
{kind=link}
Amazon EMR runtime for Apache Spark presents a high-performance runtime atmosphere whereas sustaining API compatibility with open supply Apache Spark and Apache Iceberg desk format. Amazon EMR on EC2, Amazon EMR Serverless, Amazon EMR on Amazon EKS, Amazon EMR on AWS Outposts and AWS Glue use the optimized runtimes.
On this publish, we show the write efficiency advantages of utilizing the Amazon EMR 7.12 runtime for Spark and Iceberg compares to open supply Spark 3.5.6 with Iceberg 1.10.0 tables on a 3TB merge workload.
Write Benchmark Methodology
Our benchmarks show that Amazon EMR 7.12 can run 3TB merge workloads over 2 instances sooner than open supply Spark 3.5.6 with Iceberg 1.10.0, delivering important enhancements for information ingestion and ETL pipelines whereas offering the superior options of Iceberg together with ACID transactions, time journey, and schema evolution.
Benchmark workload
To judge the write efficiency enhancements in Amazon EMR 7.12, we selected a merge workload that displays widespread information ingestion and ETL patterns. The benchmark consists of 37 primary merge operations on TPC-DS 3TB tables, testing the efficiency of INSERT, UPDATE, and DELETE operations. The workload is impressed by established benchmarking approaches from the open supply group, together with Delta Lake’s merge benchmark methodology and the LST-Bench framework. We mixed and tailored these approaches to create a complete check of Iceberg write efficiency on AWS. We additionally began with an preliminary give attention to copy-on-write efficiency solely.
Workload traits
The benchmark executes 37 primary sequential merge queries that modify TPC-DS reality tables. The 37 queries are organized into three classes:
- Inserts (queries m1-m6): Including new data to tables with various information volumes. These queries use supply tables with 5-100% new data and 0 matches, testing pure insert efficiency at completely different scales.
- Upserts (queries m8-m16): Modifying current data whereas inserting new ones. These upsert operations mix completely different ratios of matched and non-matched data—for instance, 1% matches with 10% inserts, or 99% matches with 1% inserts—representing typical eventualities the place information is each up to date and augmented.
- Deletes (queries m7, m17-m37): Eradicating data with various selectivity. These vary from small, focused deletes affecting 5% of recordsdata and rows to large-scale deletions, together with partition-level deletes that may be optimized to metadata-only operations.
The queries function on the desk state created by earlier operations, simulating actual ETL pipelines the place subsequent steps depend upon earlier transformations. For instance, the primary six queries insert between 607,000 and 11.9 million data into the web_returns desk. Later queries then replace and delete from this modified desk, testing read-after-write efficiency. Supply tables have been generated by sampling the TPC-DS web_returns desk with managed match/non-match ratios for constant check situations throughout the benchmark runs.
The merge operations differ in scale and complexity:
- Small operations affecting 607,000 data
- Massive operations modifying over 12 million data
- Selective deletes requiring file rewrites
- Partition-level deletes optimized to metadata operations
Benchmark configuration
We ran the benchmark on an identical {hardware} for each Amazon EMR 7.12 and open supply Spark 3.5.6 with Iceberg 1.10.0:
- Cluster: 9 r5d.4xlarge cases (1 main, 8 employees)
- Compute: 144 whole vCPUs, 1,152 GB reminiscence
- Storage: 2 x 300 GB NVMe SSD per occasion
- Catalog: Hadoop Catalog
- Knowledge format: Parquet recordsdata on Amazon S3
- Desk format: Apache Iceberg (default: copy-on-write mode)
Benchmark outcomes
We in contrast benchmark outcomes for Amazon EMR 7.12 to open supply Spark 3.5.6 and Iceberg 1.10.0. We ran the 37 merge queries in three sequential iterations, and the common runtime throughout these iterations was taken for comparability. The next desk reveals the outcomes averaged throughout three iterations:
| Amazon EMR 7.12 (seconds) | Open Supply Spark 3.5.6 + Iceberg 1.10.0 (seconds) | Speedup |
| 443.58 | 926.63 | 2.08x |
The typical runtime for the three iterations on Amazon EMR 7.12 with Iceberg enabled was 443.58 seconds, demonstrating a 2.08x pace improve in comparison with open supply Spark 3.5.6 and Iceberg 1.10.0. The next determine presents the overall runtimes in seconds.
The next desk summarizes the metrics.
| Metric | Amazon EMR 7.12 on EC2 | Open supply Spark 3.5.6 and Iceberg 1.10.0 |
| Common runtime in seconds | 443.58 | 926.63 |
| Geometric imply over queries in seconds | 6.40746 | 18.50945 |
| Price* | $1.58 | $2.68 |
*Detailed value estimates are mentioned later on this publish.
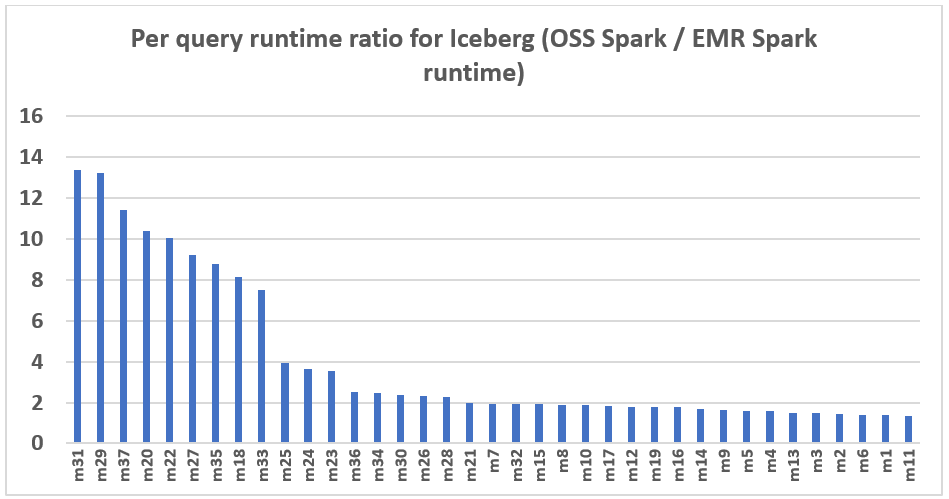
The next chart demonstrates the per-query efficiency enchancment of Amazon EMR 7.12 relative to open supply Spark 3.5.6 and Iceberg 1.10.0. The extent of the speedup varies from one question to a different, with the quickest as much as 13.3 instances sooner for question m31, with Amazon EMR outperforming open supply Spark with Iceberg tables. The horizontal axis arranges the TPC-DS 3TB benchmark queries in descending order primarily based on the efficiency enchancment seen with Amazon EMR, and the vertical axis depicts the magnitude of this speedup as a ratio.
Efficiency optimizations in Amazon EMR
Amazon EMR 7.12 achieves over 2x sooner write efficiency by systematic optimizations throughout the write execution pipeline. These enhancements span a number of areas:
- Metadata-only delete operations: When deleting whole partitions, EMR can now optimize these operations to metadata-only modifications, eliminating the necessity to rewrite information recordsdata. This considerably reduces the time and value for partition-level delete operations.
- Bloom filter joins for merge operations: Enhanced be part of methods utilizing bloom filters cut back the quantity of knowledge that must be learn and processed throughout merge operations, notably benefiting queries with selective predicates.
- Parallel file write out: Optimized parallelism in the course of the write section of merge operations improves throughput when writing filtered outcomes again to Amazon S3, lowering total merge operation time. We balanced the parallelism with learn efficiency for total optimized efficiency on the complete workload.
These optimizations work collectively to ship constant efficiency enhancements throughout various write patterns. The result’s considerably sooner information ingestion and ETL pipeline execution whereas sustaining Iceberg’s ACID assurances and information consistency of Iceberg.
Price comparability
Our benchmark supplies the overall runtime and geometric imply information to evaluate the efficiency of Spark and Iceberg in a posh, real-world resolution assist situation. For added insights, we additionally look at the fee side. We calculate value estimates utilizing formulation that account for EC2 On-Demand cases, Amazon Elastic Block Retailer (Amazon EBS), and Amazon EMR bills.
- Amazon EC2 value (contains SSD value) = variety of cases * r5d.4xlarge hourly fee * job runtime in hours
- 4xlarge hourly fee = $1.152 per hour
- Root Amazon EBS value = variety of cases * Amazon EBS per GB-hourly fee * root EBS quantity measurement * job runtime in hours
- Amazon EMR value = variety of cases * r5d.4xlarge Amazon EMR value * job runtime in hours
- 4xlarge Amazon EMR value = $0.27 per hour
- Complete value = Amazon EC2 value + root Amazon EBS value + Amazon EMR value
The calculations reveal that the Amazon EMR 7.12 benchmark yields a 1.7x value effectivity enchancment over open supply Spark 3.5.6 and Iceberg 1.10.0 in working the benchmark job.
| Metric | Amazon EMR 7.12 | Open supply Spark 3.5.6 and Iceberg 1.10.0 |
| Runtime in seconds | 443.58 | 926.63 |
| Variety of EC2 cases(Consists of main node) | 9 | 9 |
| Amazon EBS Dimension | 20gb | 20gb |
| Amazon EC2(Complete runtime value) | $1.28 | $2.67 |
| Amazon EBS value | $0.00 | $0.01 |
| Amazon EMR value | $0.30 | $0 |
| Complete value | $1.58 | $2.68 |
| Price financial savings | Amazon EMR 7.12 is 1.7 instances higher | Baseline |
Run open supply Spark benchmarks on Iceberg tables
We used separate EC2 clusters, every outfitted with 9 r5d.4xlarge cases, for testing each open supply Spark 3.5.6 and Amazon EMR 7.12 for Iceberg workload. The first node was outfitted with 16 vCPU and 128 GB of reminiscence, and the eight employee nodes collectively had 128 vCPU and 1024 GB of reminiscence. We carried out assessments utilizing the Amazon EMR default settings to showcase the standard person expertise and minimally adjusted the settings of Spark and Iceberg to keep up a balanced comparability.
The next desk summarizes the Amazon EC2 configurations for the first node and eight employee nodes of sort r5d.4xlarge.
| EC2 Occasion | vCPU | Reminiscence (GiB) | Occasion storage (GB) | EBS root quantity (GB) |
| r5d.4xlarge | 16 | 128 | 2 x 300 NVMe SSD | 20 GB |
Benchmarking directions
Observe the steps under to run the benchmark:
- For the open supply run, create a Spark cluster on Amazon EC2 utilizing Flintrock with the configuration described beforehand.
- Setup the TPC-DS supply information with Iceberg in your S3 bucket.
- Construct the benchmark utility jar from the supply to run the benchmarking and get the outcomes.
Detailed directions are supplied within the emr-spark-benchmark GitHub repository.
Summarize the outcomes
After the Spark job finishes, retrieve the check outcome file from the output S3 bucket at s3://. This may be executed both by the Amazon S3 console by navigating to the required bucket location or through the use of the Amazon Command Line Interface (AWS CLI). The Spark benchmark utility organizes the info by making a timestamp folder and putting a abstract file inside a folder labeled abstract.csv. The output CSV recordsdata comprise 4 columns with out headers:
- Question title
- Median time
- Minimal time
- Most time
With the info from three separate check runs with one iteration every time, we will calculate the common and geometric imply of the benchmark runtimes.
Clear up
To assist forestall future fees, delete the sources you created by following the directions supplied within the Cleanup part of the GitHub repository.
Abstract
Amazon EMR is constantly enhancing the EMR runtime for Spark when used with Iceberg tables, reaching write efficiency that’s over 2 instances sooner than open supply Spark 3.5.6 and Iceberg 1.10.0 with EMR 7.12 on 3TB merge workloads. This represents a major enchancment for information ingestion and ETL pipelines, serving to to ship 1.7x value discount whereas sustaining the ACID assurances of Iceberg. We encourage you to maintain updated with the newest Amazon EMR releases to totally profit from ongoing efficiency enhancements.
To remain knowledgeable, subscribe to the RSS feed for the AWS Large Knowledge Weblog, the place you could find updates on the EMR runtime for Spark and Iceberg, in addition to recommendations on configuration greatest practices and tuning suggestions.
In regards to the authors
 Atul Felix Payapilly is a software program improvement engineer for Amazon EMR at Amazon Internet Providers.
Atul Felix Payapilly is a software program improvement engineer for Amazon EMR at Amazon Internet Providers.
 Akshaya KP is a software program improvement engineer for Amazon EMR at Amazon Internet Providers.
Akshaya KP is a software program improvement engineer for Amazon EMR at Amazon Internet Providers.
 Hari Kishore Chaparala is a software program improvement engineer for Amazon EMR at Amazon Internet Providers.
Hari Kishore Chaparala is a software program improvement engineer for Amazon EMR at Amazon Internet Providers.
 Giovanni Matteo is the Senior Supervisor for the Amazon EMR Spark and Iceberg group.
Giovanni Matteo is the Senior Supervisor for the Amazon EMR Spark and Iceberg group.