
{kind=link}
Deep studying fashions are primarily based on activation features that present non-linearity and allow networks to be taught sophisticated patterns. This text will focus on the Softplus activation operate, what it’s, and the way it may be utilized in PyTorch. Softplus will be mentioned to be a clean type of the favored ReLU activation, that mitigates the drawbacks of ReLU however introduces its personal drawbacks. We are going to focus on what Softplus is, its mathematical system, its comparability with ReLU, what its benefits and limitations are and take a stroll by some PyTorch code using it.
What’s Softplus Activation Perform?
Softplus activation operate is a non-linear operate of neural networks and is characterised by a clean approximation of the ReLU operate. In simpler phrases, Softplus acts like ReLU in instances when the constructive or unfavourable enter could be very massive, however a pointy nook on the zero level is absent. As an alternative, it rises easily and yields a marginal constructive output to unfavourable inputs as an alternative of a agency zero. This steady and differentiable conduct implies that Softplus is steady and differentiable all over the place in distinction to ReLU which is discontinuous (with a pointy change of slope) at x = 0.
Why is Softplus used?
Softplus is chosen by builders that want a extra handy activation that gives. non-zero gradients additionally the place ReLU would in any other case be inactive. Gradient-based optimization will be spared main disruptions attributable to the smoothness of Softplus (the gradient is shifting easily as an alternative of stepping). It additionally inherently clips outputs (as ReLU does) but the clipping is to not zero. In abstract, Softplus is the softer model of ReLU: it’s ReLU-like when the worth is massive however is best round zero and is good and clean.
Softplus Mathematical System
The Softplus is mathematically outlined to be:
When x is massive, ex could be very massive and subsequently, ln(1 + ex) is similar to ln(ex), equal to x. It implies that Softplus is sort of linear at massive inputs, corresponding to ReLU.
When x is massive and unfavourable, ex could be very small, thus ln(1 + ex) is sort of ln(1), and that is 0. The values produced by Softplus are near zero however by no means zero. To tackle a worth that’s zero, x should strategy unfavourable infinity.
One other factor that’s helpful is that the by-product of Softplus is the sigmoid. The by-product of ln(1 + ex) is:
ex / (1 + ex)
That is the very sigmoid of x. It implies that at any second, the slope of Softplus is sigmoid(x), that’s, it has a non-zero gradient all over the place and is clean. This renders Softplus helpful in gradient-based studying because it doesn’t have flat areas the place the gradients vanish.
Utilizing Softplus in PyTorch
PyTorch supplies the activation Softplus as a local activation and thus will be simply used like ReLU or another activation. An instance of two easy ones is given beneath. The previous makes use of Softplus on a small variety of take a look at values, and the latter demonstrates how you can insert Softplus right into a small neural community.
Softplus on Pattern Inputs
The snippet beneath applies nn.Softplus to a small tensor so you’ll be able to see the way it behaves with unfavourable, zero, and constructive inputs.
import torch
import torch.nn as nn
# Create the Softplus activation
softplus = nn.Softplus() # default beta=1, threshold=20
# Pattern inputs
x = torch.tensor([-2.0, -1.0, 0.0, 1.0, 2.0])
y = softplus(x)
print("Enter:", x.tolist())
print("Softplus output:", y.tolist())
What this reveals:
- At x = -2 and x = -1, the worth of Softplus is small constructive values somewhat than 0.
- The output is roughly 0.6931 at x =0, i.e. ln(2)
- In case of constructive inputs corresponding to 1 or 2, the outcomes are a little bit greater than the inputs since Softplus smoothes the curve. Softplus is approaching x because it will increase.
The Softplus of PyTorch is represented by the system ln(1 + exp(betax)). Its inside threshold worth of 20 is to forestall a numerical overflow. Softplus is linear in massive betax, that means that in that case of PyTorch merely returns x.
Utilizing Softplus in a Neural Community
Right here is an easy PyTorch community that makes use of Softplus because the activation for its hidden layer.
import torch
import torch.nn as nn
class SimpleNet(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
tremendous(SimpleNet, self).__init__()
self.fc1 = nn.Linear(input_size, hidden_size)
self.activation = nn.Softplus()
self.fc2 = nn.Linear(hidden_size, output_size)
def ahead(self, x):
x = self.fc1(x)
x = self.activation(x) # apply Softplus
x = self.fc2(x)
return x
# Create the mannequin
mannequin = SimpleNet(input_size=4, hidden_size=3, output_size=1)
print(mannequin)
Passing an enter by the mannequin works as common:
x_input = torch.randn(2, 4) # batch of two samples
y_output = mannequin(x_input)
print("Enter:n", x_input)
print("Output:n", y_output)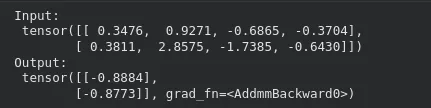
On this association, Softplus activation is used in order that the values exited within the first layer to the second layer are non-negative. The alternative of Softplus by an present mannequin might not want another structural variation. It’s only essential to do not forget that Softplus is likely to be a little bit slower in coaching and require extra computation than ReLU.
The ultimate layer may additionally be applied with Softplus when there are constructive values {that a} mannequin ought to generate as outputs, e.g. scale parameters or constructive regression aims.
Softplus vs ReLU: Comparability Desk
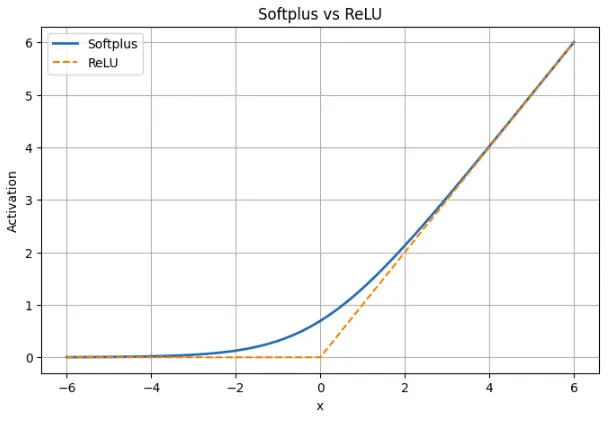
| Facet | Softplus | ReLU |
|---|---|---|
| Definition | f(x) = ln(1 + ex) | f(x) = max(0, x) |
| Form | Clean transition throughout all x | Sharp kink at x = 0 |
| Habits for x < 0 | Small constructive output; by no means reaches zero | Output is precisely zero |
| Instance at x = -2 | Softplus ≈ 0.13 | ReLU = 0 |
| Close to x = 0 | Clean and differentiable; worth ≈ 0.693 | Not differentiable at 0 |
| Habits for x > 0 | Virtually linear, intently matches ReLU | Linear with slope 1 |
| Instance at x = 5 | Softplus ≈ 5.0067 | ReLU = 5 |
| Gradient | At all times non-zero; by-product is sigmoid(x) | Zero for x < 0, undefined at 0 |
| Threat of lifeless neurons | None | Doable for unfavourable inputs |
| Sparsity | Doesn’t produce actual zeros | Produces true zeros |
| Coaching impact | Steady gradient movement, smoother updates | Easy however can cease studying for some neurons |
An analog of ReLU is softplus. It’s ReLU with very massive constructive or unfavourable inputs however with the nook at zero eliminated. This prevents lifeless neurons because the gradient doesn’t go to a zero. This comes on the value that Softplus doesn’t generate true zeros that means that it’s not as sparse as ReLU. Softplus supplies extra comfy coaching dynamics within the observe, however ReLU continues to be used as a result of it’s quicker and less complicated.
Advantages of Utilizing Softplus
Softplus has some sensible advantages that render it to be helpful in some fashions.
- All over the place clean and differentiable
There aren’t any sharp corners in Softplus. It’s solely differentiable to each enter. This assists in sustaining gradients that will find yourself making optimization a little bit simpler for the reason that loss varies slower.
- Avoids lifeless neurons
ReLU can forestall updating when a neuron constantly will get unfavourable enter, because the gradient will probably be zero. Softplus doesn’t give the precise zero worth on unfavourable numbers and thus all of the neurons stay partially energetic and are up to date on the gradient.
- Reacts extra favorably to unfavourable inputs
Softplus doesn’t throw out the unfavourable inputs by producing a zero worth as ReLU does however somewhat generates a small constructive worth. This permits the mannequin to retain part of info of unfavourable indicators somewhat than dropping all of it.
Concisely, Softplus maintains gradients flowing, prevents lifeless neurons and provides clean conduct for use in some architectures or duties the place continuity is essential.
Limitations and Commerce-offs of Softplus
There are additionally disadvantages of Softplus that prohibit the frequency of its utilization.
- Costlier to compute
Softplus makes use of exponential and logarithmic operations which can be slower than the easy max(0, x) of ReLU. This extra overhead will be visibly felt on massive fashions as a result of ReLU is extraordinarily optimized on most {hardware}.
- No true sparsity
ReLU generates excellent zeroes on unfavourable examples, which might save computing time and sometimes assist in regularization. Softplus doesn’t give an actual zero and therefore all of the neurons are all the time not inactive. This eliminates the chance of lifeless neurons in addition to the effectivity benefits of sparse activations.
- Step by step decelerate the convergence of deep networks
ReLU is usually used to coach deep fashions. It has a pointy cutoff and linear constructive area which might pressure studying. Softplus is smoother and might need gradual updates significantly in very deep networks the place the distinction between layers is small.
To summarize, Softplus has good mathematical properties and avoids points like lifeless neurons, however these advantages don’t all the time translate to higher ends in deep networks. It’s best utilized in instances the place smoothness or constructive outputs are essential, somewhat than as a common alternative for ReLU.
Conclusion
Softplus supplies clean, comfortable options of ReLU to the neural networks. It learns gradients, doesn’t kill neurons and is absolutely differentiable all through the inputs. It’s like ReLU at massive values, however at zero, behaves extra like a relentless than ReLU as a result of it produces non-zero output and slope. In the meantime, it’s related to trade-offs. It is usually slower to compute; it additionally doesn’t generate actual zeros and will not speed up studying in deep networks as rapidly as ReLU. Softplus is simpler in fashions, the place gradients are clean or the place constructive outputs are necessary. In most different situations, it’s a helpful different to a default alternative of ReLU.
Often Requested Questions
A. Softplus prevents lifeless neurons by protecting gradients non-zero for all inputs, providing a clean different to ReLU whereas nonetheless behaving equally for big constructive values.
A. It’s a sensible choice when your mannequin advantages from clean gradients or should output strictly constructive values, like scale parameters or sure regression targets.
A. It’s slower to compute than ReLU, doesn’t create sparse activations, and may result in barely slower convergence in deep networks.
Hello, I’m Janvi, a passionate knowledge science fanatic at the moment working at Analytics Vidhya. My journey into the world of information started with a deep curiosity about how we are able to extract significant insights from complicated datasets.
Login to proceed studying and revel in expert-curated content material.