing options like HNSW PQ and byte quantization. We prolonged the system past schema search to index 20 million user-generated charts and dashboards, utilizing hybrid search to offer richer context for answering buyer questions on product utilization.
As pure language interfaces turn into more and more prevalent, Amplitude’s iterative journey demonstrates the potential for harnessing LLMs and RAG utilizing vector databases corresponding to OpenSearch Service to unlock wealthy conversational buyer experiences. By step by step transitioning to a unified search resolution that mixes key phrase and semantic vector search capabilities, Amplitude overcame scalability and efficiency challenges whereas lowering structure complexity. The ultimate structure utilizing OpenSearch Service enabled environment friendly multi-tenancy and fine-grained entry management and likewise facilitated low-latency hybrid search. Amplitude is ready to ship extra pure and intuitive analytics capabilities to its prospects by producing deeper insights and contextualizing information.
To be taught extra about how Ask Amplitude helps you specific Amplitude-related ideas and questions in pure language, seek advice from Ask Amplitude. To get began with OpenSearch Service as a vector database, seek advice from Amazon OpenSearch Service as a Vector Database.
In regards to the authors